ボードゲームのザマインドのオンラインゲームを作ってみました。
こちらのページです。
Webブラウザで動作します。
自前のサーバで構築したGitLabでCI/CDを動かしたい場合はGitLab Runnerをインストールする必要がある。自分のGitLabサーバにGitLab Runnerをインストールする機会があったのでここに備忘録として残しておく。
事前に以下の手順で設定情報をメモしておく。この情報はRunnerの設定時に利用する。
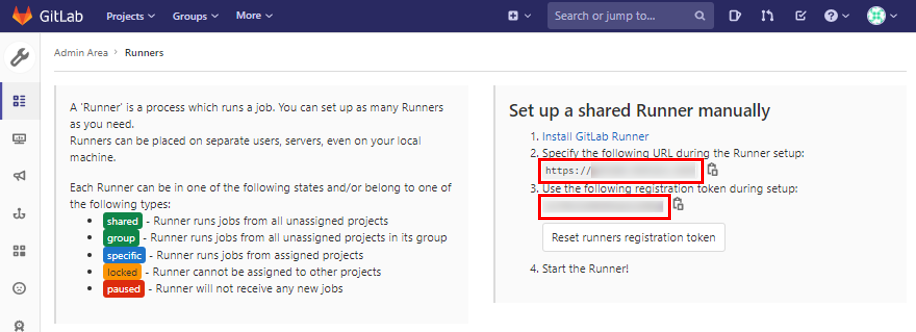
ここからインストール、設定、起動の作業をする。GitLab RunnerサーバにSSHログインしrootアカウントになっておく。
今回はExecutor(CI/CDのjobを実行する実行環境)にDockerを採用するため、先にDockerをインストールし起動しておく。
curl -O https://download.docker.com/linux/centos/7/x86_64/stable/Packages/containerd.io-1.2.13-3.2.el7.x86_64.rpm
dnf install -y containerd.io-1.2.13-3.2.el7.x86_64.rpm
dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
dnf install -y docker-ce docker-ce-cli
systemctl start docker
systemctl enable dockerCentOS8のDockerではコンテナが名前解決のためホストと同じDNSサーバに問い合わせし、Firewallを起動している場合はIP到達性がなくなるためネットワークのエラーが発生してしまう。こちらの記事に載せられていた対策を実施する。
firewall-cmd --add-masquerade --permanent
firewall-cmd --reload公式サイトを参考にした。
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.rpm.sh | bash
dnf -y install gitlab-runner公式サイトを参考にした。以下のコマンドを実行して対話形式で情報を入力していく。
gitlab-runner registerPlease enter the gitlab-ci coordinator URL (e.g. https://gitlab.com/):
https://xxxx.xxxx.xxxx/(ここに先ほどメモしたURLを貼り付ける)Please enter the gitlab-ci token for this runner:
xxxxxxxxxxxxxx(ここに先ほどメモしたトークンを貼り付ける)Please enter the gitlab-ci description for this runner:
[GitLab]: my-runner(この名前がRunner一覧ページに表示される)Please enter the gitlab-ci tags for this runner (comma separated):
(指定しなくてもよい)Please enter the executor: parallels, shell, ssh, kubernetes, custom, docker, docker-ssh, virtualbox, docker+machine, docker-ssh+machine:
docker(Executorはdockerにする)Please enter the default Docker image (e.g. ruby:2.6):
alpine:latest(デフォルトにしたいDockerイメージを指定する)以下のコマンドでサービスが起動しているか確認できる。
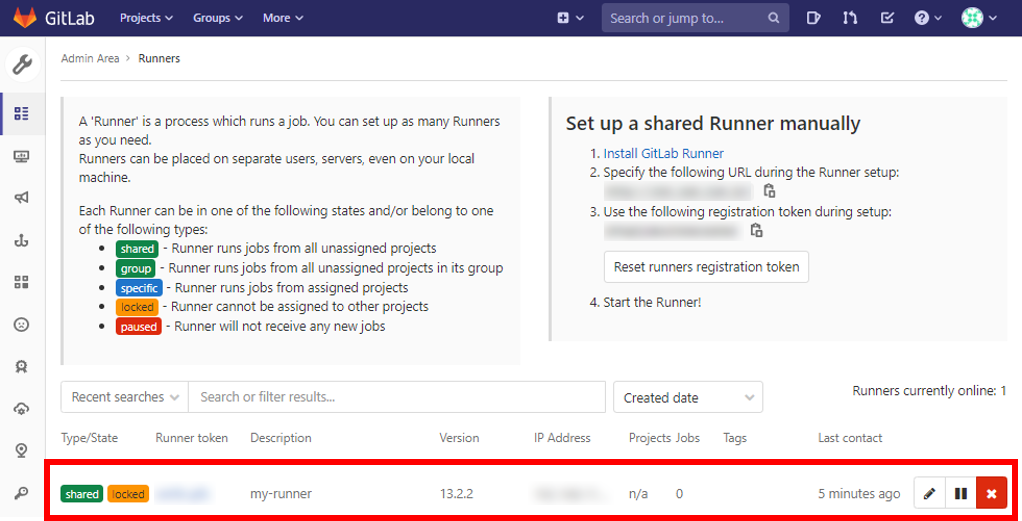
systemctl status gitlab-runnerGitLabのWebページにrootアカウントでAdmin Areaにアクセスし、Runner一覧で今設定したのが登録されていることを確認する。
簡単なPipelineを書いてRunnerを動かしてみる。
GitLabのページからテスト用リポジトリを作成する。下の図では「runner-test」というリポジトリを作成している。
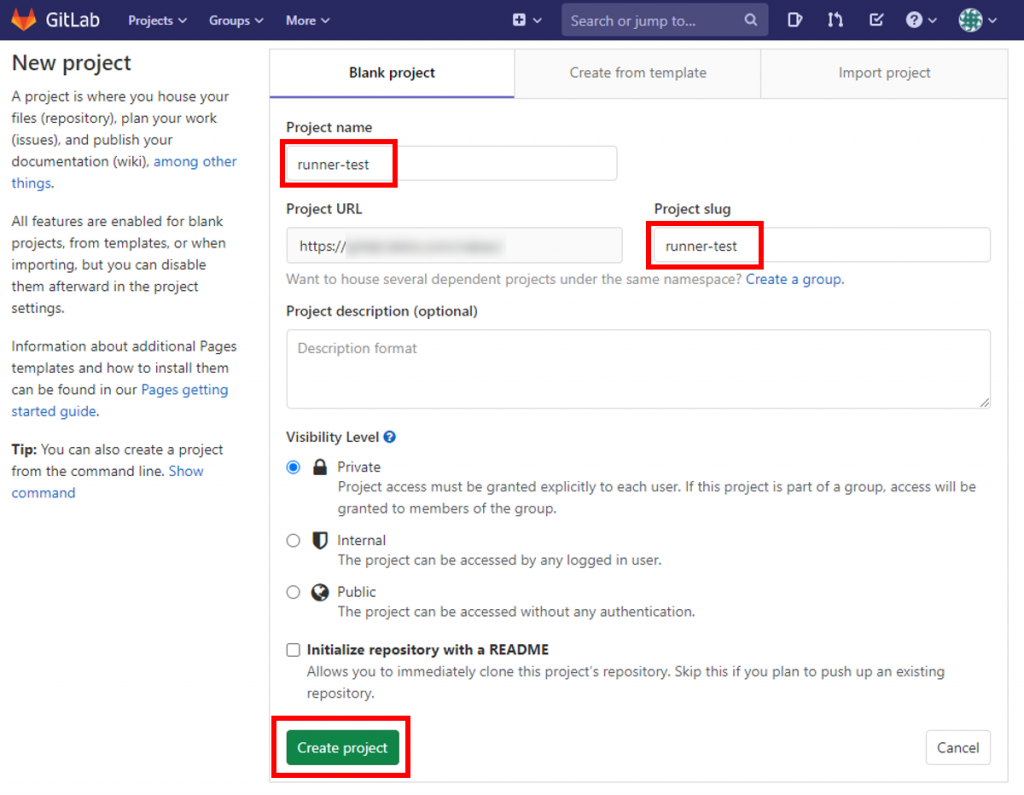
ブラウザでファイル作成、編集する便利機能があるのでそれを使ってみる。下の図の「New file」をクリックする。
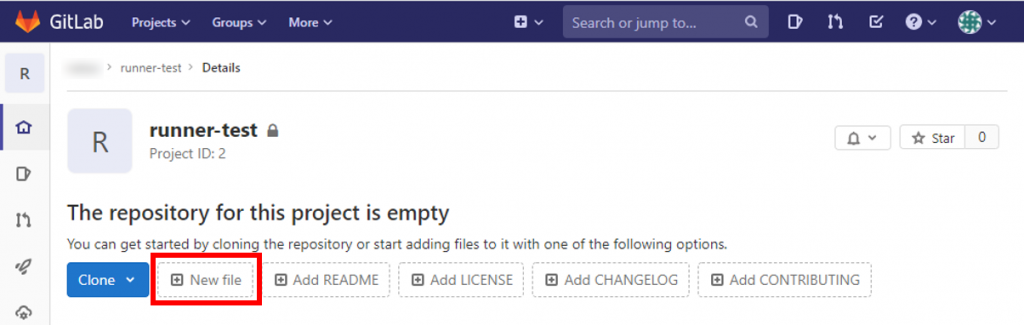
「Select a template type」から「.gitlab-ci.yml」を選択
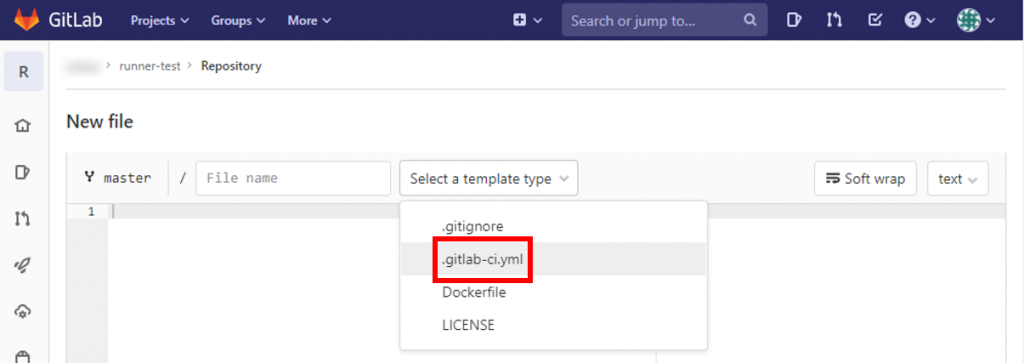
「Apply a template」から「Bash」を選択
「Commit changes」をクリックして、 .gitlab-ci.yml ファイルをリポジトリに追加する。
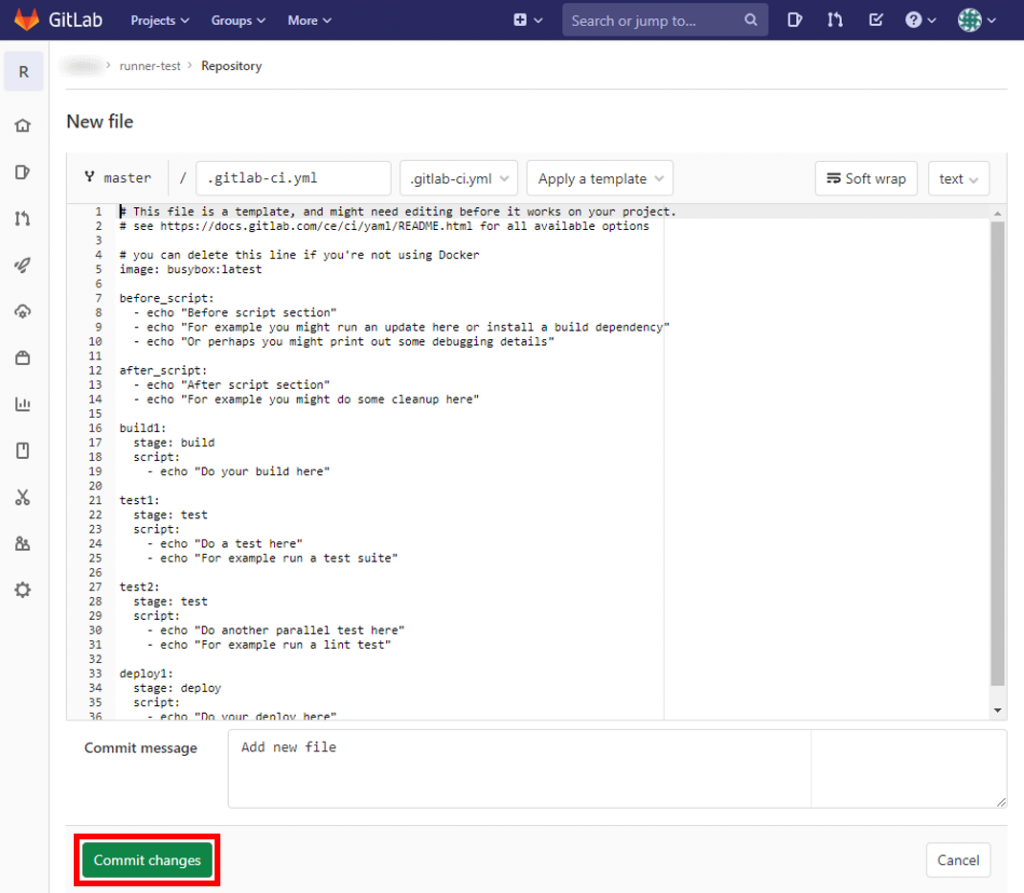
左メニューから「CI/CD」をクリックし、先ほどのcommitでパイプラインが実行されていることを確認する。(「Status」が「running」になっている)
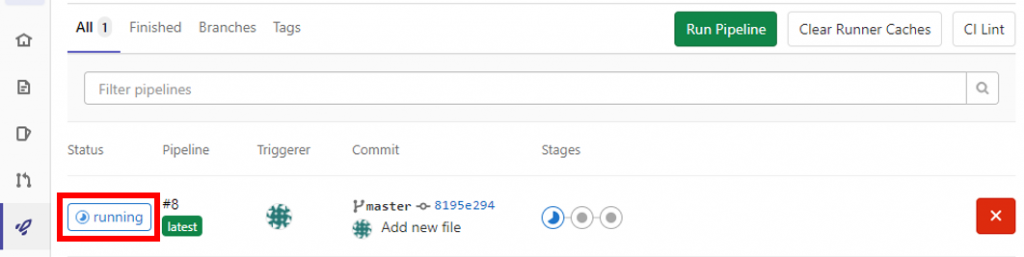
しばらく待って「Status」が「passed」になればOK
AzureでCentOS8の仮想マシンを構築する方法
まずはAzureのポータルにアクセスする。
トップページ左上の三本線をクリック
「Virtual Machines」をクリック
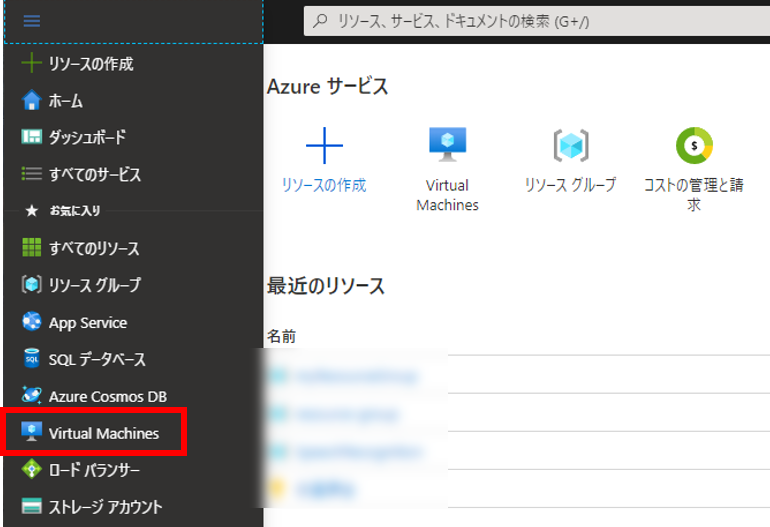
「+追加」をクリック
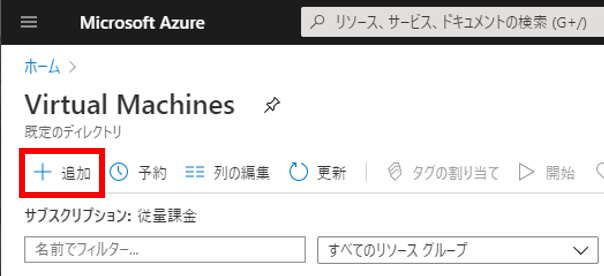
以下の情報を入力または選択し、「確認および作成」をクリック
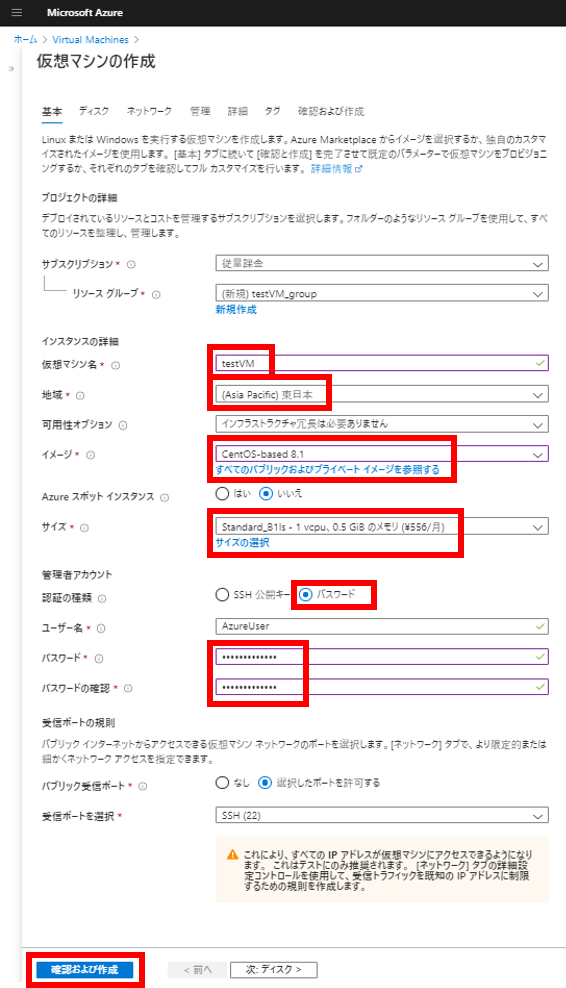
確認ページが表示されるので問題なければ「作成」をクリック
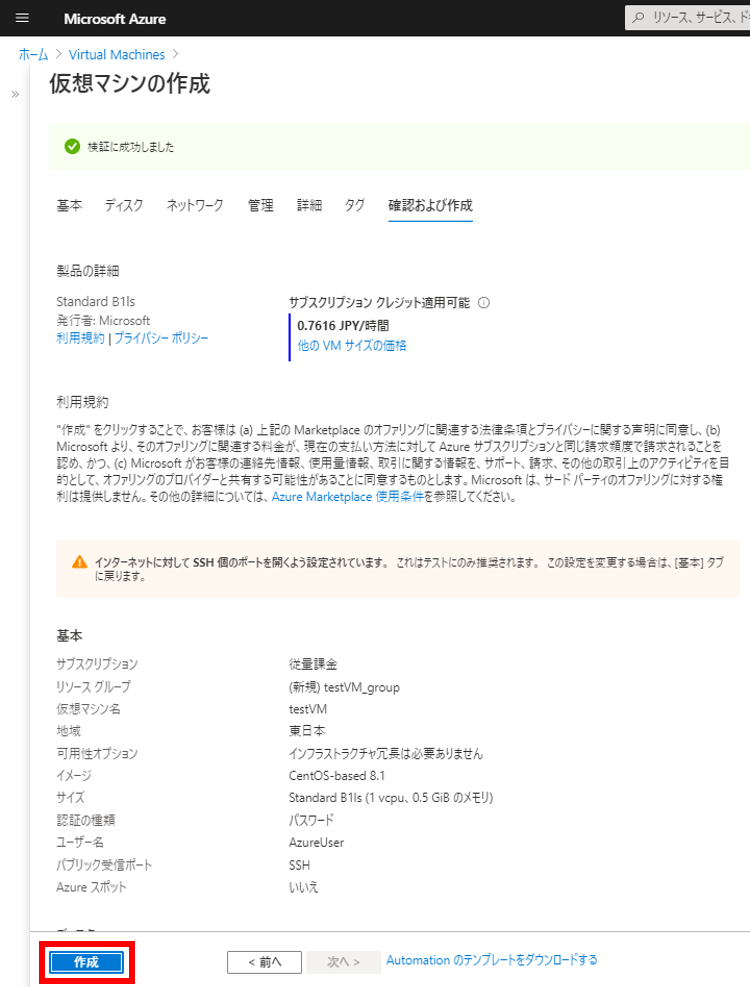
デプロイが完了するまで待つ
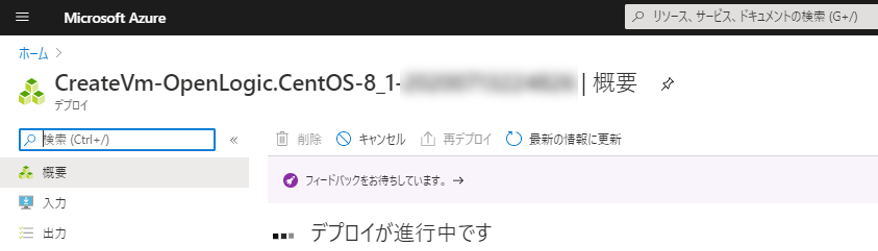
デプロイが完了したら「リソースに移動」をクリック
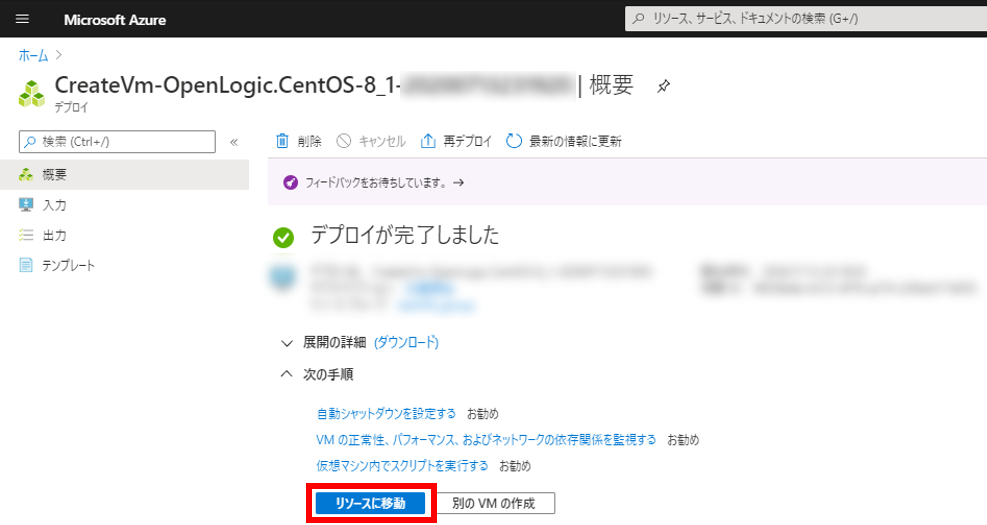
「パブリックIPアドレス」をコピー
何かしらのSSHクライアントでログイン(下の図はPowerShell)
ssh AzureUser@(Public IP address)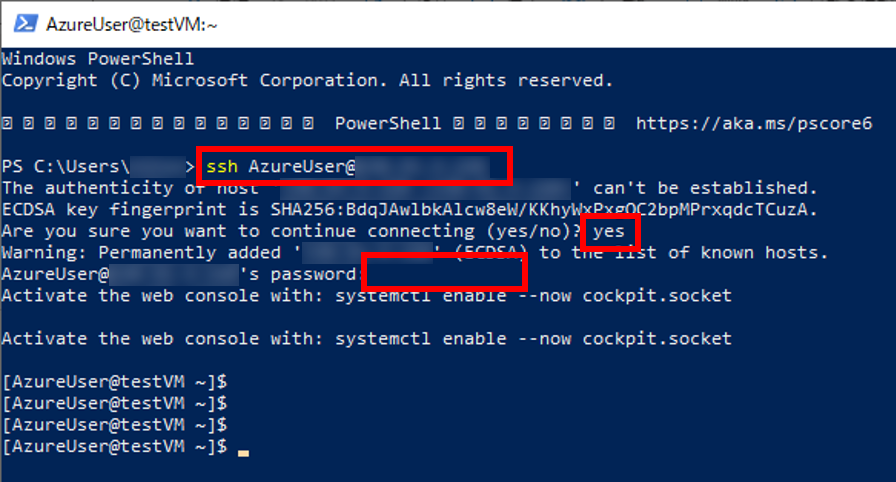
ログインできた。
このままだとどこからでもSSHログインできてしまうので、IPアドレスで制限する方法を載せておく。
仮想マシンのページから「ネットワーク」をクリックし、名前が「SSH」の行をクリック
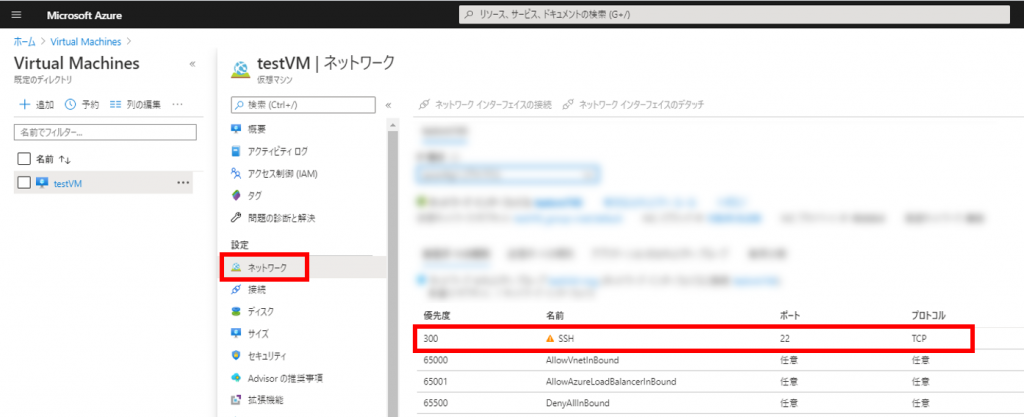
以下の情報を入力し「保存」をクリック
検証用途の場合、リソースを削除することを忘れずに。
仮想マシンを作ると他にもリソースが勝手に作られるのでリソースグループごと消すのが安心。
トップページ左上の三本線をクリックし、「リソースグループ」をクリック
今回作成したリソースグループ(今回は「testVM_group」)をクリック
「リソースグループの削除」をクリック
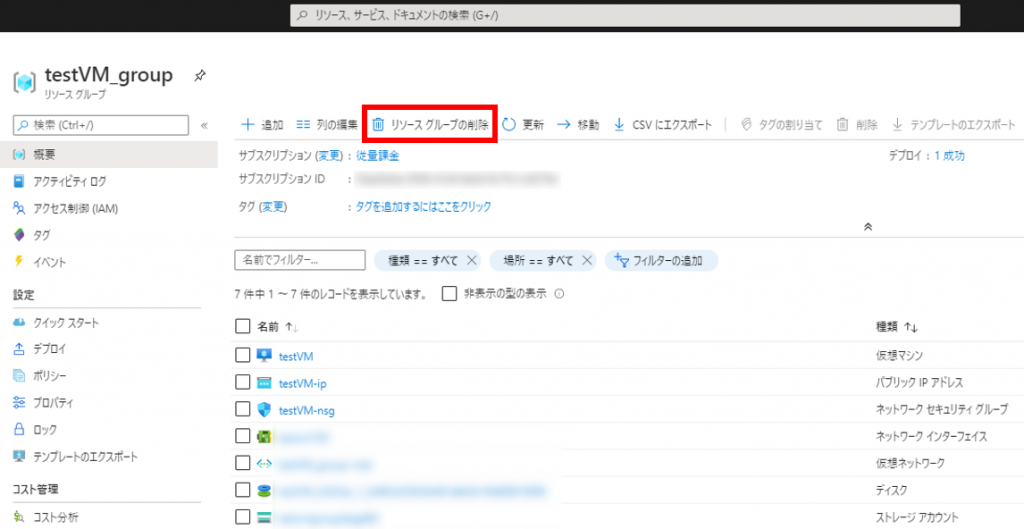
削除確認があるのでテキストボックスにリソースグループ名を入力して「削除」をクリック
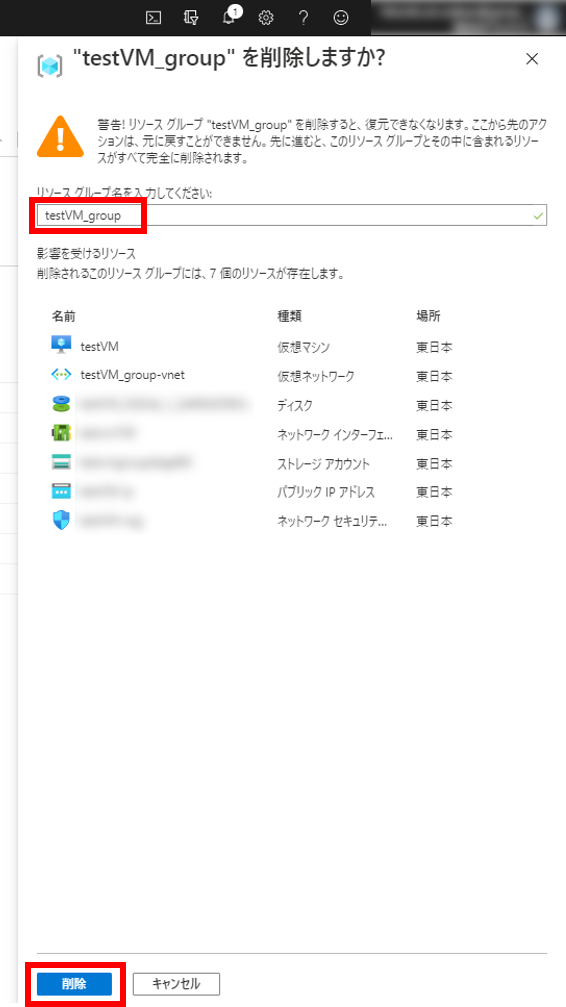
これで今回作成した仮想マシンに関連するリソースがすべて削除される。
公式サイトのチュートリアルをMySQLで実現してみたのでその記録
docker-compose.yml を作成し、以下の内容を記載する。
(今回は検証なのでパスワードは一律で password にしておく)
version: '3'
services:
db:
image: mariadb:10
command: mysqld --character-set-server=utf8 --collation-server=utf8_general_ci
environment:
MYSQL_DATABASE: todoapi
MYSQL_USER: todoapi
MYSQL_PASSWORD: password
MYSQL_ROOT_PASSWORD: password
ports:
- "3306:3306"以下のコマンドを実行し、MySQLサービスを起動しておく。
docker-compose up -d以下のコマンドで起動しているか確認できる。
> docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------
todoapi_db_1 docker-entrypoint.sh mysql ... Up 0.0.0.0:3306->3306/tcpここは公式サイト通り
