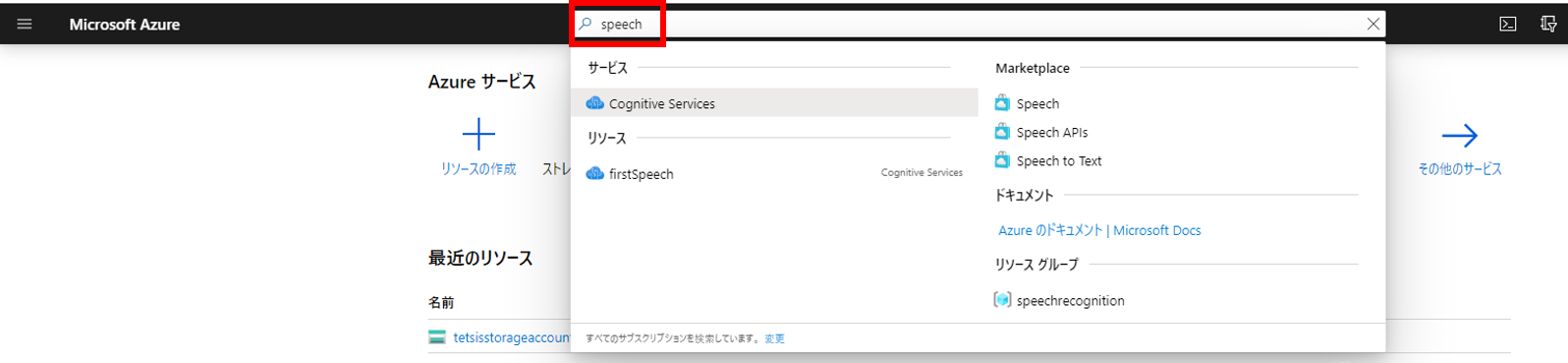
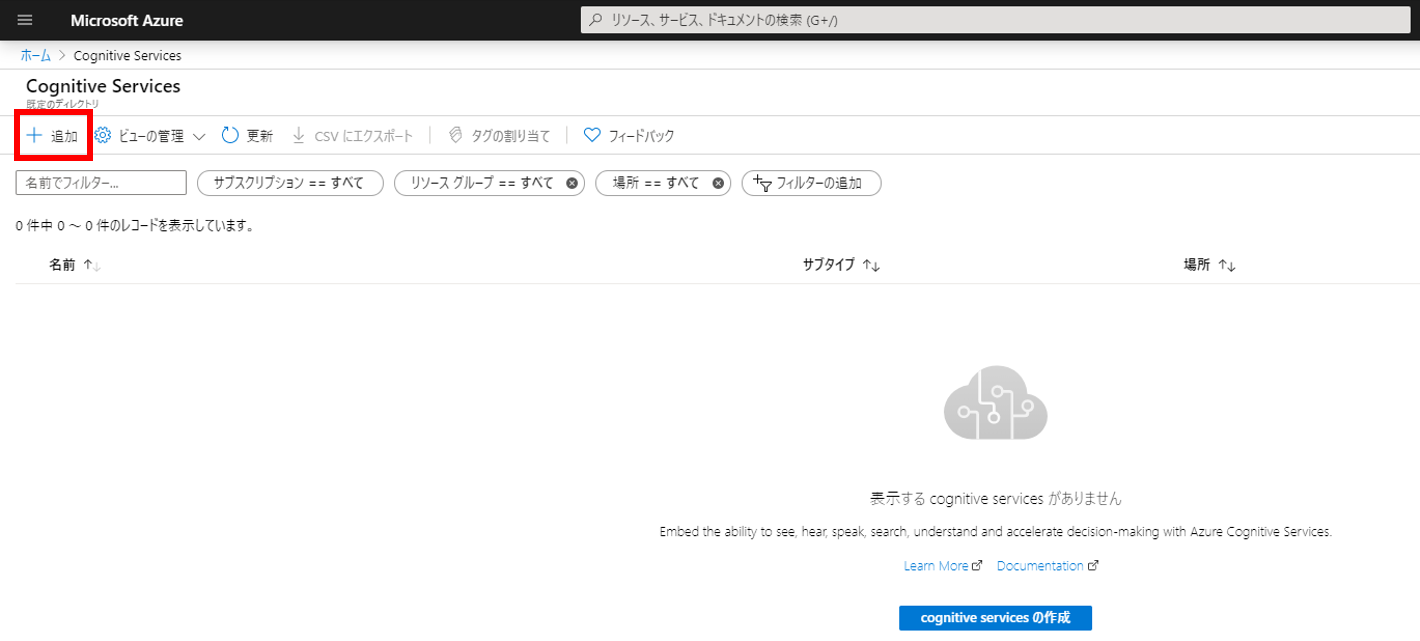
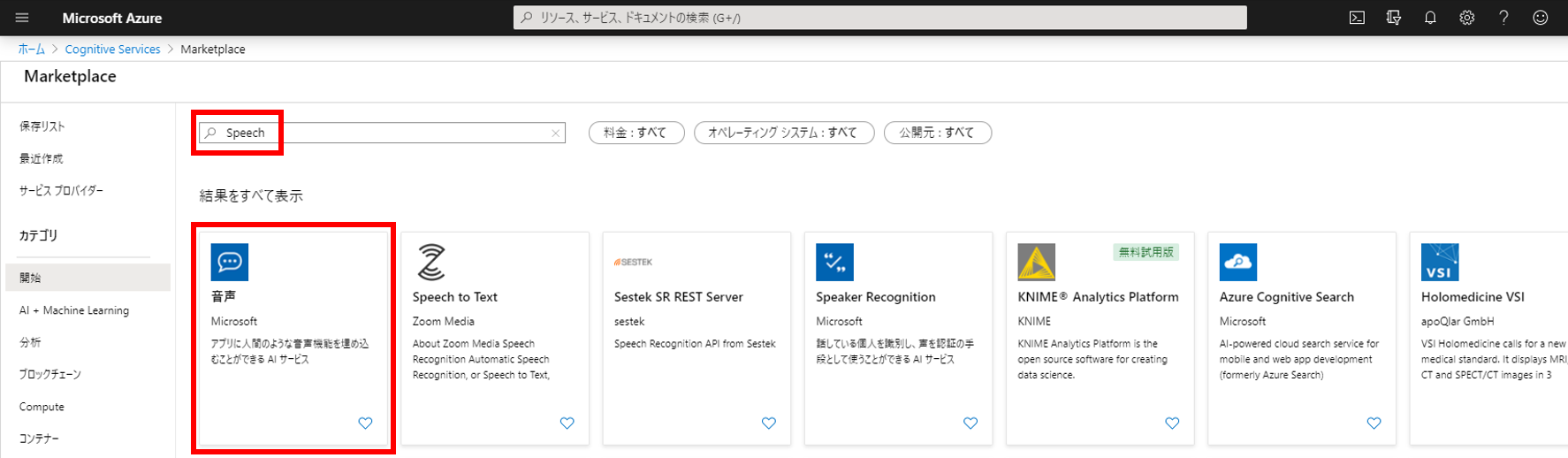
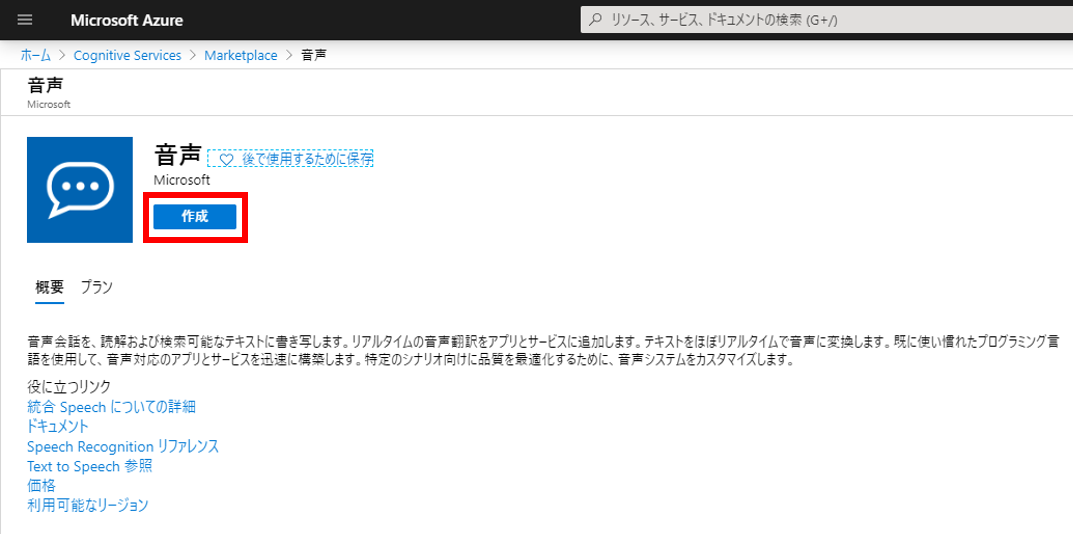
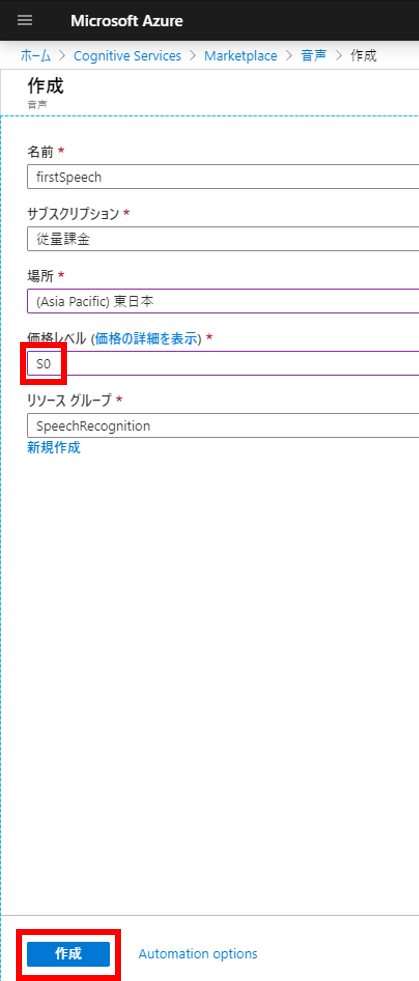
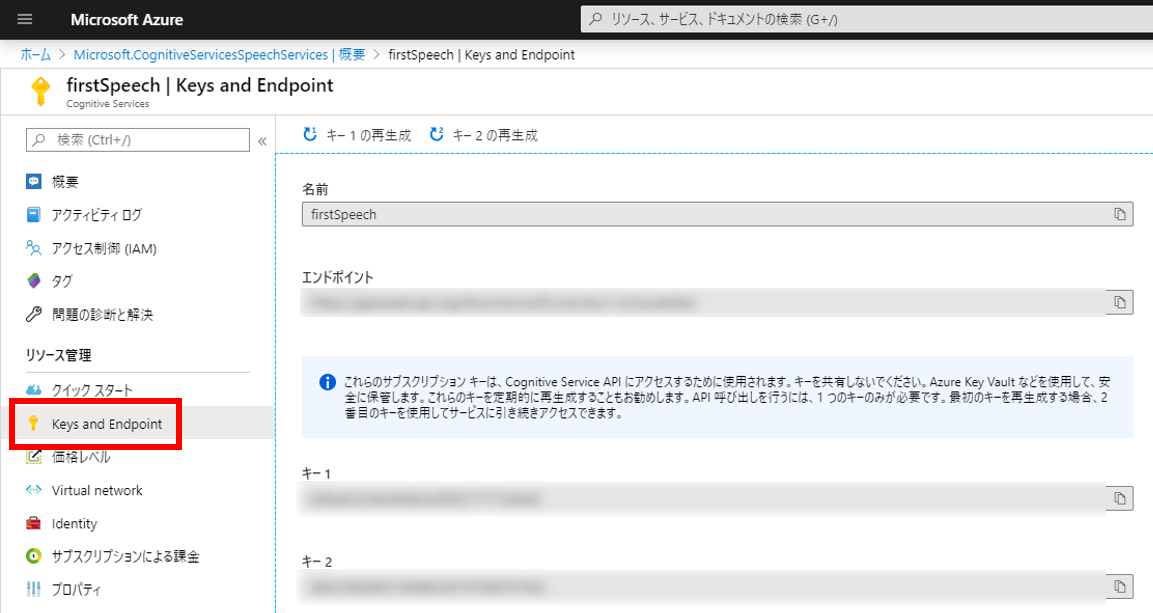
AWSの音声をテキストに変換(文字起こし)してくれるサービス Amazon Transcribeを使ってみたので備忘録に残しておく。TranscribeはS3にある音声ファイルを指定すると文字起こししてくれて、文字起こしの結果をS3にアップロードしてくれる。
処理の流れは以下のようにした。
- STEP1: ローカルにある音声ファイルをS3にアップロード
- STEP2: Transcribeに文字起こし処理を依頼
- STEP3: 定期的に処理結果を確認
- STEP4: 処理が完了したら処理結果のURLを取得
- STEP5: 処理結果をS3からダウンロードし結果を表示 (Pyhon SDK)
基本的には前回のAzure Speech Servicesと同じ流れ。AWSはPython SDKが充実していてS3、Transcribeの処理どちらもSDKで実装できたのが良かった。
準備
S3バケットを作成
TranscribeではS3にアップロードされている音声ファイルを利用するためにS3バケットを作成する。まずはS3のページにアクセスし、右上の「バケットを作成」をクリック。

バケット名を入力する。今回は「speech.tetsis.com」にした。
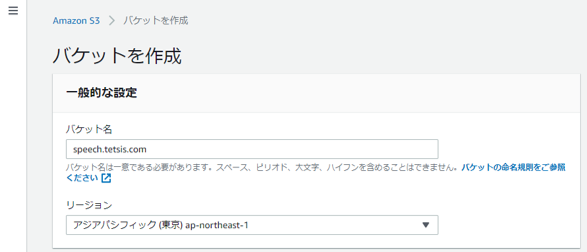
そのまま「バケットを作成」をクリック。
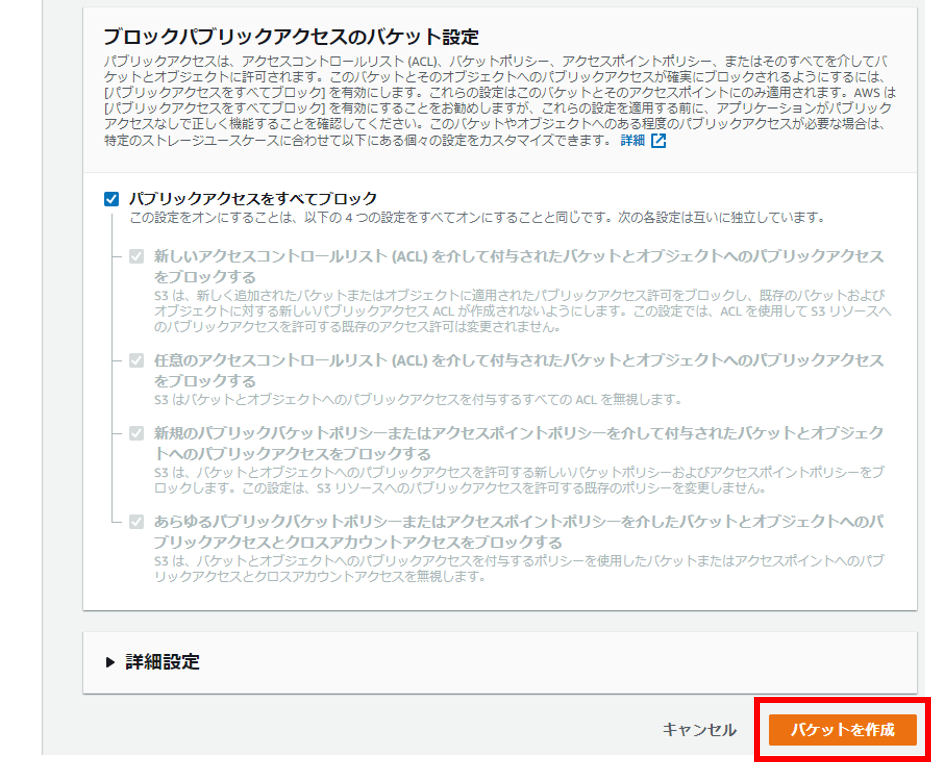
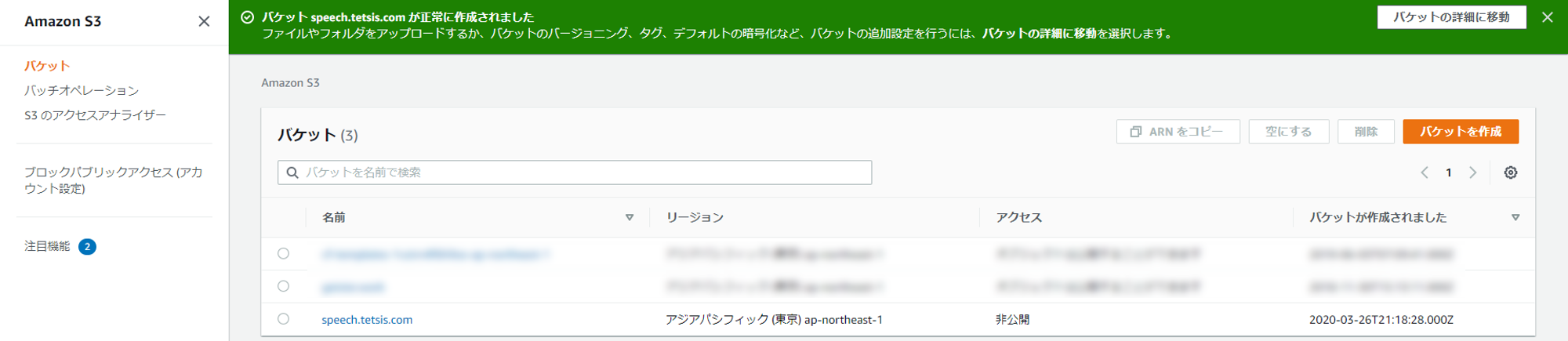
バケット「speech.tetsis.com」が作成された。
IAMユーザーを作成
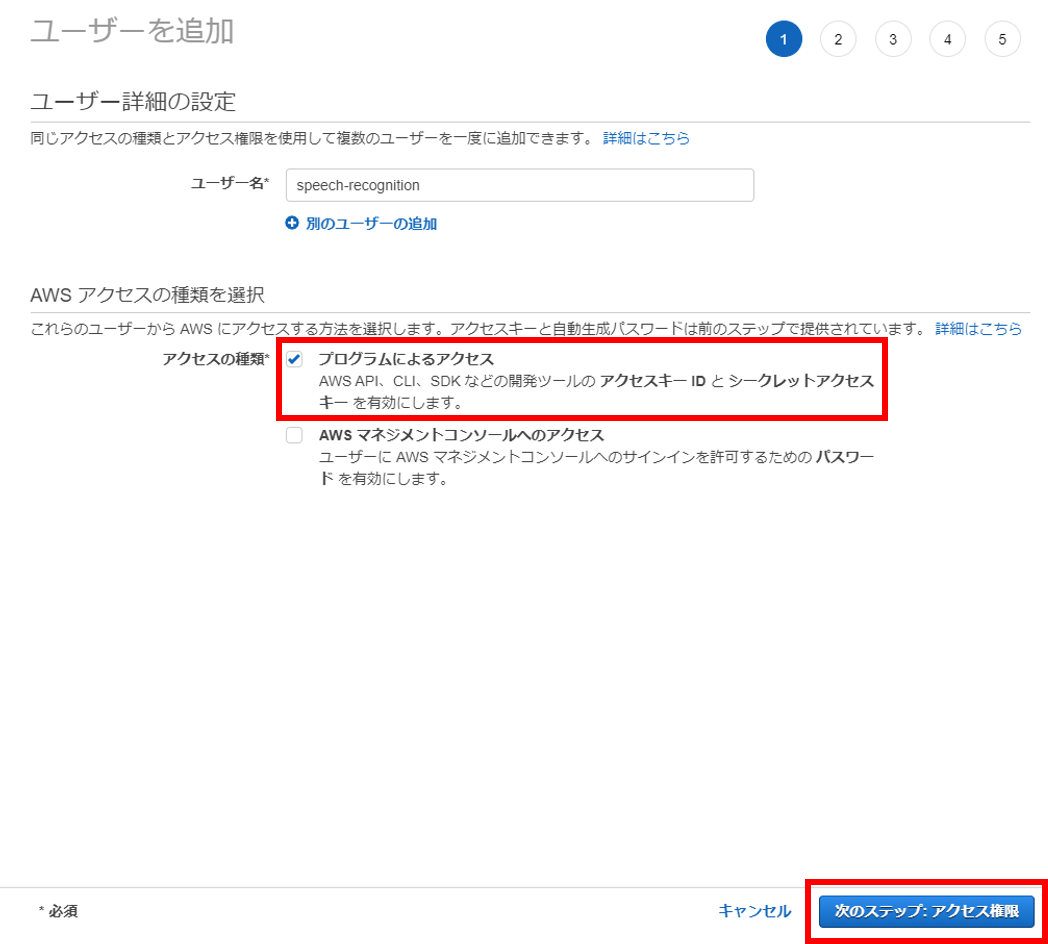