[ファイル] -> [新規作成] -> [プロジェクト][ASP.NET Core Webアプリケーション] を選択して [次へ] をクリック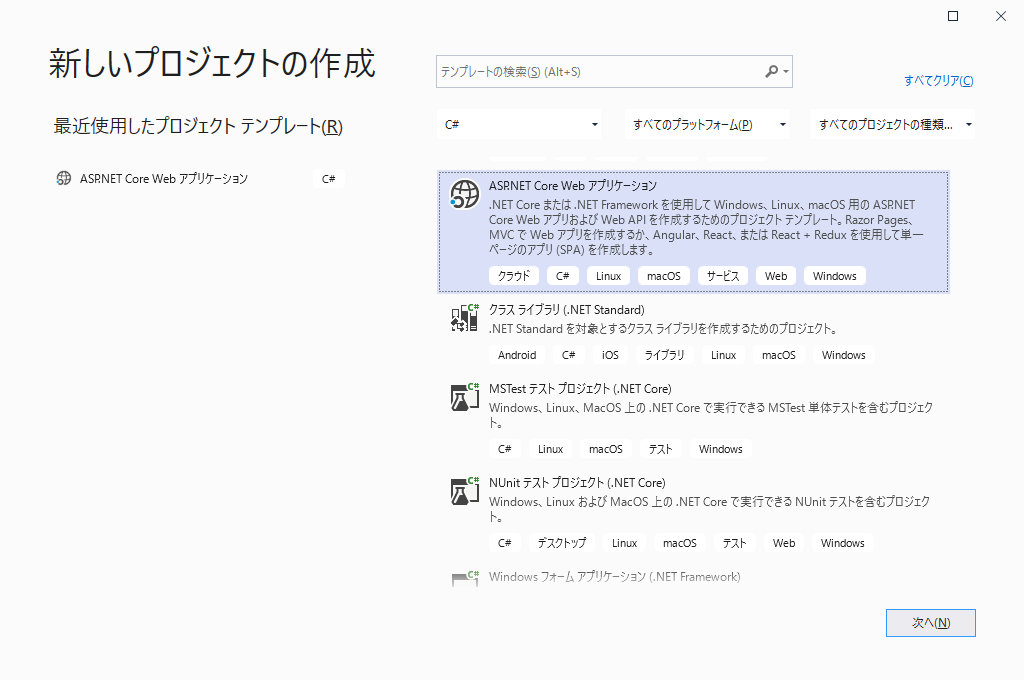
TodoApi と入力して [作成] をクリック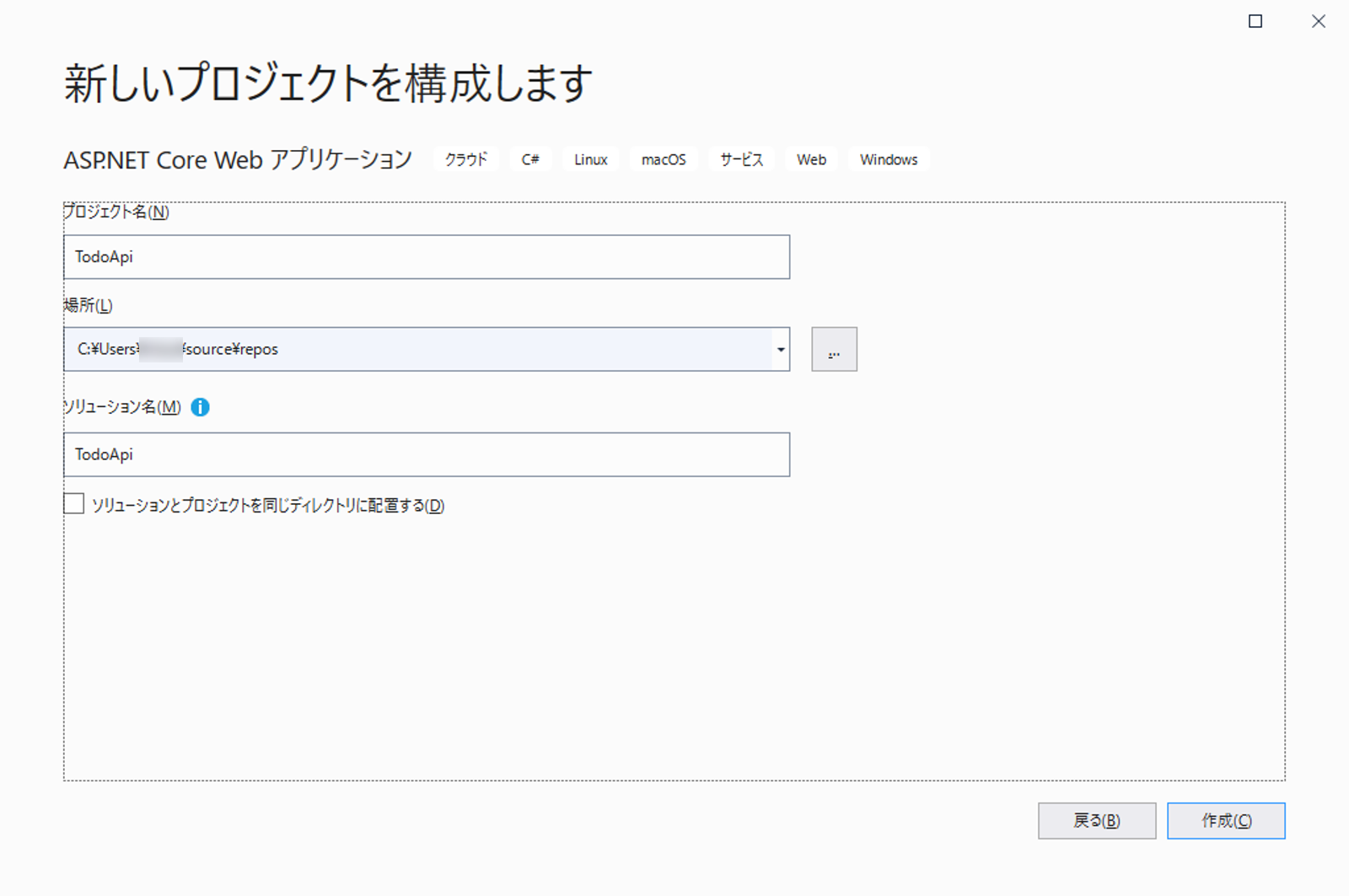
[新しいASP.NET Core Webアプリケーションの作成] ダイアログで [.NET Core] と [ASP.NET Core 3.1] が選択されていることを確認[API] テンプレートを選択して [作成] をクリック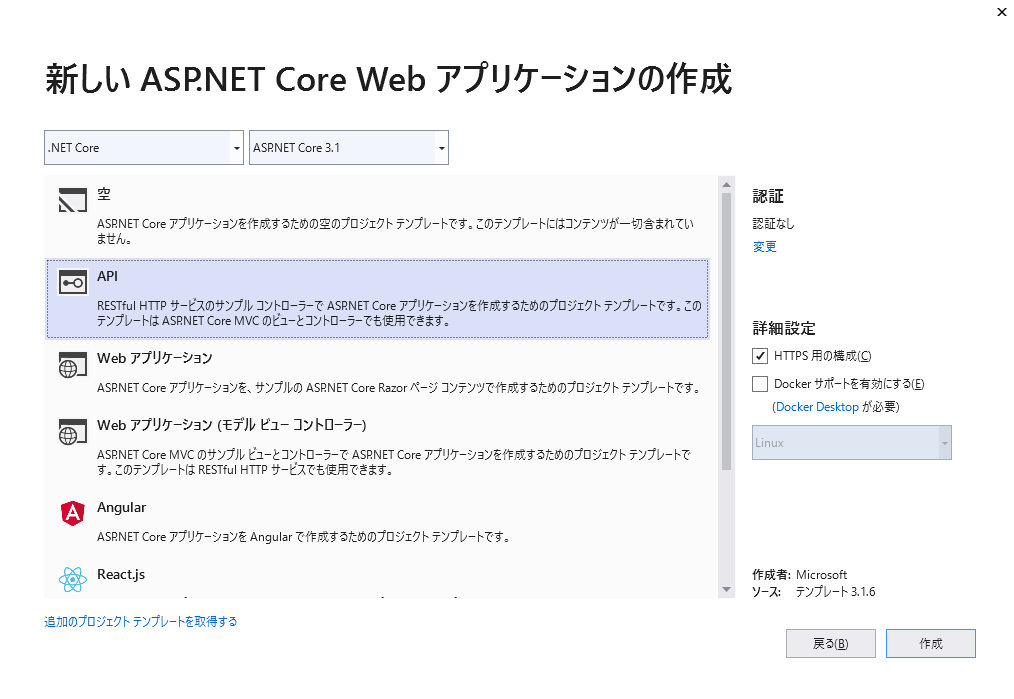
ここも公式サイト通り
Models フォルダを作成Models フォルダ直下に TodoItem クラスを作成TodoItem クラスに以下のコードを追加public class TodoItem
{
public long Id { get; set; }
public string Name { get; set; }
public bool IsComplete { get; set; }
}公式サイトではSQLServerをインストールするが、今回はMySQLをインストールする。
[ツール] -> [NuGetパッケージマネージャー] -> [ソリューションのNuGetパッケージの管理][参照] タブを選択し、検索ボックスに Pomelo.EntityFrameworkCore.MySql と入力[Pomelo.EntityFrameworkCore.MySql] を選択[プロジェクト] チェックボックスをオンにして [インストール] をクリック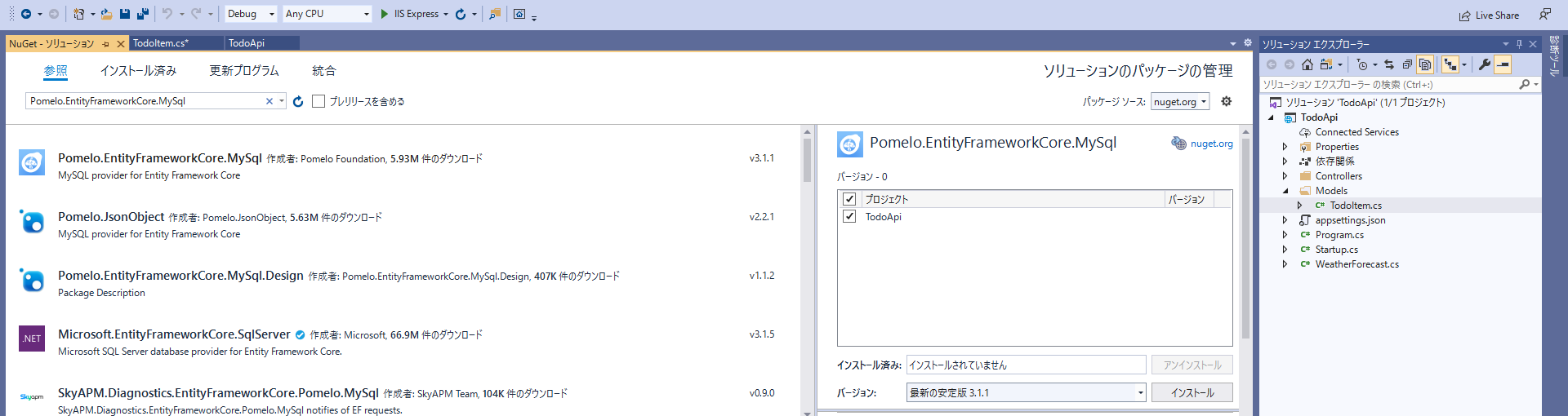
ここは公式サイト通り
Models フォルダ直下に TodoContext クラスを作成TodoContext クラスに以下のコードを追加using Microsoft.EntityFrameworkCore;
namespace TodoApi.Models
{
public class TodoContext : DbContext
{
public TodoContext(DbContextOptions<TodoContext> options)
: base(options)
{
}
public DbSet<TodoItem> TodoItems { get; set; }
}
}データベース接続情報を記載するため、公式サイトとは異なる設定をする。
appsettings.json を編集して以下を追加 "ConnectionStrings": {
"MySQL": "Server=127.0.0.1;Database=todoapi;User=todoapi;Password=password;"
}Startup.cs を編集して以下を追加using Microsoft.EntityFrameworkCore;
using TodoApi.Models;
(中略)
public void ConfigureServices(IServiceCollection services)
{
services.AddDbContext<TodoContext>(opt =>
opt.UseMySql(Configuration.GetConnectionString("MySQL")));
services.AddControllers();
}公式サイト通り
Controllers フォルダを右クリック[追加] -> [新規スキャフォールディングアイテム][Entity Frameworkを使用したアクションがあるAPIコントローラー] を選択して [追加] をクリック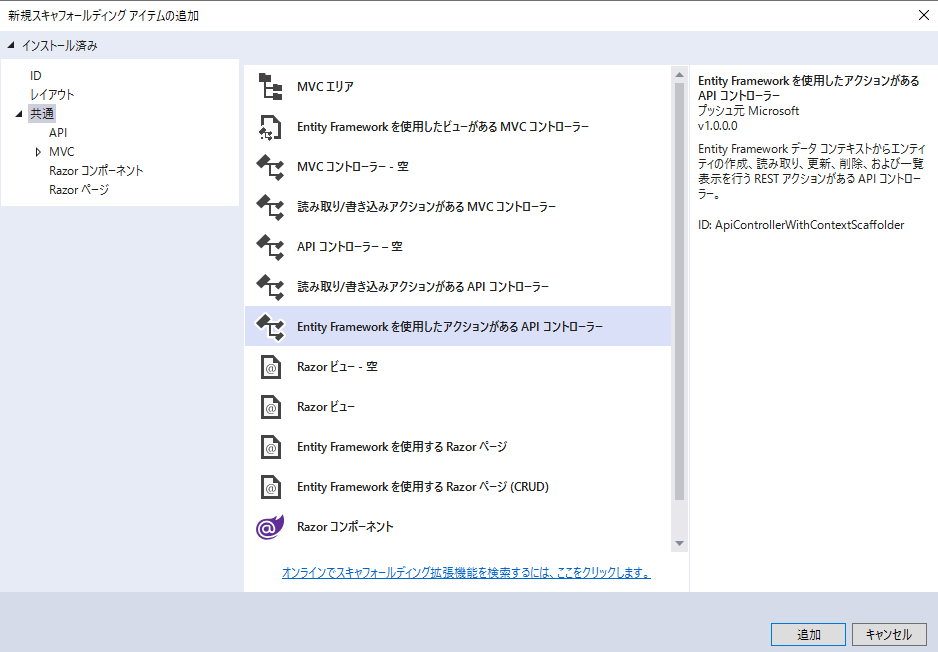
[Entity Frameworkを使用したアクションがあるAPIコントローラーの追加] ダイアログで以下を選択[TodoItem (TodoApi.Models)] を選択[TodoContext (TodoApi.Models)] を選択[追加] をクリック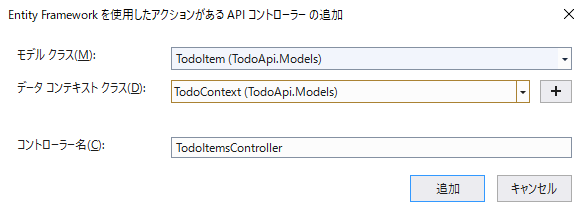
公式サイト通り
TodoItemsController.cs の PostTodoItem メソッドの return文を以下のように変更return CreatedAtAction(nameof(GetTodoItem), new { id = todoItem.Id }, todoItem);ここは公式サイトにはない手順。
マイグレーションはコマンドラインから行う。
Visual Studioのプロジェクトを作成したフォルダで以下のコマンドを実行する。
dotnet ef migrations add DbInit
dotnet ef database update(参考) dotnet-ef サブコマンドがインストールされていなければ以下のコマンドでインストールする
dotnet tool install --global dotnet-ef公式サイトと同じようにPostmanを使って確認する。
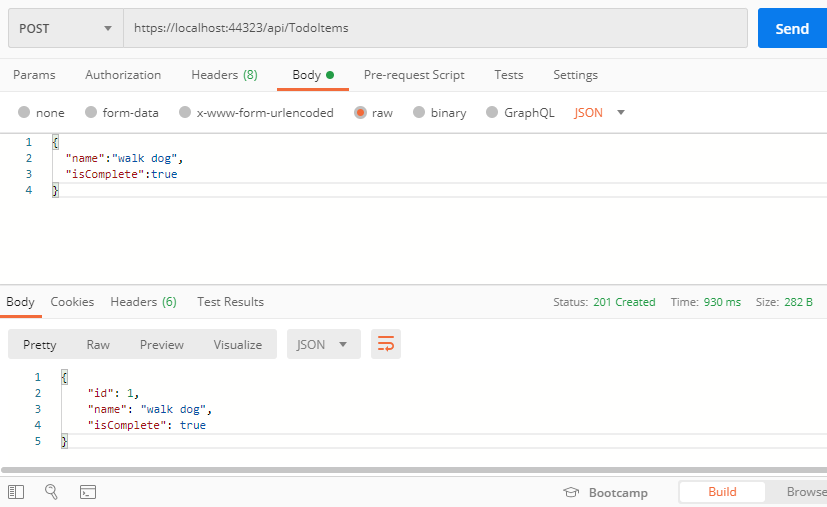
公式サイトと同じようにPostmanを使って確認する。
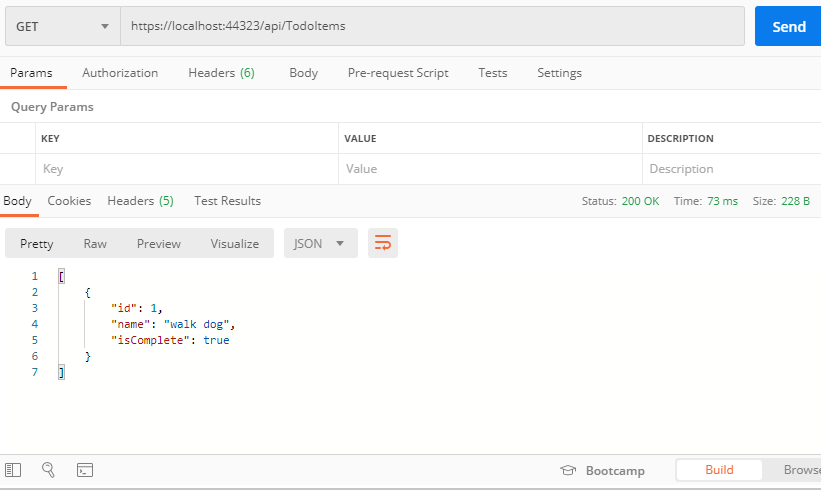
以下のコマンドでデータが作成されていることを確認する。
> docker exec -t todoapi_db_1 mysql -u todoapi -ppassword todoapi -e "SELECT * FROM TodoItems;"
+----+----------+------------+
| Id | Name | IsComplete |
+----+----------+------------+
| 1 | walk dog | 1 |
+----+----------+------------+今回はここまで
AWSの音声をテキストに変換(文字起こし)してくれるサービス Amazon Transcribeを使ってみたので備忘録に残しておく。TranscribeはS3にある音声ファイルを指定すると文字起こししてくれて、文字起こしの結果をS3にアップロードしてくれる。
処理の流れは以下のようにした。
基本的には前回のAzure Speech Servicesと同じ流れ。AWSはPython SDKが充実していてS3、Transcribeの処理どちらもSDKで実装できたのが良かった。
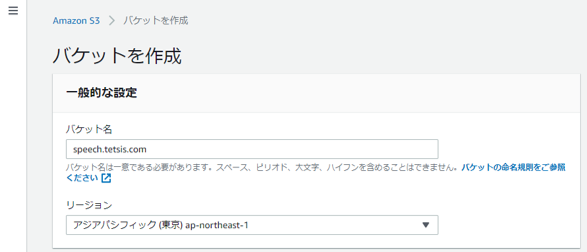
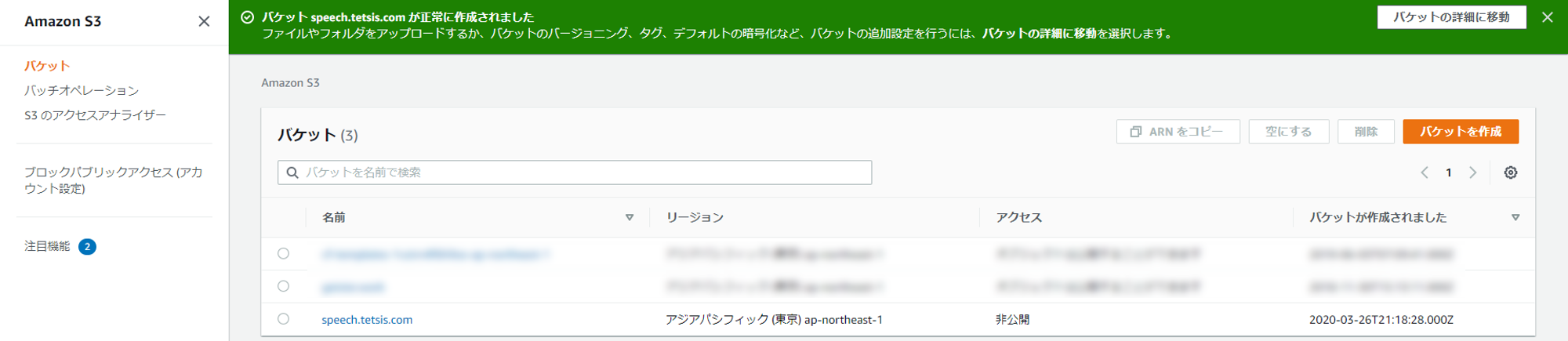
TranscribeではS3にアップロードされている音声ファイルを利用するためにS3バケットを作成する。まずはS3のページにアクセスし、右上の「バケットを作成」をクリック。

バケット名を入力する。今回は「speech.tetsis.com」にした。
そのまま「バケットを作成」をクリック。
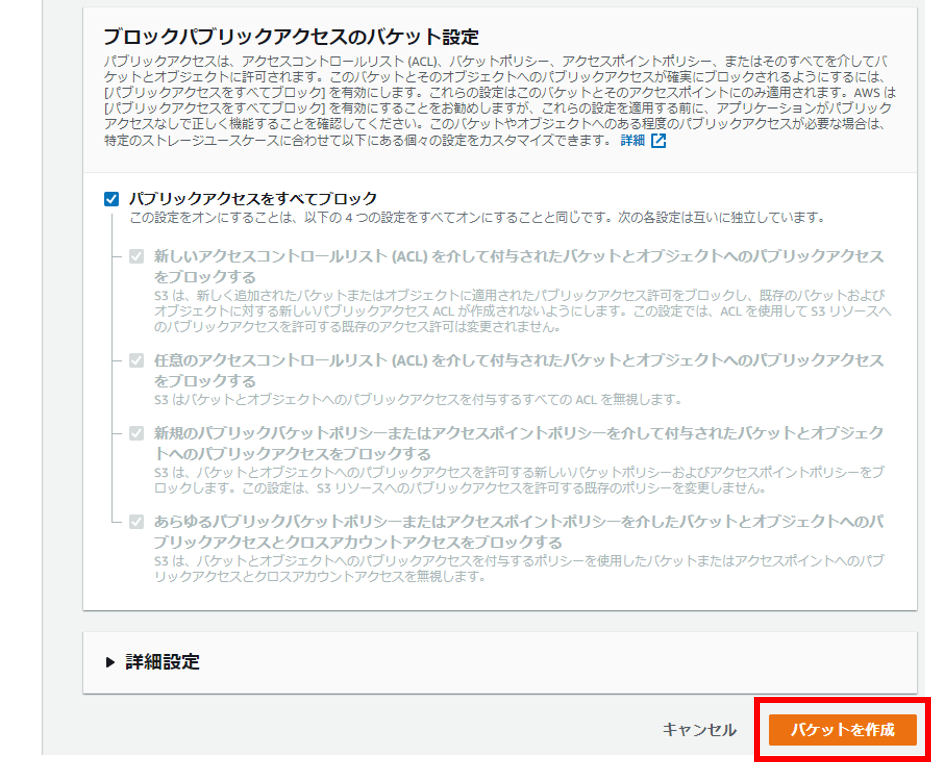
バケット「speech.tetsis.com」が作成された。
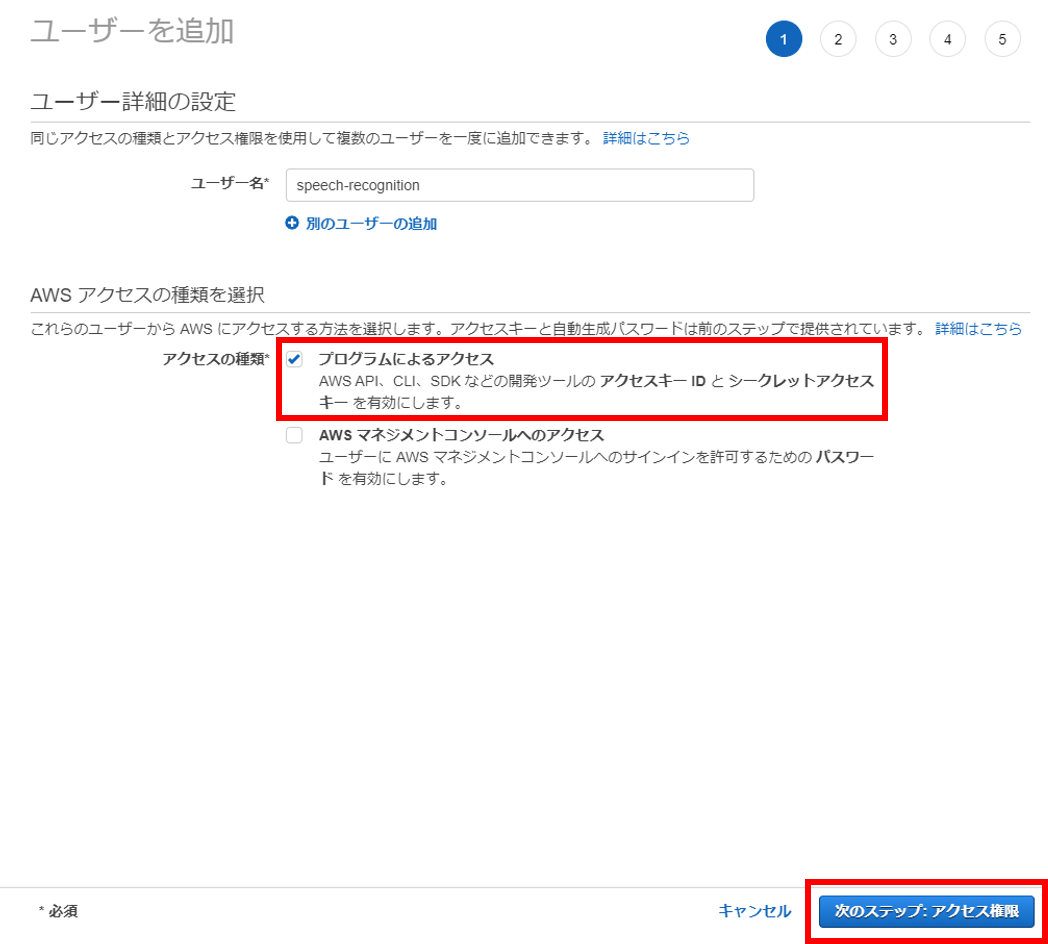
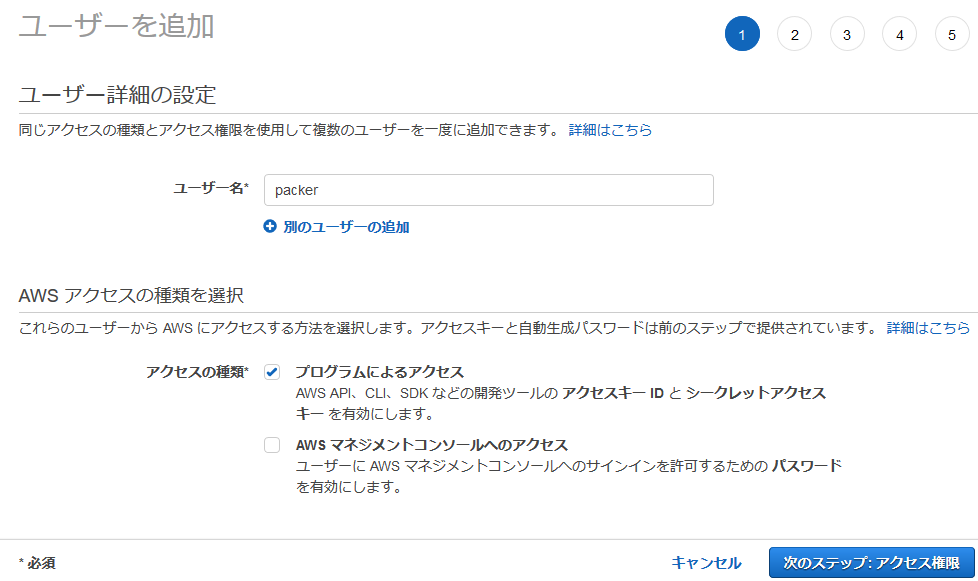
Python SDKでAWSのリソースを操作するためのIAMユーザーを作成する。まずはIAMユーザーページにアクセスし、「ユーザーを追加」をクリック。

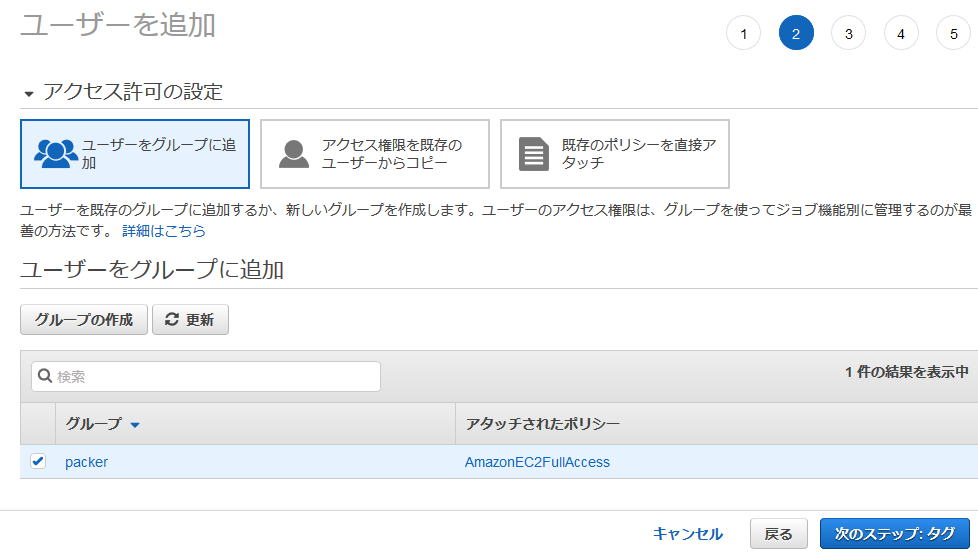
ユーザー名は「speech-recognition」にした。「プログラムによるアクセス」をチェックし、「次のステップ:アクセス権限」をクリック。
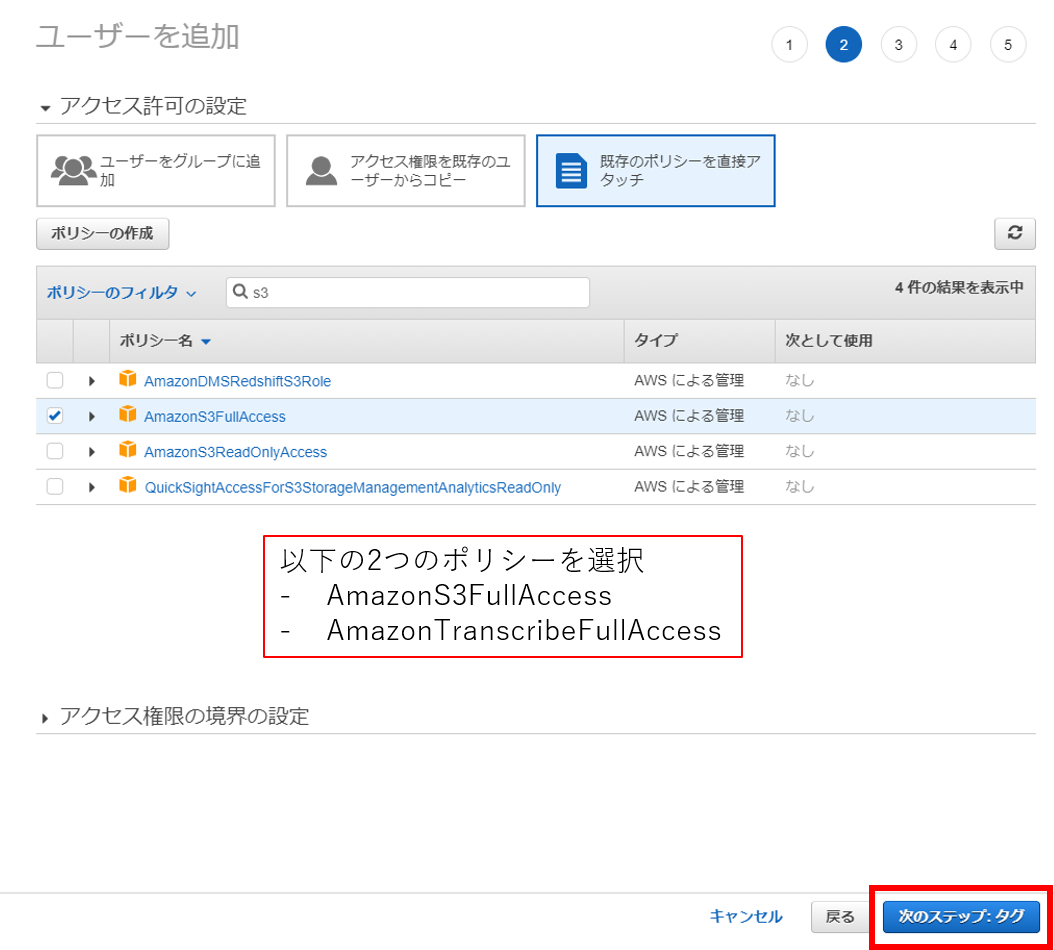
「AmazonS3FullAccess」と「AmazonTranscribeFullAccess」をチェックして、「次のステップ:タグ」をクリック。
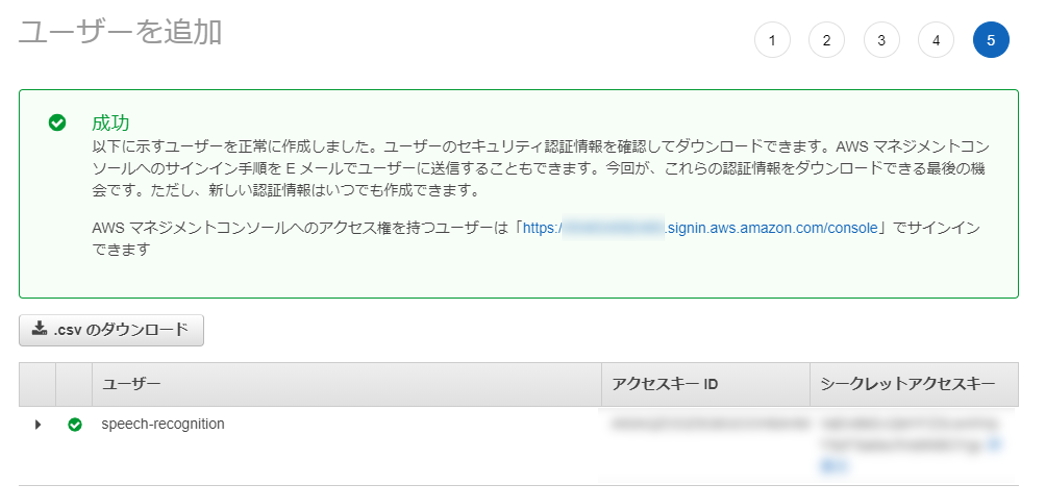
あとはそのまま進める。IAMユーザーが作成できたら「アクセスキーID」と「シークレットアクセスキー」が表示されるのでメモしておく。
公式ページを参考にawsコマンドをインストールする。詳細な方法は割愛する。
awsコマンドがインストールできたら認証情報を設定する。以下のコマンドを実行し、先ほどメモしておいた「アクセスキーID」と「シークレットアクセスキー」を入力する。
aws configure今回は以下の環境でPythonを実行する。
– OS: Windows 10
– Python 3.8.1
– pip 20.0.2
最初にPython SDKであるboto3をインストールしておく。
pip install boto3今回は一つのファイル(aws_speech.py)で実装していく。汎用性の高い関数として実装した「関数コード」と、「main関数コード」の2パートに分けて紹介する。
まずはファイルの先頭にライブラリをインポートするimport文を記述する。
# -*- coding: utf-8 -*-
import os
import uuid
import argparse
import logging
import re
import time
import json
import boto3
from botocore.exceptions import ClientErrorこの関数は公式ドキュメントを参考にした。
def upload_file(bucket_name, local_path, local_file_name):
root_ext_pair = os.path.splitext(local_file_name)
object_name = root_ext_pair[0] + str(uuid.uuid4()) + root_ext_pair[1] # S3バケット内で唯一のオブジェクト名になるようにランダム文字列(UUID)を挿入しておく
upload_file_path = os.path.join(local_path, local_file_name)
# Upload the file
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(upload_file_path, bucket_name, object_name)
except ClientError as e:
print(e)
return None
print("\nUploading " + local_file_name +" to S3 as object:\n\t" + object_name)
return object_nameS3バケット名は環境変数で指定するようにした。音声ファイルと言語はプログラム実行時に引数で指定するようにした。
if __name__ == "__main__":
bucket_name = os.getenv("S3_BUCKET_NAME")
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", type=argparse.FileType("r", encoding="UTF-8"), required=True)
parser.add_argument("-l", "--locale", help="e.g. \"en-US\" or \"ja-JP\"", required=True)
args = parser.parse_args()
file_name = args.file.name
locale = args.locale
# STEP1: ローカルにある音声ファイルをS3にアップロード
base_dir_pair = os.path.split(file_name)
local_path = base_dir_pair[0]
local_file_name = base_dir_pair[1]
object_name = upload_file(bucket_name, local_path, local_file_name)実行前に環境変数にS3バケット名を設定する。テキスト変換させる音声は攻殻機動隊SAC26話の名セリフを使ってみる。Netflixで視聴できる。
> $env:S3_BUCKET_NAME = "speech.tetsis.com"
> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフf6a85e99-8f22-4b95-82a0-77cfd3be80db.mp3音声ファイルをS3にアップロードできた。実際にAWSコンソール画面を見ると音声ファイルがアップロードされているのが確認できる。
Transcribeで文字起こしを開始するためにはジョブ名を設定する必要がある。ジョブ名には文字数と種類の制約があるので、それに合わせるためS3にアップロードしたオブジェクト名を変換している。
また、OutputBucketNameには文字起こし結果を格納するS3バケットを指定できる。今回はSTEP1でアップロードしたバケットと同じバケットを使うこととにする。この関数は公式ドキュメントが参考になった。
def start_transcription_job(bucket_name, object_name, language_code):
job_name = re.sub(r'[^a-zA-Z0-9._-]', '', object_name)[:199] # Transcribeのフォーマット制約に合わせる(最大200文字。利用可能文字は英大文字小文字、数字、ピリオド、アンダーバー、ハイフン)
media_file_url = 's3://' + bucket_name + '/' + object_name
client = boto3.client('transcribe')
response = client.start_transcription_job(
TranscriptionJobName=job_name,
LanguageCode=language_code,
Media={
'MediaFileUri': media_file_url
},
OutputBucketName=bucket_name
)
print("\nTranscription start")
return job_nameif __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2: Transcribeに文字起こし処理を依頼
job_name = start_transcription_job(bucket_name, object_name, locale)> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフ04bd9138-da2f-400c-9ea6-7650d524e34e.mp3
Transcription startこれで文字起こし処理を開始するところまでできた。AWSのコンソール画面からTranscribeページを見ると、処理が登録されていることが確認できる。Webブラウザから簡単に処理状態や文字起こし結果を確認できるのがAWSのいいところだと思う。
get_transcription_jobのレスポンスのjsonフォーマットは公式ドキュメントを参考にした。
def get_transcription_status(job_name):
client = boto3.client("transcribe")
response = client.get_transcription_job(
TranscriptionJobName=job_name
)
status = response["TranscriptionJob"]["TranscriptionJobStatus"]
print("Transcription status:\t" + status)
return statusif __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3: 定期的に処理結果を確認
status = ""
while status not in ["COMPLETED", "FAILED"]: # 処理が完了したら状態が"COMPLETED"、失敗したら"FAILED"になるからそれまでループ
status = get_transcription_status(job_name) # 処理状態を取得
time.sleep(3)> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフ6d53dece-ea7c-4966-923a-e45687da42b0.mp3
Transcription start
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: COMPLETED処理が完了するのを待つところまで実行できた。
処理が完了すると、文字起こし結果がS3にアップロードされる。get_transcription_job関数では文字起こし結果を格納しているS3オブジェクトのURLを返してくれる。
def get_transcription_file_url(job_name):
client = boto3.client("transcribe")
response = client.get_transcription_job(
TranscriptionJobName=job_name
)
file_url = response["TranscriptionJob"]["Transcript"]["TranscriptFileUri"]
print("\nFile URL:\n\t" + file_url)
return file_urlif __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3のコード(ここでは省略)
# STEP4: 処理が完了したら処理結果のURLを取得
file_url = get_transcription_file_url(job_name)> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフd3496aa1-11f8-4f90-aeb8-e4f705467a0d.mp3
Transcription start
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
...(中略)...