Python SDKでAWSのリソースを操作するためのIAMユーザーを作成する。まずはIAMユーザーページにアクセスし、「ユーザーを追加」をクリック。

ユーザー名は「speech-recognition」にした。「プログラムによるアクセス」をチェックし、「次のステップ:アクセス権限」をクリック。
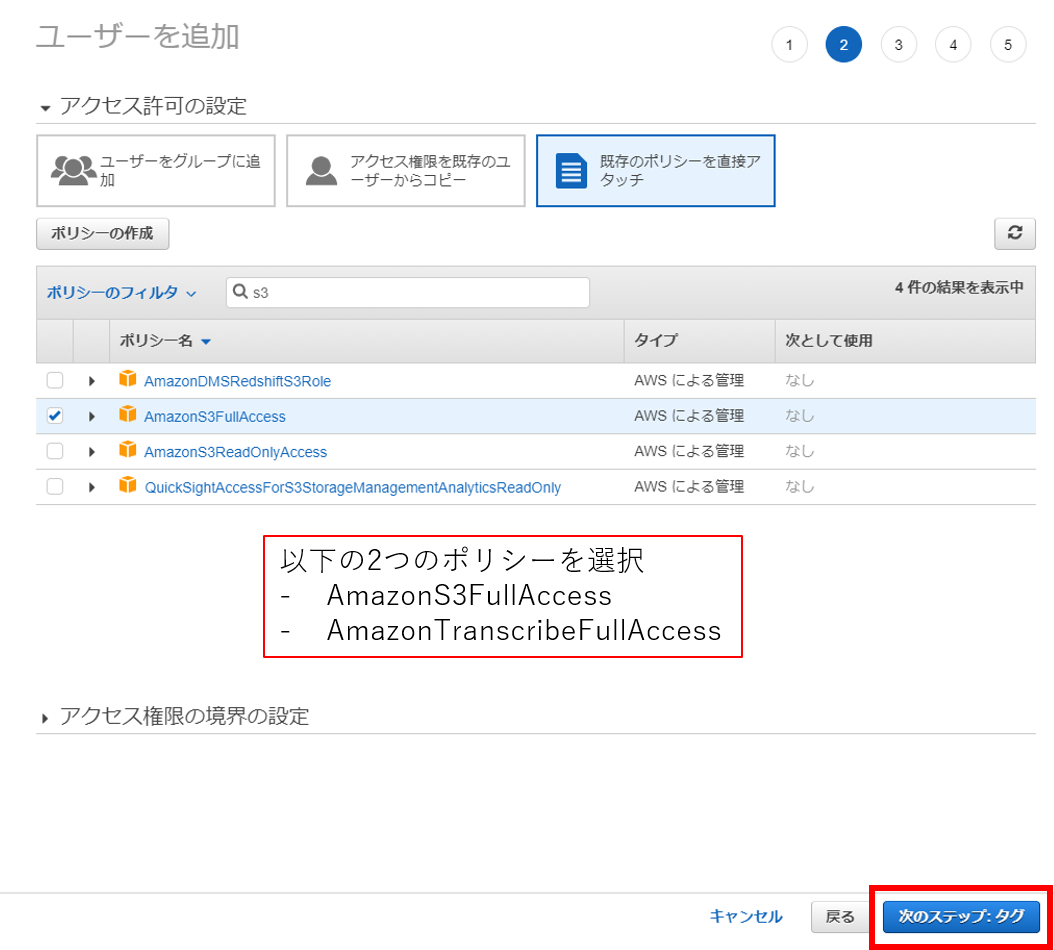
「AmazonS3FullAccess」と「AmazonTranscribeFullAccess」をチェックして、「次のステップ:タグ」をクリック。
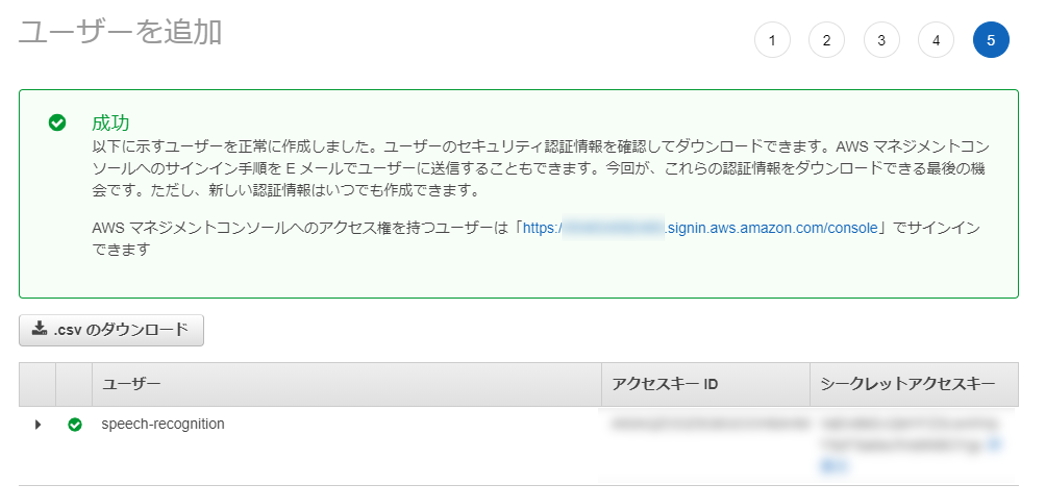
あとはそのまま進める。IAMユーザーが作成できたら「アクセスキーID」と「シークレットアクセスキー」が表示されるのでメモしておく。
awsコマンドをインストール
公式ページを参考にawsコマンドをインストールする。詳細な方法は割愛する。
awsコマンドで認証情報を設定
awsコマンドがインストールできたら認証情報を設定する。以下のコマンドを実行し、先ほどメモしておいた「アクセスキーID」と「シークレットアクセスキー」を入力する。
aws configurePythonコーディング
今回は以下の環境でPythonを実行する。
– OS: Windows 10
– Python 3.8.1
– pip 20.0.2
最初にPython SDKであるboto3をインストールしておく。
pip install boto3今回は一つのファイル(aws_speech.py)で実装していく。汎用性の高い関数として実装した「関数コード」と、「main関数コード」の2パートに分けて紹介する。
まずはファイルの先頭にライブラリをインポートするimport文を記述する。
# -*- coding: utf-8 -*-
import os
import uuid
import argparse
import logging
import re
import time
import json
import boto3
from botocore.exceptions import ClientErrorSTEP1: ローカルにある音声ファイルをS3にアップロード
関数コード
この関数は公式ドキュメントを参考にした。
def upload_file(bucket_name, local_path, local_file_name):
root_ext_pair = os.path.splitext(local_file_name)
object_name = root_ext_pair[0] + str(uuid.uuid4()) + root_ext_pair[1] # S3バケット内で唯一のオブジェクト名になるようにランダム文字列(UUID)を挿入しておく
upload_file_path = os.path.join(local_path, local_file_name)
# Upload the file
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(upload_file_path, bucket_name, object_name)
except ClientError as e:
print(e)
return None
print("\nUploading " + local_file_name +" to S3 as object:\n\t" + object_name)
return object_namemain関数コード
S3バケット名は環境変数で指定するようにした。音声ファイルと言語はプログラム実行時に引数で指定するようにした。
if __name__ == "__main__":
bucket_name = os.getenv("S3_BUCKET_NAME")
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", type=argparse.FileType("r", encoding="UTF-8"), required=True)
parser.add_argument("-l", "--locale", help="e.g. \"en-US\" or \"ja-JP\"", required=True)
args = parser.parse_args()
file_name = args.file.name
locale = args.locale
# STEP1: ローカルにある音声ファイルをS3にアップロード
base_dir_pair = os.path.split(file_name)
local_path = base_dir_pair[0]
local_file_name = base_dir_pair[1]
object_name = upload_file(bucket_name, local_path, local_file_name)実行
実行前に環境変数にS3バケット名を設定する。テキスト変換させる音声は攻殻機動隊SAC26話の名セリフを使ってみる。Netflixで視聴できる。
> $env:S3_BUCKET_NAME = "speech.tetsis.com"
> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフf6a85e99-8f22-4b95-82a0-77cfd3be80db.mp3音声ファイルをS3にアップロードできた。実際にAWSコンソール画面を見ると音声ファイルがアップロードされているのが確認できる。
STEP2: Transcribeに文字起こし処理を依頼
関数コード
Transcribeで文字起こしを開始するためにはジョブ名を設定する必要がある。ジョブ名には文字数と種類の制約があるので、それに合わせるためS3にアップロードしたオブジェクト名を変換している。
また、OutputBucketNameには文字起こし結果を格納するS3バケットを指定できる。今回はSTEP1でアップロードしたバケットと同じバケットを使うこととにする。この関数は公式ドキュメントが参考になった。
def start_transcription_job(bucket_name, object_name, language_code):
job_name = re.sub(r'[^a-zA-Z0-9._-]', '', object_name)[:199] # Transcribeのフォーマット制約に合わせる(最大200文字。利用可能文字は英大文字小文字、数字、ピリオド、アンダーバー、ハイフン)
media_file_url = 's3://' + bucket_name + '/' + object_name
client = boto3.client('transcribe')
response = client.start_transcription_job(
TranscriptionJobName=job_name,
LanguageCode=language_code,
Media={
'MediaFileUri': media_file_url
},
OutputBucketName=bucket_name