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: COMPLETED
File URL:
https://s3.ap-northeast-1.amazonaws.com/speech.tetsis.com/d3496aa1-11f8-4f90-aeb8-e4f705467a0d.mp3.json最後に表示されているURLが文字起こし結果が格納されているS3オブジェクト。
download_file関数は公式ドキュメントを参考にした。ダウンロードしたjsonファイルのデータフォーマットも公式ドキュメントを参考にした。
def download_file(bucket_name, object_name):
s3 = boto3.client('s3')
s3.download_file(bucket_name, object_name, object_name)
print("\nDownloading S3 object:\n\t" + object_name)
def get_transcript_from_file(file_name):
with open(file_name, "r", encoding="utf-8") as f:
df = json.load(f)
transcript = ""
for result in df["results"]["transcripts"]:
transcript += result["transcript"] + "\n"
print("\nTranscription result:\n" + transcript)
return transcriptif __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3のコード(ここでは省略)
# STEP4のコード(ここでは省略)
# STEP5: 処理結果をS3からダウンロードし結果を表示 (Pyhon SDK)
result_object_name = file_url[file_url.find(bucket_name) + len(bucket_name) + 1:]
download_file(bucket_name, result_object_name) # ここでダウンロード
get_transcript_from_file(result_object_name)> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフ6aa4385a-f760-4c76-9b03-2cf015593a59.mp3
Transcription start
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
...(中略)...
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: COMPLETED
File URL:
https://s3.ap-northeast-1.amazonaws.com/speech.tetsis.com/6aa4385a-f760-4c76-9b03-2cf015593a59.mp3.json
Downloading S3 object:
6aa4385a-f760-4c76-9b03-2cf015593a59.mp3.json
Transcription result:
だ けど 私 は 情報 の 並列 化 の 果て に 後 を 取り戻す ため の 一つ の 可能 性 を 見つけ た わ ちなみに その 答え は 好奇 心 多分 ねどのセリフを文字起こししたのか、まあ分かる、よね。単語ごと(?)にスペース区切りされているから少し見づらいけどほとんど正確に文字に変換してくれてる(「後」は本当は「個」。セリフの重要な部分なだけに残念)。「ちなみに その 答え は」は別の人のセリフなんだけどそれでもちゃんと認識しててすごい。
最後に今回のコードの全体を載せておく。
# -*- coding: utf-8 -*-
import os
import uuid
import argparse
import logging
import re
import time
import json
import boto3
from botocore.exceptions import ClientError
def upload_file(bucket_name, local_path, local_file_name):
root_ext_pair = os.path.splitext(local_file_name)
object_name = root_ext_pair[0] + str(uuid.uuid4()) + root_ext_pair[1] # S3バケット内で唯一のオブジェクト名になるようにランダム文字列(UUID)を挿入しておく
upload_file_path = os.path.join(local_path, local_file_name)
# Upload the file
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(upload_file_path, bucket_name, object_name)
except ClientError as e:
print(e)
return None
print("\nUploading " + local_file_name +" to S3 as object:\n\t" + object_name)
return object_name
def download_file(bucket_name, object_name):
s3 = boto3.client('s3')
s3.download_file(bucket_name, object_name, object_name)
print("\nDownloading S3 object:\n\t" + object_name)
def start_transcription_job(bucket_name, object_name, language_code):
job_name = re.sub(r'[^a-zA-Z0-9._-]', '', object_name)[:199] # Transcribeのフォーマット制約に合わせる(最大200文字。利用可能文字は英大文字小文字、数字、ピリオド、アンダーバー、ハイフン)
media_file_url = 's3://' + bucket_name + '/' + object_name
client = boto3.client('transcribe')
response = client.start_transcription_job(
TranscriptionJobName=job_name,
LanguageCode=language_code,
Media={
'MediaFileUri': media_file_url
},
OutputBucketName=bucket_name
)
print("\nTranscription start")
return job_name
def get_transcription_status(job_name):
client = boto3.client("transcribe")
response = client.get_transcription_job(
TranscriptionJobName=job_name
)
status = response["TranscriptionJob"]["TranscriptionJobStatus"]
print("Transcription status:\t" + status)
return status
def get_transcription_file_url(job_name):
client = boto3.client("transcribe")
response = client.get_transcription_job(
TranscriptionJobName=job_name
)
file_url = response["TranscriptionJob"]["Transcript"]["TranscriptFileUri"]
print("\nFile URL:\n\t" + file_url)
return file_url
def get_transcript_from_file(file_name):
with open(file_name, "r", encoding="utf-8") as f:
df = json.load(f)
transcript = ""
for result in df["results"]["transcripts"]:
transcript += result["transcript"] + "\n"
print("\nTranscription result:\n" + transcript)
return transcript
if __name__ == "__main__":
bucket_name = os.getenv("S3_BUCKET_NAME")
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", type=argparse.FileType("r", encoding="UTF-8"), required=True)
parser.add_argument("-l", "--locale", help="e.g. \"en-US\" or \"ja-JP\"", required=True)
args = parser.parse_args()
file_name = args.file.name
locale = args.locale
# STEP1: ローカルにある音声ファイルをS3にアップロード
base_dir_pair = os.path.split(file_name)
local_path = base_dir_pair[0]
local_file_name = base_dir_pair[1]
object_name = upload_file(bucket_name, local_path, local_file_name)
# STEP2: Transcribeに文字起こし処理を依頼
job_name = start_transcription_job(bucket_name, object_name, locale)
# STEP3: 定期的に処理結果を確認
status = ""
while status not in ["COMPLETED", "FAILED"]: # 処理が完了したら状態が"COMPLETED"、失敗したら"FAILED"になるからそれまでループ
status = get_transcription_status(job_name) # 処理状態を取得
time.sleep(3)
# STEP4: 処理が完了したら処理結果のURLを取得
file_url = get_transcription_file_url(job_name)
# STEP5: 処理結果をS3からダウンロードし結果を表示 (Pyhon SDK)
result_object_name = file_url[file_url.find(bucket_name) + len(bucket_name) + 1:]
download_file(bucket_name, result_object_name) # ここでダウンロード
get_transcript_from_file(result_object_name)Azureの文字起こしサービスを使ってみたので、Azureのポータル画面での操作とPythonコードをまとめておく。
今回使うAzureのサービスは文字起こしの中でも「バッチ文字起こし」というもので、Blob Storageにアップロードした音声ファイルを文字起こししてくれるものである。文字起こしの結果もBlob Storageに保存される。
処理の流れをまとめると以下のようになる。この記事は以下の順番で書いている。
Azureポータル画面でリソースの作成と認証情報の取得を行う。
まずはストレージアカウントというコンテナ―の上位概念を作成。作成ページへの行き方はいろいろあると思うけど、ポータルのホーム画面から左上の三本線アイコンから「ストレージアカウント」をクリックするのが簡単。
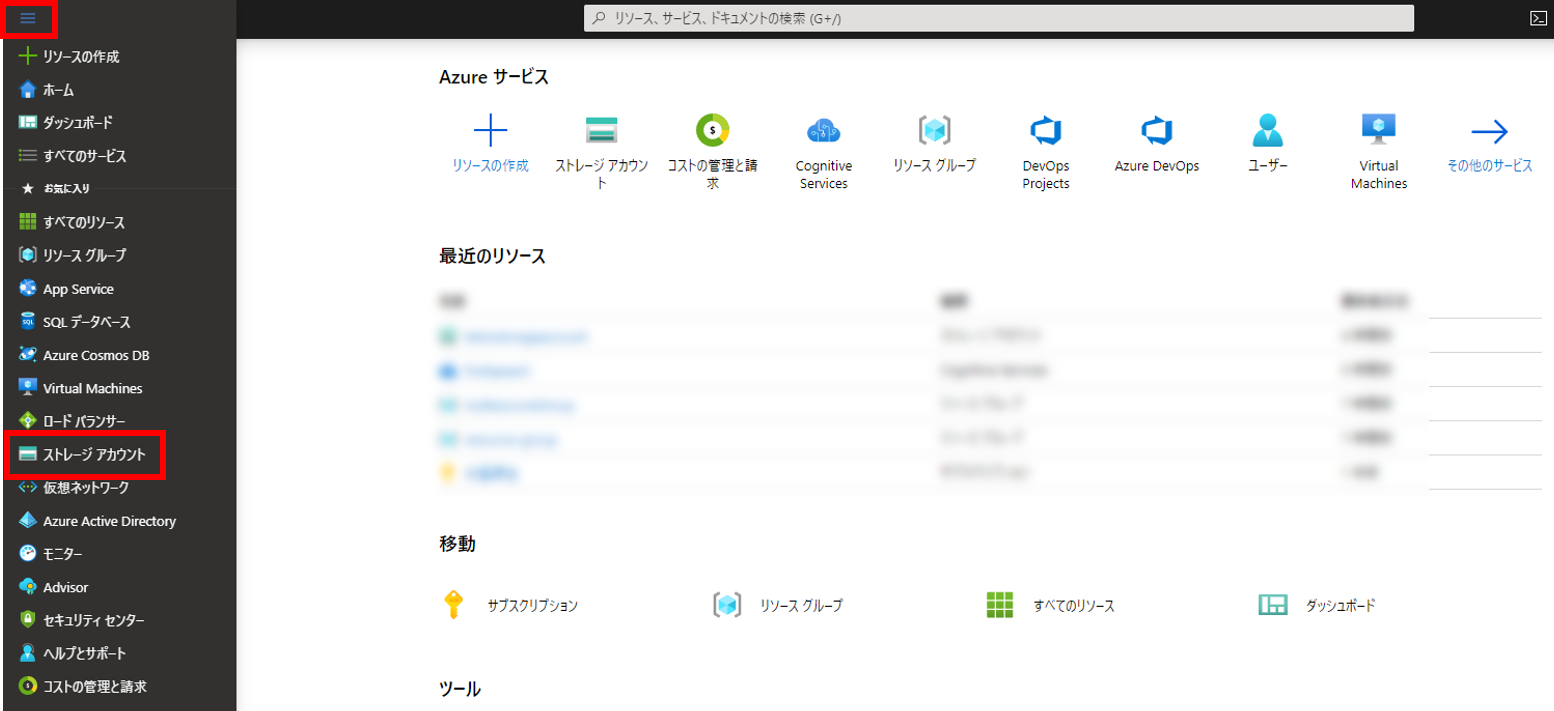
ストレージアカウント名はAzure内でユニークでなければならない。今回は「tetsisstorageaccount」にしてみた。リソースグループは事前に作っておいた「SpeechRecognition」、場所は「東日本」にした。その他はデフォルト。
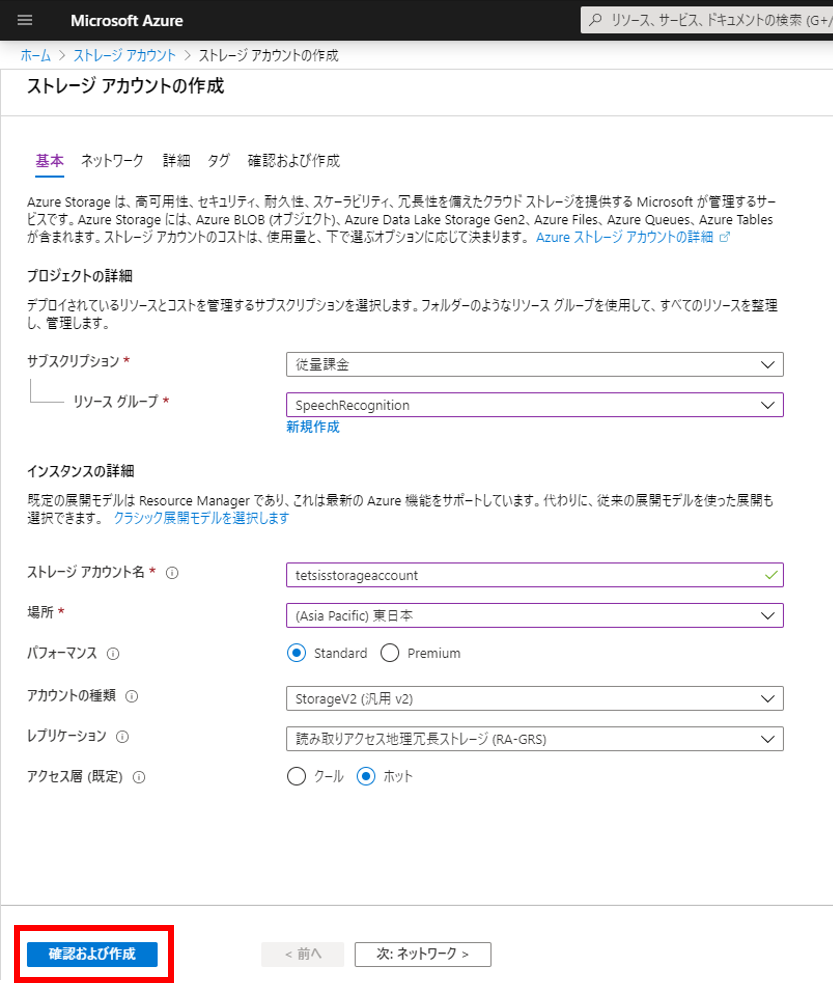
ストレージアカウントが作成できたらコンテナーを作成する。図の赤枠で囲った「コンテナー」をクリックする。
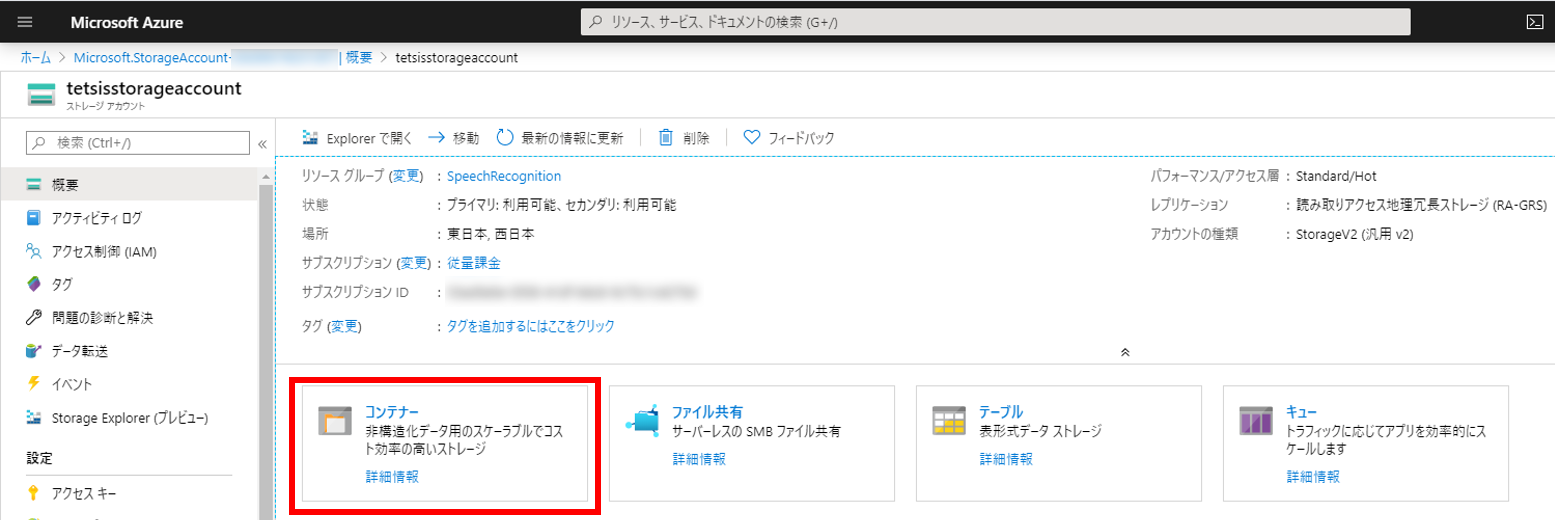
右側から「新しいコンテナー」モーダルが出てくる。今回は「speechcontainer」というコンテナー名にしてみた。

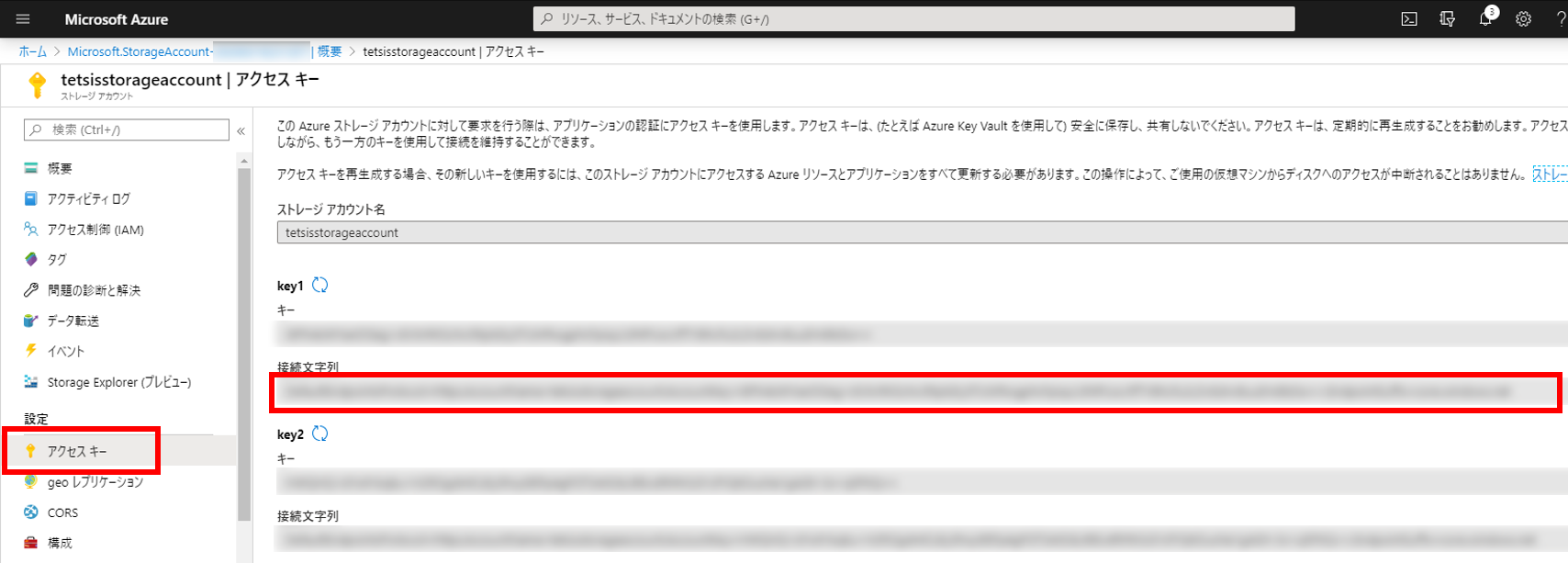
ストレージアカウント画面の左メニューから「アクセスキー」をクリックすると下図のようなページが表示されるので、「接続文字列」をメモしておく。(このページはいつでも見にこれる。key1とkey2はどちらでもよい)
音声認識サービスのリソースを作成する。作成ページに行くにはポータル画面の検索欄で「speech」と入力して表示される「Cognitive Services」をクリックするのが簡単。Cognitive ServicesはSpeech Servicesの上位概念。
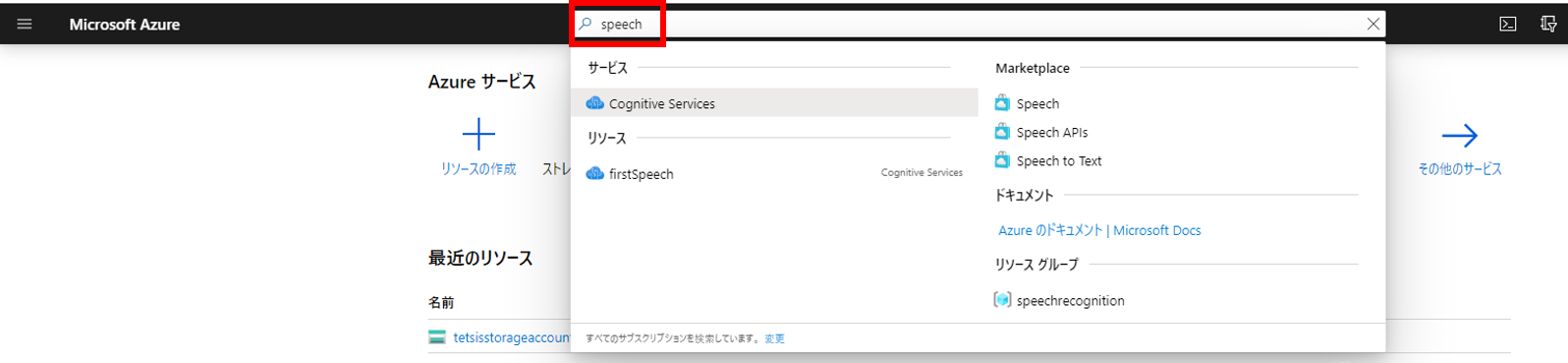
下図の「追加」をクリックする。
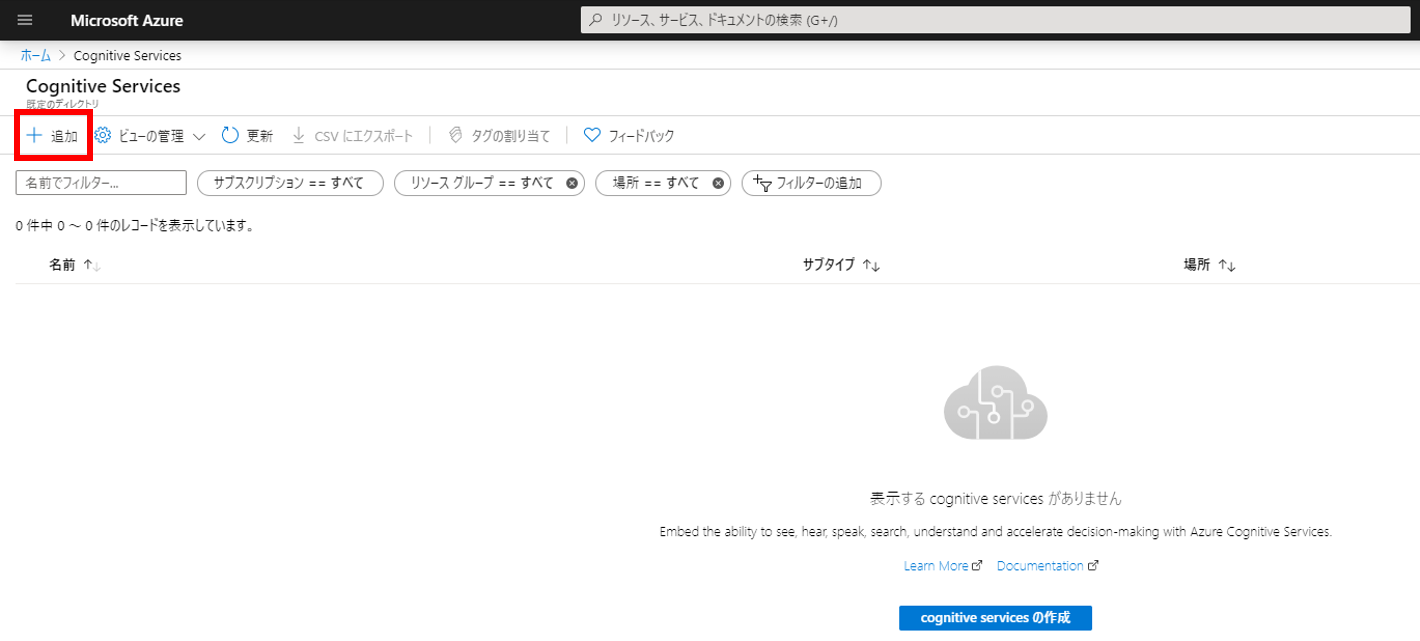
Marketplaceの検索欄で「speech」と入力して表示される「音声」をクリックする。
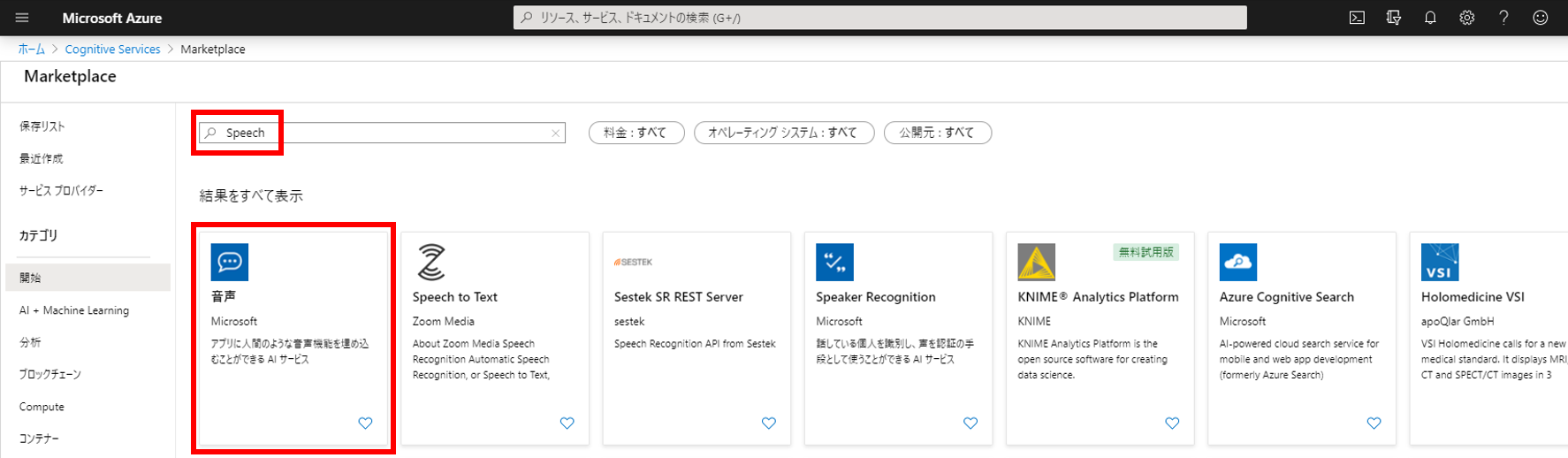
「作成」ボタンをクリックする。
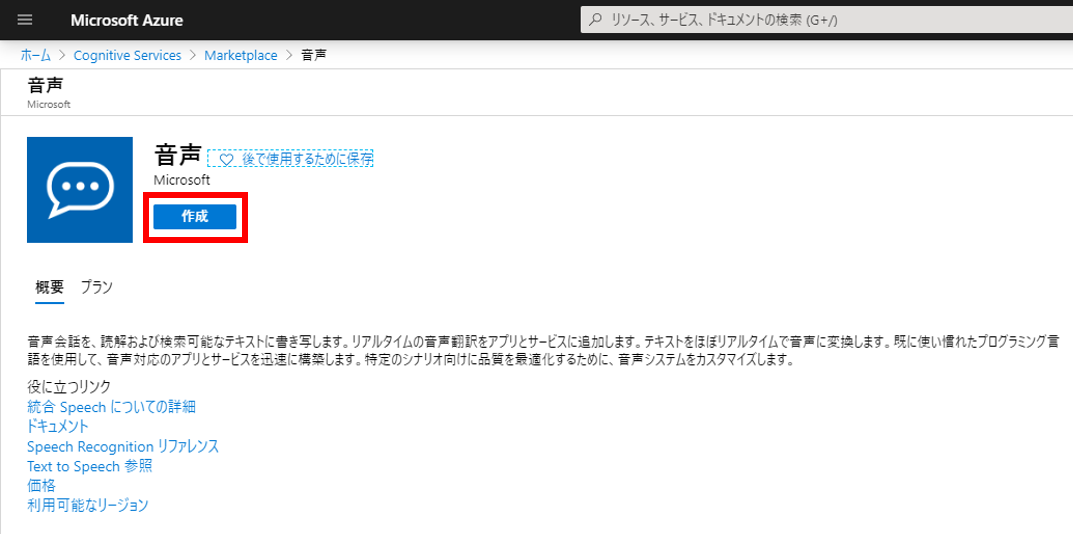
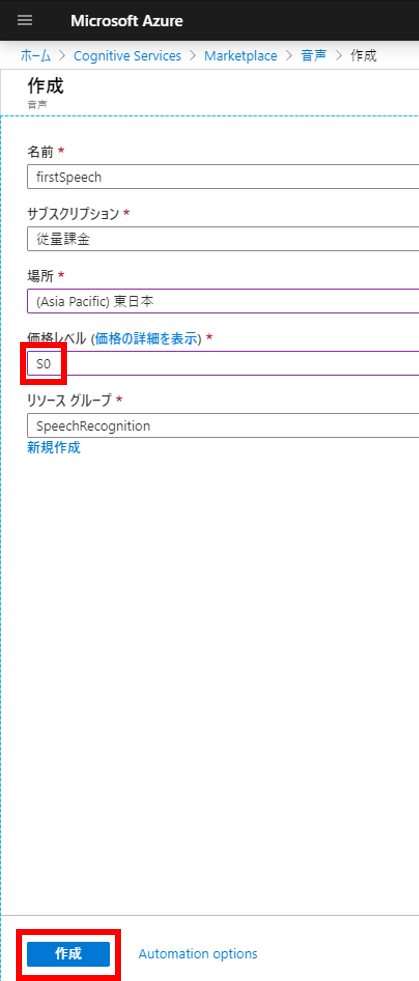
情報入力ページが表示される。名前は任意でよい。今回は「firstSpeech」にしてみた。場所は「東日本」。価格レベルは「SO」を選択する。今回利用するバッチ文字起こしはSOでないと利用できない。
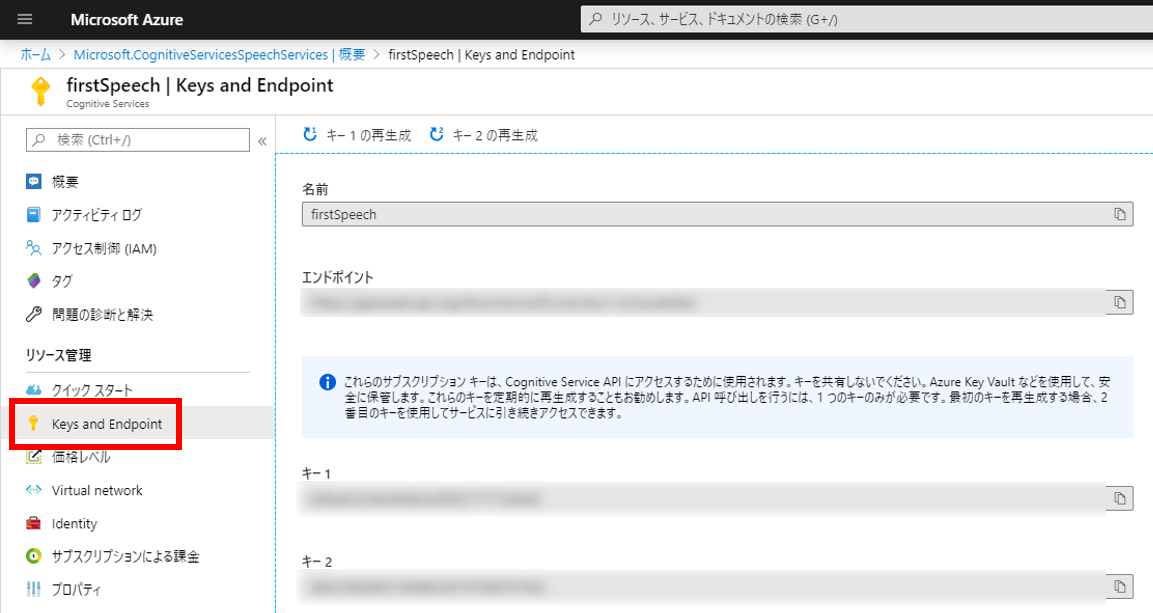
Cognitive Services画面の左メニューから「Keys and Endpoint」をクリックすると下図のようなページが表示されるので、サブスクリプションキーである「キー1」をメモしておく。 (このページはいつでも見にこれる。キー1とキー2はどちらでもよい)
ブラウザ操作はこれで終わり。ようやくコーディングのお時間。今回は以下の環境で実行している。
– OS: Windows 10
– Python 3.8.1
– pip 20.0.2
以下のライブラリをインストールしておく。
pip install requests azure-storage-blob今回は一つのPythonファイルでコマンドラインから実行する簡単な方法でやってみる(ファイル名はazure_speech.py)。
まずファイルの先頭に以下のimport文を記載する。
# -*- coding: utf-8 -*-
import os
import uuid
import argparse
from datetime import datetime, timedelta
import requests
import json
import time
from azure.storage.blob import BlobServiceClient
from azure.storage.blob import ResourceTypes, AccountSasPermissions, ContainerSasPermissions
from azure.storage.blob import generate_account_sas, generate_container_sasdef upload_blob(connect_str, container_name, local_path, local_file_name):
root_ext_pair = os.path.splitext(local_file_name)
blob_name = root_ext_pair[0] + str(uuid.uuid4()) + root_ext_pair[1] # Blob Storage(コンテナー)内で唯一のBlob名になるようにランダム文字列(UUID)を挿入しておく
upload_file_path = os.path.join(local_path, local_file_name)
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
print("\nUploading to Azure Storage as blob:\n\t" + blob_name)
with open(upload_file_path, "rb") as data:
blob_client.upload_blob(data)
return blob_name実行時に引数として①音声ファイルと②言語を指定するようにした。これでいろんな言語の音声ファイルで試しやすくなるはず。
if __name__ == "__main__":
connect_str = os.getenv("AZURE_STORAGE_CONNECTION_STRING")
container_name = os.getenv("AZURE_STORAGE_CONTAINER_NAME")
subscription_key = os.getenv("AZURE_SPEECH_SERVICE_SUBSCRIPTION_KEY")
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", type=argparse.FileType("r", encoding="UTF-8"), required=True)
parser.add_argument("-l", "--locale", help="e.g. \"en-US\" or \"ja-JP\"", required=True)
args = parser.parse_args()
file_name = args.file.name
locale = args.locale
# STEP1: ローカルにある音声ファイルをBlob Storageにアップロード (Python SDK)
base_dir_pair = os.path.split(file_name)
local_path = base_dir_pair[0]
local_file_name = base_dir_pair[1]
blob_name = upload_blob(connect_str, container_name, local_path, local_file_name) # ここでアップロード最初に環境変数を設定してからPythonファイルを実行する。今回は環境変数の設定方法がWindows仕様。Mac、Linuxの場合は export コマンドを使えば同じことができる。
音声ファイルは攻殻機動隊の名言でテストしてみた。攻殻機動隊SAC5話のセリフでNetflixから視聴可能。Pythonファイル(azure_speech.py)と同じフォルダに音声ファイル(荒巻名セリフ.wav)を置いている。
> $env:AZURE_STORAGE_CONNECTION_STRING = "メモしておいた接続文字列"
> $env:AZURE_STORAGE_CONTAINER_NAME = "作成したコンテナー名"
> $env:AZURE_SPEECH_SERVICE_SUBSCRIPTION_KEY = "メモしておいたサブスクリプションキー"
> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフ43936629-807a-4d1a-b6d5-a5d0c67c50fe.wavAzureのポータル画面にて、元のファイル名にUUIDが追加されたファイル(上の実行結果の場合は 荒巻名セリフ43936629-807a-4d1a-b6d5-a5d0c67c50fe.wav )がコンテナーにアップロードされているのが確認できる。
API仕様はSwaggerに載っていて実装の時は結構参考になった。「Custom Speech transcriptions:」セクションが今回使うAPI。
最初の2つの関数はアカウントSASとサービスSASという、APIを使う際の認証情報を取得する関数である。SAS自体はAzureが提供している関数を利用して生成している。公式のドキュメントページでSAS生成関数が紹介されている。
TranscriptionResultsContainerUrl には処理結果のファイルを格納してもらうコンテナ―を認証情報つきで記載する。今回は最初に作ったコンテナ―を流用した。なので、音声ファイルと同じコンテナ―に処理結果のファイルも格納される。
def get_sas_token(connect_str):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
sas_token = generate_account_sas(
blob_service_client.account_name,
account_key=blob_service_client.credential.account_key,
resource_types=ResourceTypes(object=True),
permission=AccountSasPermissions(read=True),
expiry=datetime.utcnow() + timedelta(hours=1)
)
return sas_token
def get_service_sas_token(connect_str, container_name):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
service_sas_token = generate_container_sas(
blob_service_client.account_name,
container_name,
account_key=blob_service_client.credential.account_key,
permission=ContainerSasPermissions(read=True, write=True),
expiry=datetime.utcnow() + timedelta(hours=1),
)
return service_sas_token
def start_transcription(connect_str, container_name, blob_name, subscription_key, locale):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
account_name = blob_service_client.account_name
container_url = "https://" + account_name + ".blob.core.windows.net/" + container_name
sas_token = get_sas_token(connect_str)
service_sas_token = get_service_sas_token(connect_str, container_name)
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions"
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
payload = {
"recordingsUrl": container_url + "/" + blob_name + "?" + sas_token,
"locale": locale,
"name": blob_name,
"properties": {
"TranscriptionResultsContainerUrl" : container_url + "?" + service_sas_token
}
}
r = requests.post(url, data=json.dumps(payload), headers=headers)
print("\nTranscription start")if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2: AzureのSpeech serviceに文字起こし処理を依頼 (REST API)
start_transcription(connect_str, container_name, blob_name, subscription_key, locale)> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフcbbbe4e2-5507-4cae-8b54-a13003104be8.wav
Transcription start最後に「Transcription start」と表示される。
STEP2で開始した処理を特定できる情報は名前 name なんだけど、実行状態を取得するためのGETのAPIはIDで指定する仕様になっている。そのため最初にget_transcription_id関数で名前からIDを取得してから、IDを使って定期的に状態を取得している。これ、STEP2でPOSTした時のレスポンスにIDを含めてくれたらいんだけどなぁ、、と思う。名前だけだと毎回リスト取得するしかなくて無駄に情報取ってくることになって効率悪いんだよなぁ。
def get_transcription_id(subscription_key, transcription_name):
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions"
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
r = requests.get(url, headers=headers)
response = json.loads(r.text)
for res in response:
if res["name"] == transcription_name:
id = res["id"]
print("\nTranscription ID:\n\t" + id)
return id
return None
def get_transcription_info_from_id(subscription_key, transcription_id):
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions/" + transcription_id
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
r = requests.get(url, headers=headers)
response = json.loads(r.text)
return response
def get_transcription_status(subscription_key, transcription_id):
response = get_transcription_info_from_id(subscription_key, transcription_id)
status = response["status"]
print("Transcription status:\t" + status)
return statusif __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3: 定期的に処理結果を確認 (REST API)
transcription_id = get_transcription_id(subscription_key, blob_name) # Transcription nameからIDを取得
status = ""
while status != "Succeeded": # 処理が完了したら状態が"Succeeded"になるからそれまでループ
status = get_transcription_status(subscription_key, transcription_id) # 処理状態を取得
time.sleep(3)> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフb822c506-843c-4f1d-af81-35799e9209dc.wav
Transcription start
Transcription ID:
e5512338-1e66-44c0-bd5f-68b680d99ba6
Transcription status: NotStarted
Transcription status: NotStarted
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: SucceededTranscription status が NotStartedからRunningになり、最終的にSucceededになっている。
def get_transcription_result_url(subscription_key, transcription_id):
response = get_transcription_info_from_id(subscription_key, transcription_id)
if "resultsUrls" in response:
result_url = response["resultsUrls"]["channel_0"]
print("\nResult URL:\n\t" + result_url)
return result_url
return Noneif __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3のコード(ここでは省略)
# STEP4: 処理が完了したら処理結果のBlob URLを取得 (REST API)
result_url = get_transcription_result_url(subscription_key, transcription_id)> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフ9b3f55c6-4c3f-4656-a48e-a4546907a31e.wav
Transcription start
Transcription ID:
e83a0767-d4ab-421b-8476-7cba3f5dde30
Transcription status: NotStarted
Transcription status: NotStarted
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Succeeded
Result URL:
https://tetsisstorageaccount.blob.core.windows.net/speechcontainer/e83a0767-d4ab-421b-8476-7cba3f5dde30_transcription_channel_0.json処理結果のURLが表示される。
ダウンロードのコードもアップロードと同様に公式ページに載っている方法を参考にした。
結果のjsonファイルのデータフォーマットについては公式ページや Swaggerページを参考にした。テキスト化した結果は Lexical, ITN, MaskedITN, Display の4種類があるみたいだけど、今回は句読点とかつけてくれる Display を表示することにした。
def download_blob(connect_str, container_name, blob_name):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
print("\nUploading to Azure Storage as blob:\n\t" + blob_name)
with open(blob_name, "wb") as download_file:
download_file.write(blob_client.download_blob().readall())
def get_transcript_from_file(file_name):
with open(file_name, "r", encoding="utf-8") as f:
df = json.load(f)
transcript = ""
for audio_file_result in df["AudioFileResults"]:
for combined_result in audio_file_result["CombinedResults"]:
transcript += combined_result["Display"] + "\n"
print("\nTranscription result:\n" + transcript)
return transcriptif __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3のコード(ここでは省略)
# STEP4のコード(ここでは省略)
# STEP5: 処理結果をBlob Storageからダウンロードし結果を表示 (Pyhon SDK)
blob_name = result_url[result_url.rfind("/") + 1:]
download_blob(connect_str, container_name, blob_name) # ここでダウンロード
get_transcript_from_file(blob_name) # ダウンロードしたファイルから音声をテキスト化した文字列を取得> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフc2d034b7-3803-431d-bcf0-368310cd678b.wav
Transcription start
Transcription ID:
9388030b-cc98-428d-ae0c-3c5cff02ed3c
Transcription status: NotStarted
Transcription status: NotStarted
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Succeeded
Result URL:
https://tetsisstorageaccount.blob.core.windows.net/speechcontainer/9388030b-cc98-428d-ae0c-3c5cff02ed3c_transcription_channel_0.json
Uploading to Azure Storage as blob:
9388030b-cc98-428d-ae0c-3c5cff02ed3c_transcription_channel_0.json
Transcription result:
よかろう我々の間にはチームプレーなどという都合の良い言い訳は存在せん。あるとすれば、、スタンドプレーから生じるチームワークだけだ。どのセリフをテキスト変換させてたのか完璧に分かる。
最後に今回のコードの全体を載せておく。
# -*- coding: utf-8 -*-
import os
import uuid
import argparse
from datetime import datetime, timedelta
import requests
import json
import time
from azure.storage.blob import BlobServiceClient
from azure.storage.blob import generate_account_sas, generate_container_sas, ResourceTypes, AccountSasPermissions, ContainerSasPermissions
def upload_blob(connect_str, container_name, local_path, local_file_name):
root_ext_pair = os.path.splitext(local_file_name)
blob_name = root_ext_pair[0] + str(uuid.uuid4()) + root_ext_pair[1] # Blob Storage(コンテナー)内で唯一のBlob名になるようにランダム文字列(UUID)を挿入しておく
upload_file_path = os.path.join(local_path, local_file_name)
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
print("\nUploading to Azure Storage as blob:\n\t" + blob_name)
with open(upload_file_path, "rb") as data:
blob_client.upload_blob(data)
return blob_name
def download_blob(connect_str, container_name, blob_name):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
print("\nUploading to Azure Storage as blob:\n\t" + blob_name)
with open(blob_name, "wb") as download_file:
download_file.write(blob_client.download_blob().readall())
def get_sas_token(connect_str):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
sas_token = generate_account_sas(
blob_service_client.account_name,
account_key=blob_service_client.credential.account_key,
resource_types=ResourceTypes(object=True),
permission=AccountSasPermissions(read=True),
expiry=datetime.utcnow() + timedelta(hours=1)
)
return sas_token
def get_service_sas_token(connect_str, container_name):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
service_sas_token = generate_container_sas(
blob_service_client.account_name,
container_name,
account_key=blob_service_client.credential.account_key,
permission=ContainerSasPermissions(read=True, write=True),
expiry=datetime.utcnow() + timedelta(hours=1),
)
return service_sas_token
def start_transcription(connect_str, container_name, blob_name, subscription_key, locale):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
account_name = blob_service_client.account_name
container_url = "https://" + account_name + ".blob.core.windows.net/" + container_name
sas_token = get_sas_token(connect_str)
service_sas_token = get_service_sas_token(connect_str, container_name)
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions"
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
payload = {
"recordingsUrl": container_url + "/" + blob_name + "?" + sas_token,
"locale": locale,
"name": blob_name,
"properties": {
"TranscriptionResultsContainerUrl" : container_url + "?" + service_sas_token
}
}
r = requests.post(url, data=json.dumps(payload), headers=headers)
print("\nTranscription start")
def get_transcription_id(subscription_key, transcription_name):
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions"