)
print("\nTranscription start")
return job_namemain関数コード
if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2: Transcribeに文字起こし処理を依頼
job_name = start_transcription_job(bucket_name, object_name, locale)実行
> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフ04bd9138-da2f-400c-9ea6-7650d524e34e.mp3
Transcription startこれで文字起こし処理を開始するところまでできた。AWSのコンソール画面からTranscribeページを見ると、処理が登録されていることが確認できる。Webブラウザから簡単に処理状態や文字起こし結果を確認できるのがAWSのいいところだと思う。
STEP3: 定期的に処理結果を確認
関数コード
get_transcription_jobのレスポンスのjsonフォーマットは公式ドキュメントを参考にした。
def get_transcription_status(job_name):
client = boto3.client("transcribe")
response = client.get_transcription_job(
TranscriptionJobName=job_name
)
status = response["TranscriptionJob"]["TranscriptionJobStatus"]
print("Transcription status:\t" + status)
return statusmain関数コード
if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3: 定期的に処理結果を確認
status = ""
while status not in ["COMPLETED", "FAILED"]: # 処理が完了したら状態が"COMPLETED"、失敗したら"FAILED"になるからそれまでループ
status = get_transcription_status(job_name) # 処理状態を取得
time.sleep(3)実行
> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフ6d53dece-ea7c-4966-923a-e45687da42b0.mp3
Transcription start
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: COMPLETED処理が完了するのを待つところまで実行できた。
STEP4: 処理が完了したら処理結果のURLを取得
関数コード
処理が完了すると、文字起こし結果がS3にアップロードされる。get_transcription_job関数では文字起こし結果を格納しているS3オブジェクトのURLを返してくれる。
def get_transcription_file_url(job_name):
client = boto3.client("transcribe")
response = client.get_transcription_job(
TranscriptionJobName=job_name
)
file_url = response["TranscriptionJob"]["Transcript"]["TranscriptFileUri"]
print("\nFile URL:\n\t" + file_url)
return file_urlmain関数コード
if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3のコード(ここでは省略)
# STEP4: 処理が完了したら処理結果のURLを取得
file_url = get_transcription_file_url(job_name)実行
> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフd3496aa1-11f8-4f90-aeb8-e4f705467a0d.mp3
Transcription start
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
...(中略)...
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: COMPLETED
File URL:
https://s3.ap-northeast-1.amazonaws.com/speech.tetsis.com/d3496aa1-11f8-4f90-aeb8-e4f705467a0d.mp3.json最後に表示されているURLが文字起こし結果が格納されているS3オブジェクト。
STEP5: 処理結果をS3からダウンロードし結果を表示
関数コード
download_file関数は公式ドキュメントを参考にした。ダウンロードしたjsonファイルのデータフォーマットも公式ドキュメントを参考にした。
def download_file(bucket_name, object_name):
s3 = boto3.client('s3')
s3.download_file(bucket_name, object_name, object_name)
print("\nDownloading S3 object:\n\t" + object_name)
def get_transcript_from_file(file_name):
with open(file_name, "r", encoding="utf-8") as f:
df = json.load(f)
transcript = ""
for result in df["results"]["transcripts"]:
transcript += result["transcript"] + "\n"
print("\nTranscription result:\n" + transcript)
return transcriptmain関数コード
if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3のコード(ここでは省略)
# STEP4のコード(ここでは省略)
# STEP5: 処理結果をS3からダウンロードし結果を表示 (Pyhon SDK)
result_object_name = file_url[file_url.find(bucket_name) + len(bucket_name) + 1:]
download_file(bucket_name, result_object_name) # ここでダウンロード
get_transcript_from_file(result_object_name)実行
> python .\aws_speech.py -f .\草薙名セリフ.mp3 -l ja-JP