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
r = requests.get(url, headers=headers)
response = json.loads(r.text)
for res in response:
if res["name"] == transcription_name:
id = res["id"]
print("\nTranscription ID:\n\t" + id)
return id
return None
def get_transcription_info_from_id(subscription_key, transcription_id):
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions/" + transcription_id
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
r = requests.get(url, headers=headers)
response = json.loads(r.text)
return response
def get_transcription_status(subscription_key, transcription_id):
response = get_transcription_info_from_id(subscription_key, transcription_id)
status = response["status"]
print("Transcription status:\t" + status)
return status
def get_transcription_result_url(subscription_key, transcription_id):
response = get_transcription_info_from_id(subscription_key, transcription_id)
if "resultsUrls" in response:
result_url = response["resultsUrls"]["channel_0"]
print("\nResult URL:\n\t" + result_url)
return result_url
return None
def get_transcript_from_file(file_name):
with open(file_name, "r", encoding="utf-8") as f:
df = json.load(f)
transcript = ""
for audio_file_result in df["AudioFileResults"]:
for combined_result in audio_file_result["CombinedResults"]:
transcript += combined_result["Display"] + "\n"
print("\nTranscription result:\n" + transcript)
return transcript
if __name__ == "__main__":
connect_str = os.getenv("AZURE_STORAGE_CONNECTION_STRING")
container_name = os.getenv("AZURE_STORAGE_CONTAINER_NAME")
subscription_key = os.getenv("AZURE_SPEECH_SERVICE_SUBSCRIPTION_KEY")
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", type=argparse.FileType("r", encoding="UTF-8"), required=True)
parser.add_argument("-l", "--locale", help="e.g. \"en-US\" or \"ja-JP\"", required=True)
args = parser.parse_args()
file_name = args.file.name
locale = args.locale
# STEP1: ローカルにある音声ファイルをBlob Storageにアップロード (Python SDK)
base_dir_pair = os.path.split(file_name)
local_path = base_dir_pair[0]
local_file_name = base_dir_pair[1]
blob_name = upload_blob(connect_str, container_name, local_path, local_file_name) # ここでアップロード
# STEP2: AzureのSpeech serviceに文字起こし処理を依頼 (REST API)
start_transcription(connect_str, container_name, blob_name, subscription_key, locale)
# STEP3: 定期的に処理結果を確認 (REST API)
transcription_id = get_transcription_id(subscription_key, blob_name) # Transcription nameからIDを取得
status = ""
while status != "Succeeded": # 処理が完了したら状態が"Succeeded"になるからそれまでループ
status = get_transcription_status(subscription_key, transcription_id) # 処理状態を取得
time.sleep(3)
# STEP4: 処理が完了したら処理結果のBlob URLを取得 (REST API)
result_url = get_transcription_result_url(subscription_key, transcription_id)
# STEP5: 処理結果をBlob Storageからダウンロードし結果を表示 (Pyhon SDK)
blob_name = result_url[result_url.rfind("/") + 1:]
download_blob(connect_str, container_name, blob_name) # ここでダウンロード
get_transcript_from_file(blob_name) # ダウンロードしたファイルから音声をテキスト化した文字列を取得最近S3やBlob StorageのオブジェクトURLからファイル名だけ抜き出すことが何度かあって 毎回方法をググってたので備忘録にまとめておく。
object_url = 'https://account_name.blob.core.windows.net/container_name/object.json'
object_name = object_url[object_url.rfind('/') + 1:]
print(object_name)
# object.json と出力される説明。URLの末尾から「/(スラッシュ)」を検索して、スラッシュより後ろの文字列を取得する。
EKSクラスタ内で動作しているpodを外部公開するためのエンドポイントとしてALBを使う場合の構築手順をまとめておく。
ALB Ingress Controllerを使うことで、ingressをapplyしたときに自動でALBを構築してくれるのですごく便利だった。
また、ingressで任意のドメインを指定するとALBのhost-based routingに反映してくれるので、サブドメインを変えて複数のサイト公開も楽にできた。
加えて、ExternalDNSを使うと自分が管理しているドメインのレコード追加を自動でやってくれる。
SSL証明書をACMに用意しておくと、簡単にHTTPS化できたので、HTTPS対応についても最後にまとめておく。
今回使うアプリケーションはDjangoとその前段にリバースプロキシとしてnginxを配置したシンプルなもの。EKSクラスタ内にはその他にALBにルール反映してくれるALB Inress ControllerとRoute 53にレコード反映してくれるExternalDNSのpodが起動している。SSL証明書発行にはACMを利用。
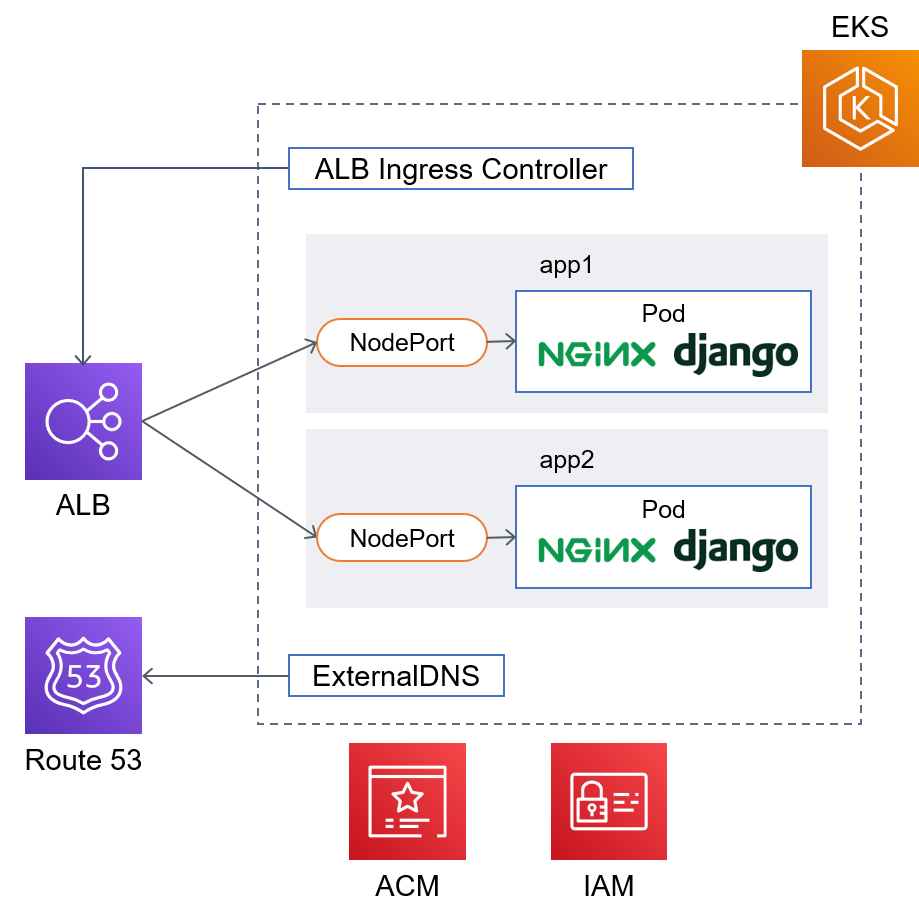
公式サイトの方法を参考にクラスタ構築。
eksctl で構築するのが便利。
eksctl create cluster \
--name test-cluster \
--version 1.14 \
--region ap-northeast-1 \
--nodegroup-name standard-workers \
--node-type t3.medium \
--nodes 2 \
--nodes-min 1 \
--nodes-max 4 \
--managed(参考)EC2インスタンスのタイプによって付与可能なIPアドレス数が異なるため、podをたくさん起動する場合はworker nodeのインスタンスタイプに注意すること。
IPアドレス数の一覧はこちら
基本は公式サイトの手順通りに実施する。
kubernetes.io/cluster/<cluster-name>:shared kubernetes.io/role/elb:1kubernetes.io/role/internal-elb:1IAMポリシーファイルをダウンロード
curl -O https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.3/docs/examples/iam-policy.jsonIAMポリシーを作成
aws iam create-policy \
--policy-name ALBIngressControllerIAMPolicy \
--policy-document file://iam-policy.jsonEKSクラスタのワーカーノードの IAM ロール名を取得
kubectl -n kube-system describe configmap aws-auth出力結果の<アカウントID>と<ロール名>を控えておく。
Name: aws-auth
Namespace: kube-system
Labels: <none>
Annotations: <none>
Data
====
mapRoles:
----
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::<アカウントID>:role/<ロール名>
username: system:node:{{EC2PrivateDNSName}}
mapUsers:
----
[]
Events: <none>aws iam attach-role-policy \
--policy-arn arn:aws:iam::<アカウントID>:policy/ALBIngressControllerIAMPolicy \
--role-name <ロール名>kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.3/docs/examples/rbac-role.yamlここは公式サイトとは違う方法でデプロイする。
公式サイトではmanifestをデプロイした後に環境に合わせて編集しているが、今回は最初にデプロイ用manifestをダウンロードし、ファイルを編集した後にデプロイする。
ALB-Ingress-Controllerのmanifestをダウンロード
curl -O https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.3/docs/examples/alb-ingress-controller.yamlManifestを編集する。以下のパラメータのコメントアウトを外し、書き換える。
spec:
containers:
- args:
- --cluster-name=test-cluster
- --aws-vpc-id=<VPC ID>
- --aws-region=ap-northeast-1(参考)VPC IDを確認するには以下のコマンドを実行する。
aws ec2 describe-vpcsデプロイ
kubectl apply -f alb-ingress-controller.yaml以下のコマンドを実行してエラーが表示されなければデプロイ成功
kubectl logs -n kube-system -f $(kubectl get po -n kube-system | egrep -o 'alb-ingress-controller[A-Za-z0-9-]+')ALBのエンドポイントを自分が管理しているRoute53にailiasとして反映させてくれる ExternalDNS というOSSがあるので使ってみる。
IAMポリシーファイルを作成。公式サイトのチュートリアルから流用
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"route53:ChangeResourceRecordSets"
],
"Resource": [
"arn:aws:route53:::hostedzone/*"
]
},
{
"Effect": "Allow",
"Action": [
"route53:ListHostedZones",
"route53:ListResourceRecordSets"
],
"Resource": [
"*"
]
}
]
}IAMポリシーを作成
aws iam create-policy \
--policy-name ExternalDNSIAMPolicy \
--policy-document file://external-dns-iam-policy.jsonaws iam attach-role-policy \
--policy-arn arn:aws:iam::<アカウントID>:policy/ExternalDNSIAMPolicy \
--role-name <ロール名>ExternalDNSのmanifestをダウンロード
curl -O https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.3/docs/examples/external-dns.yaml Manifestを編集。example.comには自分で管理しているFQDNに変更すること。ダウンロードしたファイルではpolicyオプションがupsert-onlyになっているが、これはレコード追加だけすることを表す。今回はingressの内容に合わせて適宜レコード削除もしてほしいのでpolicyオプションは使わない。
args:
- --domain-filter=example.com
#- --policy=upsert-only # コメントアウトまたは削除デプロイ
kubectl apply -f external-dns.yaml確認
kubectl logs -f $(kubectl get po | egrep -o 'external-dns[A-Za-z0-9-]+')以下のように表示されればOK
time="2019-12-13T14:48:31Z" level=info msg="Created Kubernetes client https://10.100.0.1:443"ここからようやくアプリケーションをデプロイすることができる。
まずはdeploymentとserviceとingressのmanifestを用意する。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: app1-deployment
spec:
replicas: 1
template:
metadata:
labels:
app: app1
spec:
containers:
- image: tetsis/simple-nginx-django-app
name: app1
ports:
- containerPort: 8080
env:
- name: APPLICATION_NAME
value: app1
- image: tetsis/simple-nginx-django-proxy
name: app1-proxy
ports:
- name: app1-port
containerPort: 80apiVersion: v1
kind: Service
metadata:
name: app1-service
spec:
ports:
- port: 80
targetPort: app1-port
protocol: TCP
type: NodePort
selector:
app: app1apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
labels:
app: ingress
spec:
rules:
- host: app1.example.com
http:
paths:
- path: /*
backend:
serviceName: app1-service
servicePort: 80example.comには自分が所有するドメインを指定する。
kubectl apply -f app1-deployment.yaml
kubectl apply -f app1-service.yaml
kubectl apply -f ingress.yamlkubectl get ingressNAME HOSTS ADDRESS PORTS AGE
ingress app1.example.com d7f12bb1-default-ingress-e8c7-1478980459.ap-northeast-1.elb.amazonaws.com 80 38sコンソール画面もしくは以下のコマンドでAliasレコードが作成されていることを確認する。
aws route53 list-resource-record-sets --hosted-zone-id /hostedzone/<ホストゾーンID>ALBの起動とRoute 53のDNSレコード情報が反映されるまで少し待って、ブラウザで「http://app1.example.com」にアクセスし、以下のように表示されればOK。
(example.comは自分のドメインを指定)
This application is "app1".
さっきはapp1.example.comというドメインでアプリケーションをデプロイしたが、次はapp2.example.comドメインでアプリケーションを追加デプロする。
deploymentとserviceはapp1と同様にmanifestを作成する。
ingressについては 、app1とapp2で同じALBを使うので先程作成したmanifestに追記する。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: app2-deployment
spec:
replicas: 1
template:
metadata:
labels:
app: app2
spec:
containers:
- image: tetsis/simple-nginx-django-app
name: app2
ports:
- containerPort: 8080
env:
- name: APPLICATION_NAME
value: app2
- image: tetsis/simple-nginx-django-proxy
name: app2-proxy
ports:
- name: app2-port
containerPort: 80apiVersion: v1
kind: Service
metadata:
name: app2-service
spec:
ports:
- port: 80
targetPort: app2-port
protocol: TCP
type: NodePort
selector:
app: app2apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
labels:
app: ingress
spec:
rules:
- host: app1.example.com
http:
paths:
- path: /*
backend:
serviceName: app1-service
servicePort: 80
- host: app2.example.com
http:
paths:
- path: /*
backend:
serviceName: app2-service
servicePort: 80kubectl apply -f app2-deployment.yaml
kubectl apply -f app2-service.yaml
kubectl apply -f ingress.yamlブラウザで「http://app2.example.com」にアクセスして以下の文字が表示されればOK。(もちろんドメインは環境に合わせること)
This application is "app2".
公式ページを参考に、ingress.yamlの annotations 句に一行追加する。
尚、使用するドメインのSSL証明書は事前にACMで発行しておく。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]' # 追加
labels:
app: ingress
spec:
rules:
- host: app1.example.com
http:
paths:
- path: /*
backend:
serviceName: app1-service
servicePort: 80
- host: app2.example.com
http:
paths:
- path: /*
backend:
serviceName: app2-service
servicePort: 80忘れずにapplyする。
kubectl apply -f ingress.yamlブラウザで「https://app1.example.com」、 「https://app2.example.com」 にアクセスして、ページが表示されることを確認する。
EKSクラスタは起動しておくだけでお金がかかるので、検証利用の場合は忘れずにクラスタを削除を実施する。
K8sリソースを削除
kubectl delete -f ingress.yaml
kubectl delete -f app1-service.yaml
kubectl delete -f app2-service.yaml
kubectl delete -f app1-deployment.yaml
kubectl delete -f app2-deployment.yamlIAMポリシーをデタッチ
aws iam detach-role-policy --policy-arn arn:aws:iam::<アカウントID>:policy/ExternalDNSIAMPolicy --role-name <ロール名>
aws iam detach-role-policy --policy-arn arn:aws:iam::<アカウントID>:policy/ALBIngressControllerIAMPolicy --role-name <ロール名>IAMポリシーを削除
aws iam delete-policy --policy-arn arn:aws:iam::<アカウントID>:policy/ExternalDNSIAMPolicy
aws iam delete-policy --policy-arn arn:aws:iam::<アカウントID>:policy/ALBIngressControllerIAMPolicyEKSクラスタを削除
eksctl delete cluster --region=ap-northeast-1 --name=test-cluster前回の記事の続き。前回はオンプレ(自分が管理するVM)でWebSocketサーバをスケールアウトする方法を書いたが、本稿はクラウド(AWS)のマネージドサービスを使った方法について書く。
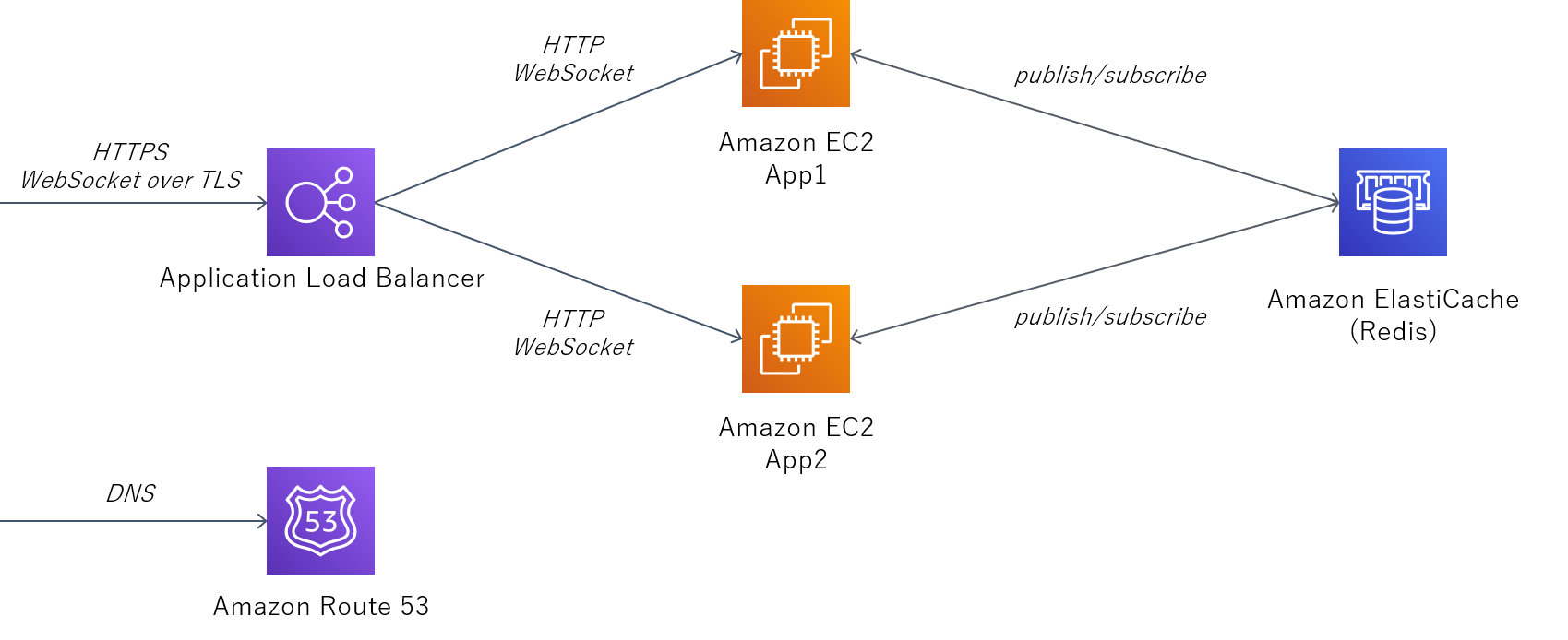
ロードバランサーにはApplication Load Balancer (ALB) を利用する。
ALBの後段にはアプリケーションサーバのEC2を二つ配置する。ALBでSSL終端するため、ALB-EC2間はHTTP/WebSocketで通信する。
EC2間の情報連携用のPub/SubにはAmazon ElastiCache for Redisを利用する。
認証局により証明されたSSL証明書を発行するためRoute53を使ってDNS認証する。
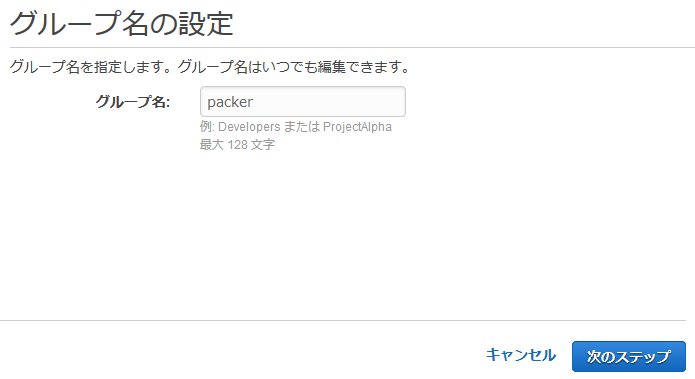
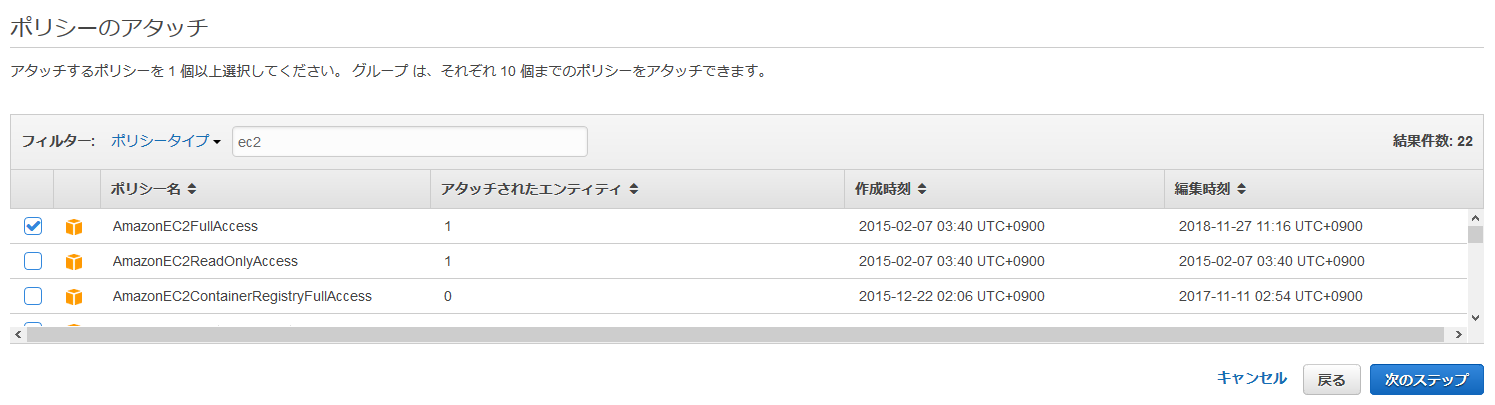
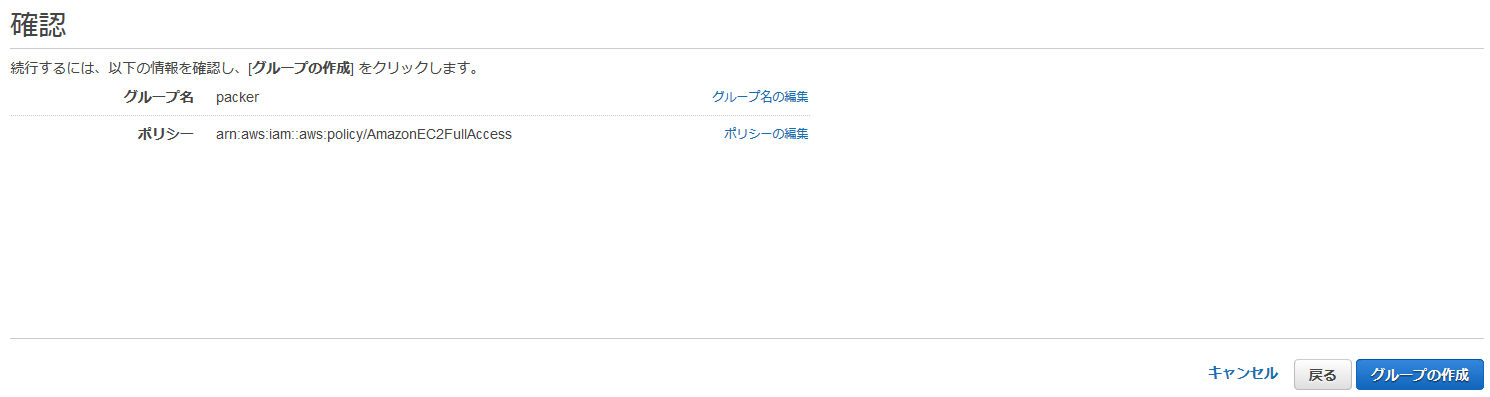
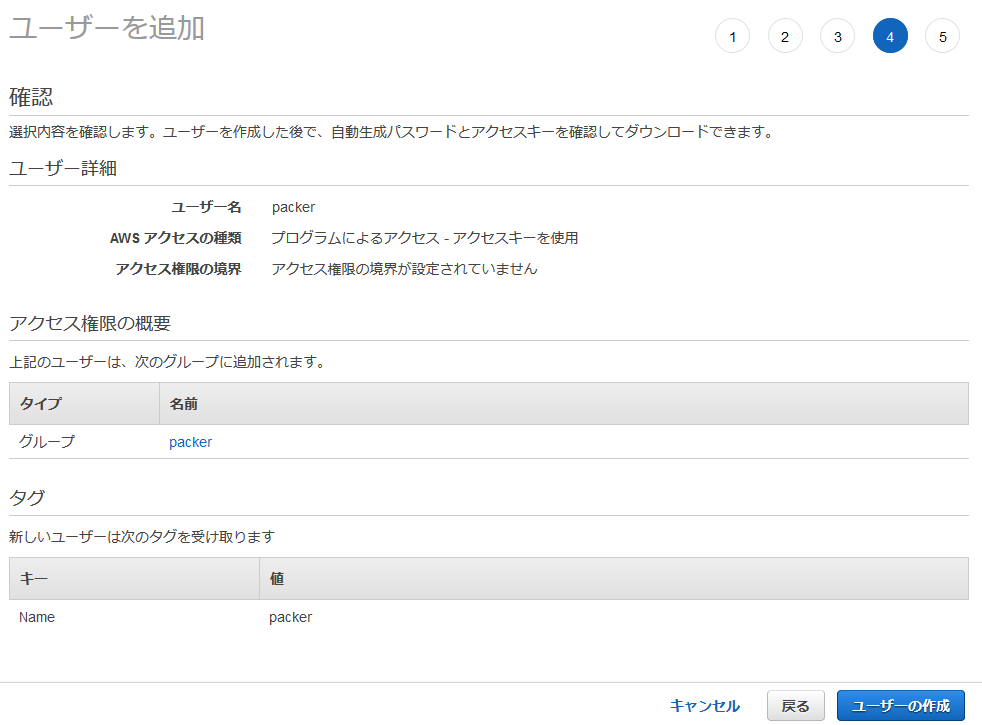
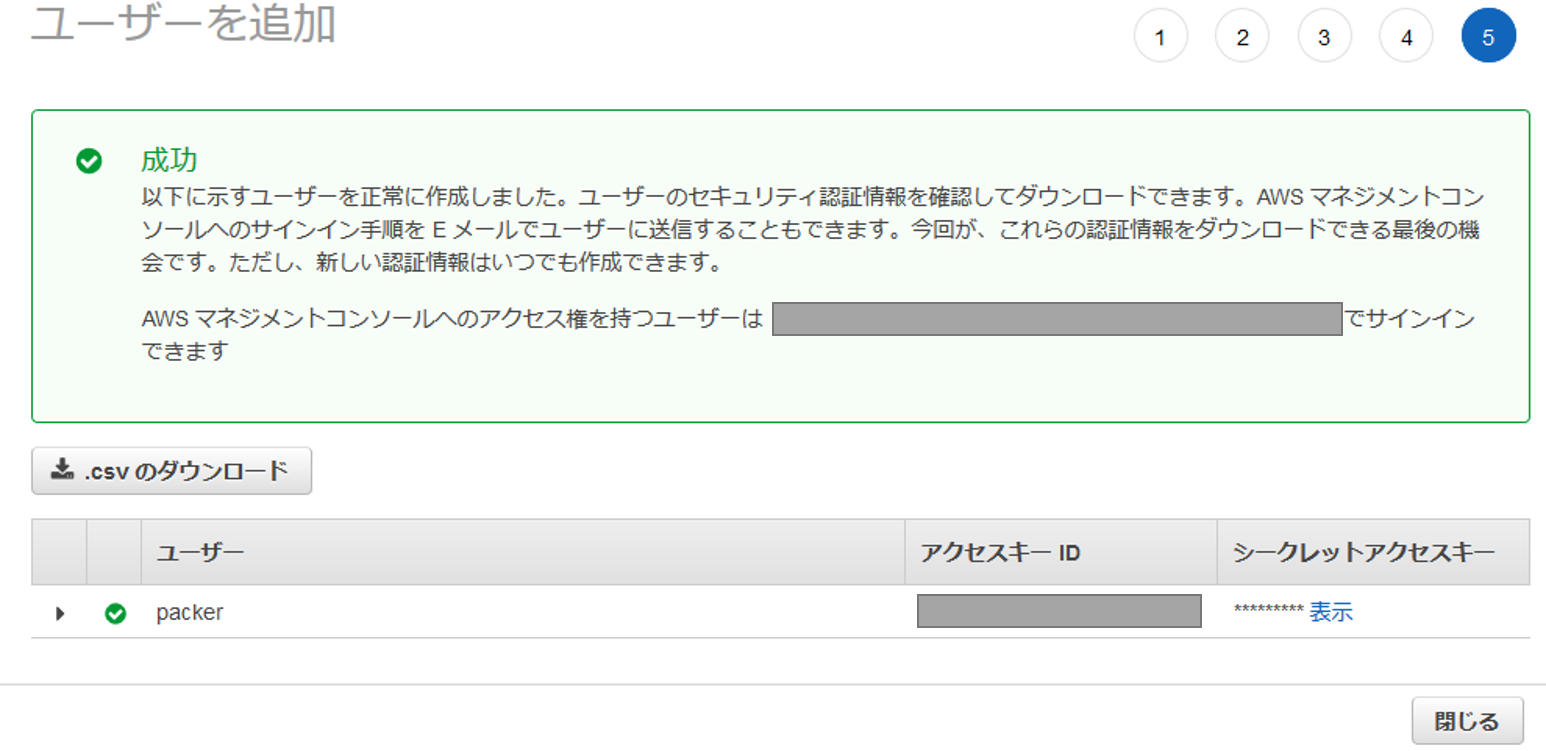
以下は執筆時点のコマンド。最新のインストール手順についてはこちらを参照。
# curl -O https://releases.hashicorp.com/packer/1.4.2/packer_1.4.2_linux_amd64.zip
# unzip packer_1.4.2_linux_amd64.zip
# mv packer /usr/local/sbin/
# packer version
Packer v1.4.2認証情報を環境変数に書き込む。
IAMユーザ作成時にメモしたpackerユーザのアクセスキーIDとシークレットアクセスキーを環境変数に書き込む。
export AWS_ACCESS_KEY_ID=xxxx
export AWS_SECRET_ACCESS_KEY=xxxx 以下のjsonファイルを作成する。
DockerとDocker Composeのインストール、ソースコードのダウンロード、Dockerイメージの作成をAMIの中で済ませておく。
{
"variables": {
"aws_access_key": "{{env `AWS_ACCESS_KEY_ID`}}",
"aws_secret_key": "{{env `AWS_SECRET_ACCESS_KEY`}}",
"region": "ap-northeast-1"
},
"builders": [
{
"access_key": "{{user `aws_access_key`}}",
"ami_name": "packer-linux-aws-demo-{{timestamp}}",
"instance_type": "t2.micro",
"region": "{{user `region`}}",
"secret_key": "{{user `aws_secret_key`}}",
"source_ami_filter": {
"filters": {
"name": "amzn2-ami-hvm-*-x86_64-gp2"
},
"owners": ["137112412989"],
"most_recent": true
},
"ssh_username": "ec2-user",
"type": "amazon-ebs"
}
],
"provisioners": [{
"type": "shell",
"inline": [
"sleep 30",
"sudo yum -y install docker git",
"sudo systemctl start docker",
"sudo systemctl enable docker",
"sudo curl -L \"https://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname -s)-$(uname -m)\" -o /usr/local/bin/docker-compose",
"sudo chmod +x /usr/local/bin/docker-compose",
"git clone https://github.com/tetsis/simple-chat.git",
"sudo cp -r simple-chat /root/",
"sudo /usr/local/bin/docker-compose -f /root/simple-chat/docker-compose.yml build"
]
}]
}packer validate コマンドでjsonファイルの構文チェックをする。
# packer validate app-server.json
Template validated successfully.Template validated successfully. が表示されればOK。
packer build コマンドでAMIを作成する。
最終行の ami-... をメモしておく。(ここでは xxxx としているが、実際は英数字の文字列)
# packer build app-server.json
...
==> Builds finished. The artifacts of successful builds are:
--> amazon-ebs: AMIs were created:
ap-northeast-1: ami-xxxxEC2インスタンス内でawsコマンドを実行するため、ロールを作成する。
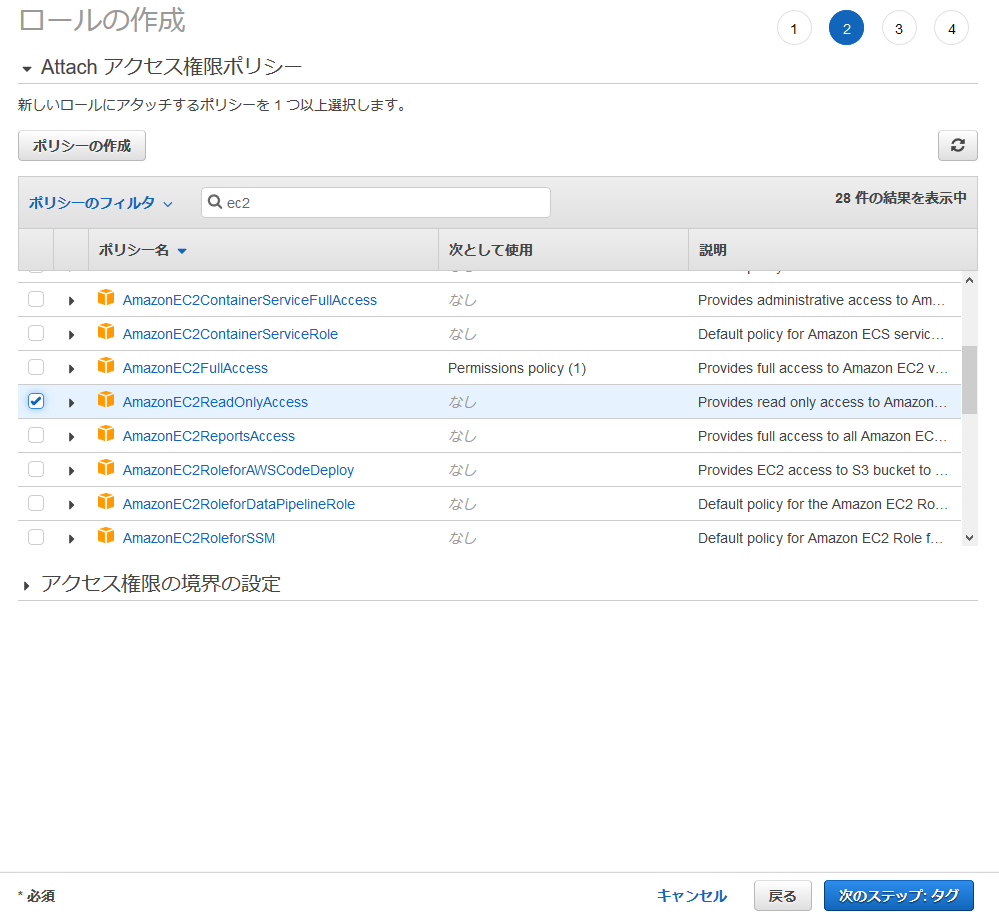
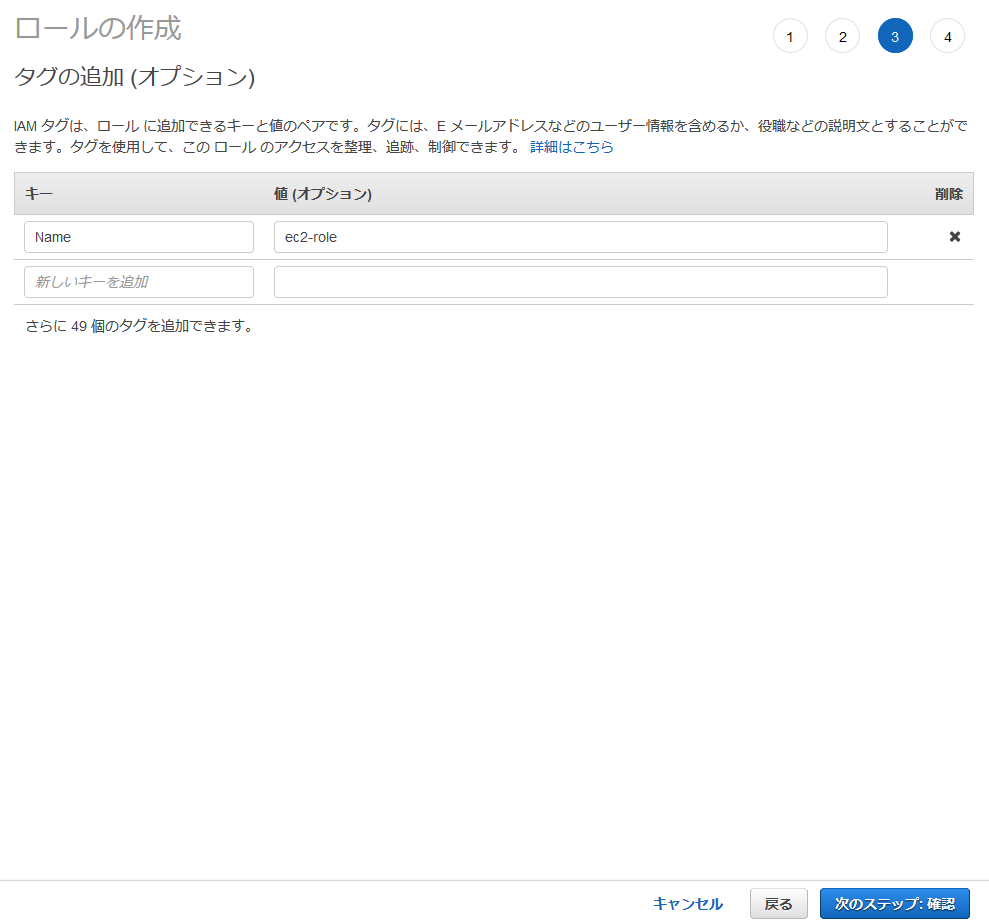
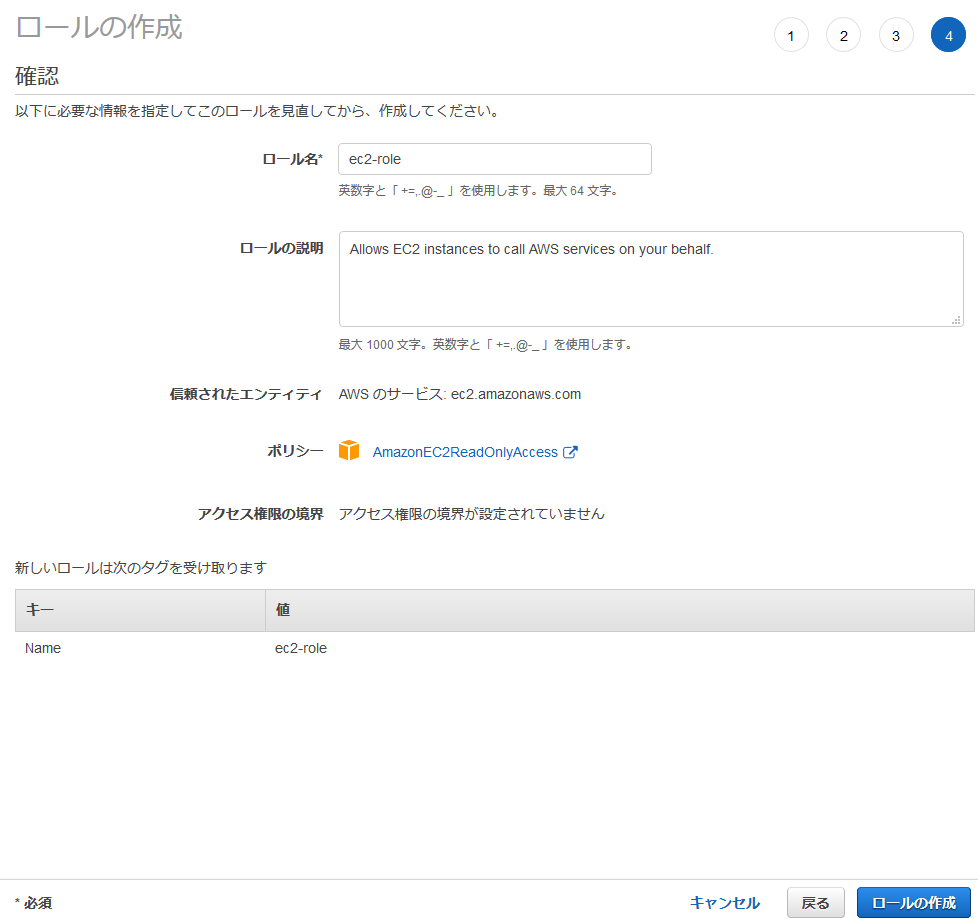
Packer用にIAMグループとIAMユーザを作ったのと同様にTerraform用にも作成する。
作り方はPackerの時と同じなので詳細については省略する。
Packerとの違いはIAMグループにアタッチするポリシーで、今回の例では以下の5つのポリシーをアタッチする。
以下は執筆時点のコマンド。最新のインストール手順についてはこちらを参照。
# curl -O https://releases.hashicorp.com/terraform/0.12.5/terraform_0.12.3_linux_amd64.zip
# unzip terraform_0.12.3_linux_amd64.zip
# mv terraform /usr/local/sbin/
# terraform version
Terraform v0.12.3 Terraformの.tfファイルはこちらを参照。
公開したくない情報は環境変数で設定してから terraform plan で正常性を確認して、 terraform apply でリソース作成を実行する。
(環境変数は ~/.bashrc 等に書いておいても良い)
# export TF_VAR_access_key=xxxx
# export TF_VAR_secret_key=xxxx
# export TF_VAR_allow_ip=x.x.x.x/32
# export TF_VAR_ami=ami-xxxx (Packerで作成したAMI)
# export TF_VAR_app_fqdn=simple-chat.xx.xx
# export TF_VAR_zone_id=xxxx (自分がホストしているドメインのZONE ID)
# cd /dir/to/terraform
# ls
aws_acm.tf aws_alb.tf aws_ec2.tf aws_elasticache.tf aws_r53.tf aws_sg.tf aws.tf aws_tg.tf aws_variables.tf aws_vpc.tf terraform.tfvars
# terraform plan
...
Plan: 25 to add, 0 to change, 0 to destroy.
...
# terrafrom apply
...
Enter a value: yes
...
(リソース作成。しばらく待つ)
Apply complete! Resources: 25 added, 0 changed, 0 destroyed. (「Apply complete!」が表示されたらリソース作成は正常に完了している。)TerraformのEC2インスタンス作成ファイルで以下のような記述があるが、このuser_dataの作成方法について書いておく。
user_data = <<EOF
IyE...
EOF user_dataはEC2インスタンス起動時の処理をシェルスクリプト形式で書いたものをbase64エンコードしたものである。
シェルスクリプトの中身はEC2インスタンスを起動してからでないと決まらないパラメータをタグから取得してアプリケーションの設定ファイルに書き込む、という操作を行っている。
参考のためbase64変換前のシェルスクリプトを記載する。
# !/bin/sh
aws="/usr/bin/aws --region ap-northeast-1"
logger="logger -t $0"
get_instance_id()
{
instance_id=$(curl -s http://169.254.169.254/latest/meta-data/instance-id)
}
get_redis_endpoint()
{
redis_endpoint=$(${aws} ec2 describe-instances \
--instance-id ${instance_id} \
--query 'Reservations[].Instances[].Tags[?Key==`Redis_endpoint`].Value' \
--output text)
}
set_redis_endpoint()
{
sed -i -e "s/REDIS_HOST.*$/REDIS_HOST: '${redis_endpoint}'/g" docker-compose.yml
}
${logger} "start $0"
sleep 60
${logger} "get info"
get_instance_id
get_redis_endpoint
${logger} "set environment"
cd /root/simple-chat
set_redis_endpoint
${logger} "run app"
docker-compose up -d
${logger} "finished $0"
exit 0 Webブラウザで https://(環境変数TF_VAR_app_fqdnに設定したFQDN) にアクセスする。
simple-chatの画面が表示され、テキストボックスに入力した結果がテキストエリアに表示されたら正常に動作している。
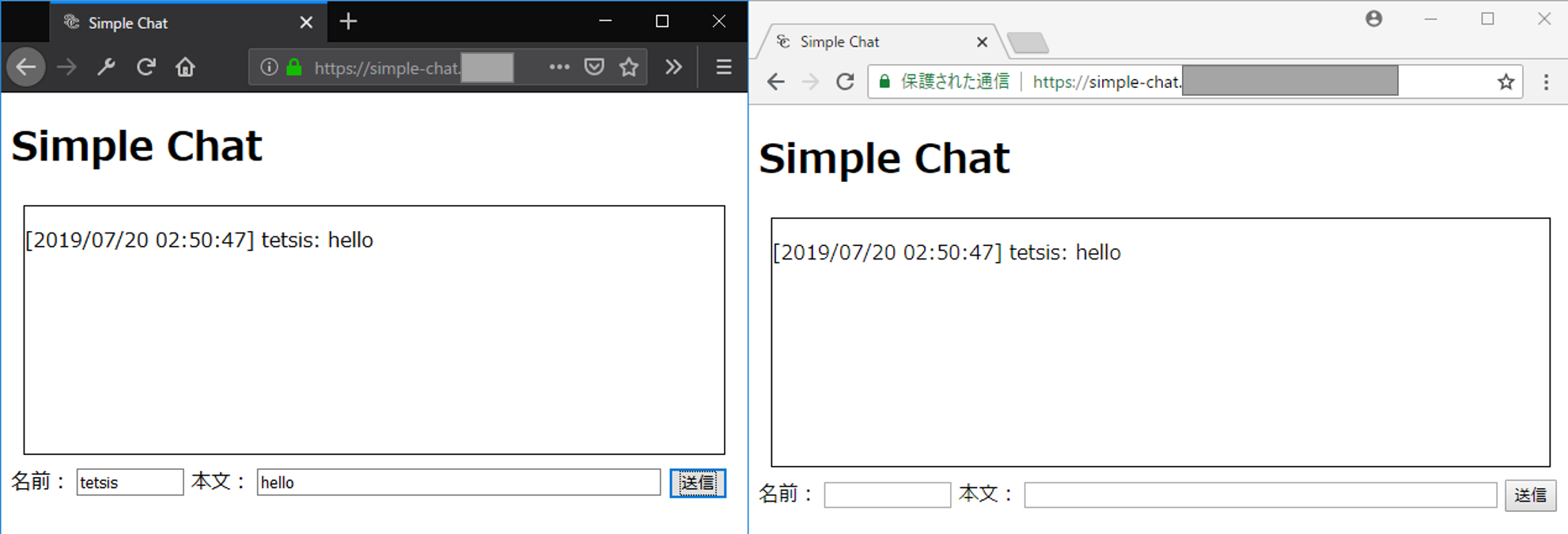
検証が終わったら忘れずにリソースを削除する。
# terraform destroy
...
Enter a value: yes
...スケーラブルなWebサービスのよくある設計はWebサーバの前段にロードバランサーを設置し後段にWebサーバを複数台配置するというものである。通常のWebサービスはステートレスなHTTP(もしくはHTTPS)通信のためこの方式で問題なく稼働する。
しかし、ステートフルなWebSocket通信においては以下の課題が存在する。
そこで本稿では以下の方法でこの2つの課題の解決を試みる。
この方法をオンプレミスで実現する方法を作ってみたので備忘録で残しておく。ソースコードはこちら
別記事でクラウド(AWS)で実装したときの記事も書く予定。
今回は簡単なチャットアプリを作る。アプリの動作イメージは以下の通り。
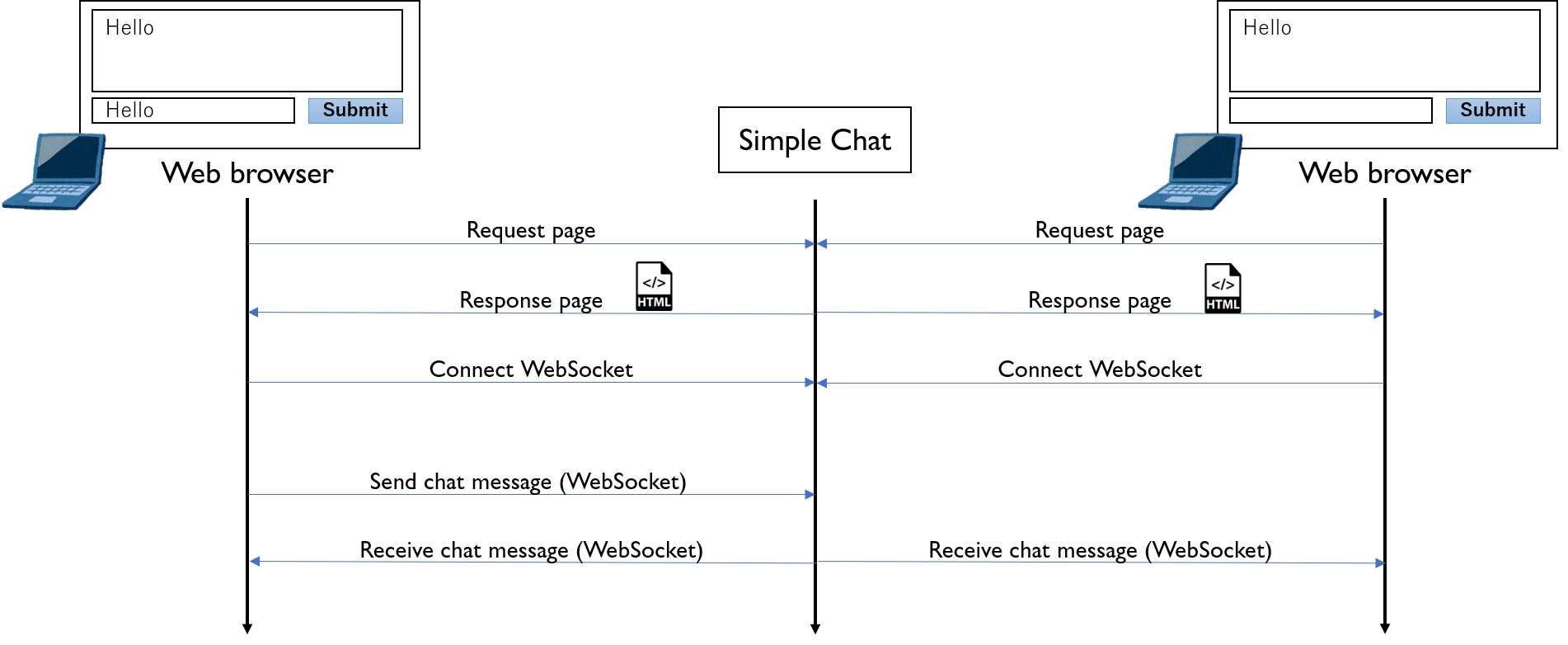
ロードバランサーにはHAProxyを利用する。特別な設定をしなくてもWebSocketのセッションを認識してルーティングしてくれるみたい。(ちゃんと設定しようとするとこちらの記事にあるようにタイムアウトを個別に設定する必要がありそう。本稿ではデフォルト設定) また、SSLオフロードによりロードバランサーへのアクセスにはHTTPS/WebSocket over TLSを使用し、後段のサーバとはHTTP/WebSocketで通信する。
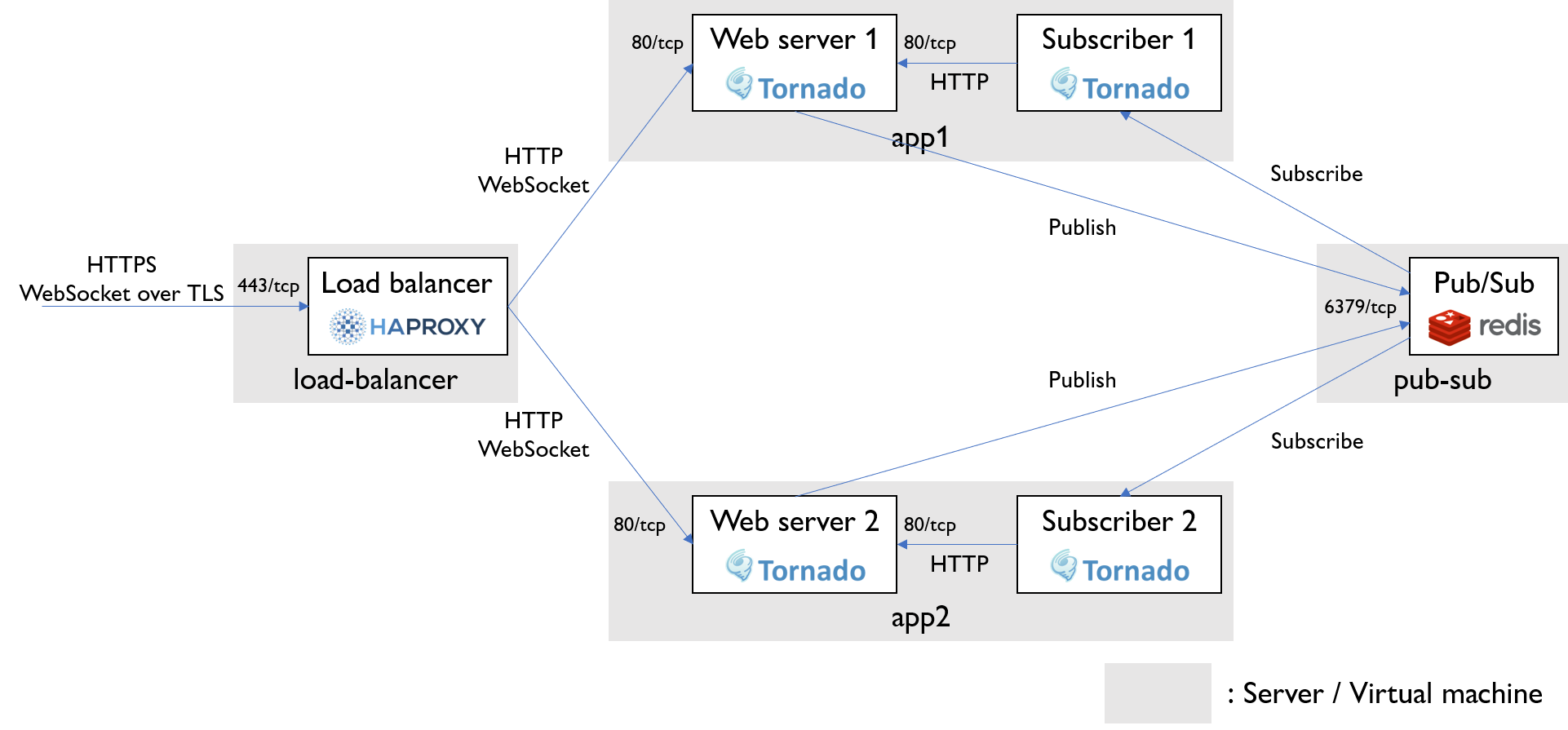
Pub/SubにはRedisを利用する。
アプリサーバにはWebSocketにも対応したTornadoを採用した。Webサーバプロセスはクライアントからメッセージを受信するとPub/Subにpublishする。また、Pub/Subをsubscribeするプロセスも動かしておいてsubscribeの結果をHTTP経由で自サーバのWebサーバプロセスに伝える。
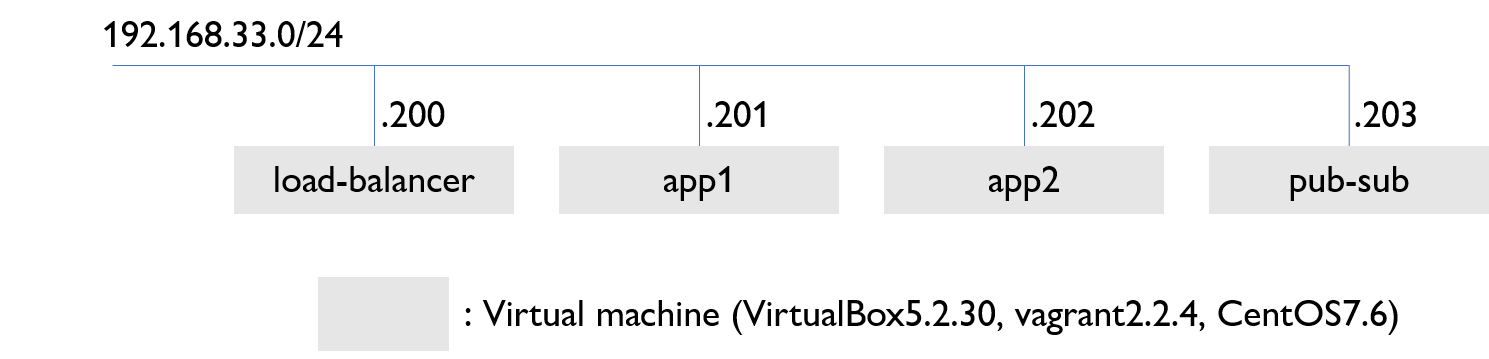
同一サブネットにロードバランサー、アプリケーションサーバ2台、Pub/Subサーバの合計4台のサーバを配置する。今回の検証ではサーバはVirtualBoxのVMを利用し、vagrantで管理している。ゲストOSはCentOS。
HAProxyをインストール
yum -y install haproxy/etc/haproxy/haproxy.cfg を編集
frontend ssl_proxy
mode http
bind *:443 ssl crt /etc/haproxy/server.pem
server app1 192.168.33.201:80 check
server app2 192.168.33.202:80 checkサーバ証明書 /etc/haproxy/server.pem を作成
普通は秘密鍵と証明書は別ファイルにすることが多いが、HAProxyでは一つのファイルにまとめる必要がある。
以下の例では秘密鍵(server.key)と自己証明書(server.crt)を作り、この2つのファイルをくっつけたserver.pemを作っている。
openssl genrsa 2048 > server.key
openssl req -new -key server.key > server.csr
openssl x509 -days 3650 -req -signkey server.key < server.csr > server.crt
cat server.key > /etc/haproxy/server.pem
cat server.crt >> /etc/haproxy/server.pemサーバプロセス起動
systemctl start haproxy
systemctl enable haproxyRedisをインストール
yum -y install epel-release
yum -y install redis/etc/redis.conf を編集
bind 192.168.33.203サーバプロセス起動
systemctl start redis
systemctl enable redisまずはソースコードをダウンロード
git pull https://github.com/tetsis/simple-chat.git
cd simple-chat諸々インストール
yum install -y https://centos7.iuscommunity.org/ius-release.rpm
yum install python36u python36u-libs python36u-devel python36u-pip
pip3.6 install -r requirements.txtサーバプロセス起動
python3.6 src/app.py | python3.6 src/subscribe.py諸々インストール
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum -y install docker-ce docker-ce-cli containerd.io
systemctl start docker
systemctl enable docker
curl -L "https://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-composeサーバプロセス起動
docker-compose build --no-cache
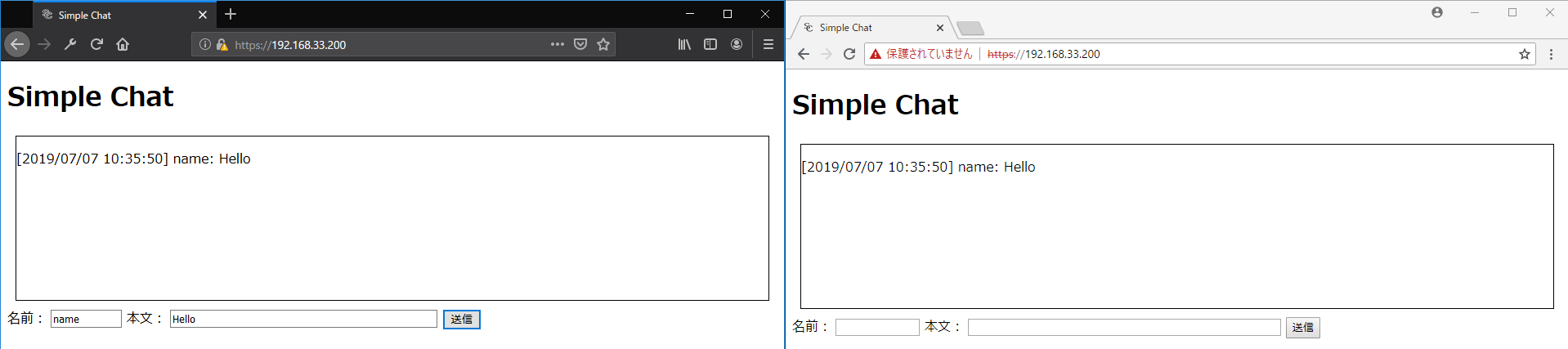
docker-compose up -d2つのブラウザでhttps://192.168.33.200にアクセスするとチャット画面が表示される。(192.168.33.200はロードバランサーのIPアドレス)
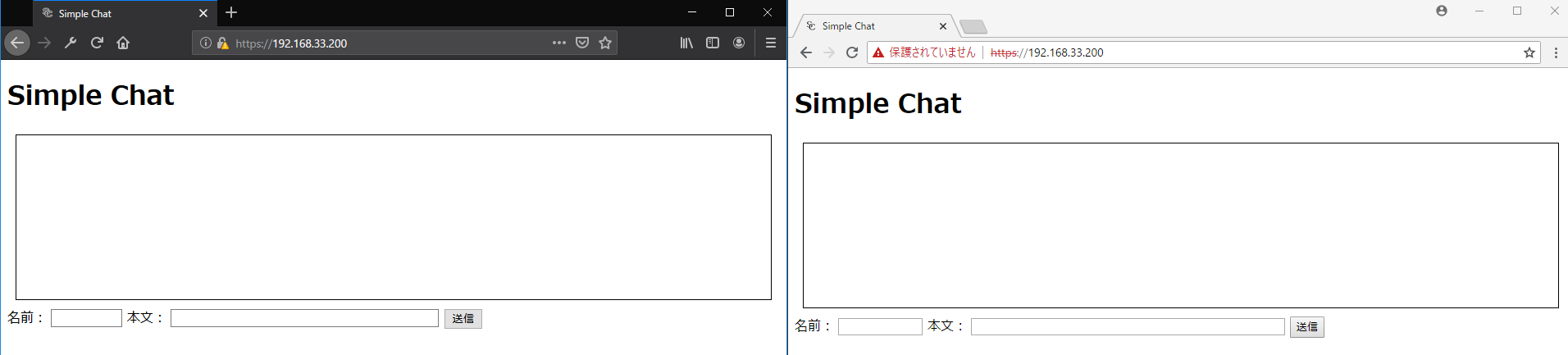
片方のブラウザからメッセージを送信すると、両方のボックスにメッセージが表示される。(下図では左のブラウザで「Hello」と入力して「送信」ボタンを押すと、もう一つのブラウザにも「Hello」と表示される)