Uploading 草薙名セリフ.mp3 to S3 as object:
草薙名セリフ6aa4385a-f760-4c76-9b03-2cf015593a59.mp3
Transcription start
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
...(中略)...
Transcription status: IN_PROGRESS
Transcription status: IN_PROGRESS
Transcription status: COMPLETED
File URL:
https://s3.ap-northeast-1.amazonaws.com/speech.tetsis.com/6aa4385a-f760-4c76-9b03-2cf015593a59.mp3.json
Downloading S3 object:
6aa4385a-f760-4c76-9b03-2cf015593a59.mp3.json
Transcription result:
だ けど 私 は 情報 の 並列 化 の 果て に 後 を 取り戻す ため の 一つ の 可能 性 を 見つけ た わ ちなみに その 答え は 好奇 心 多分 ねどのセリフを文字起こししたのか、まあ分かる、よね。単語ごと(?)にスペース区切りされているから少し見づらいけどほとんど正確に文字に変換してくれてる(「後」は本当は「個」。セリフの重要な部分なだけに残念)。「ちなみに その 答え は」は別の人のセリフなんだけどそれでもちゃんと認識しててすごい。
全コード
最後に今回のコードの全体を載せておく。
# -*- coding: utf-8 -*-
import os
import uuid
import argparse
import logging
import re
import time
import json
import boto3
from botocore.exceptions import ClientError
def upload_file(bucket_name, local_path, local_file_name):
root_ext_pair = os.path.splitext(local_file_name)
object_name = root_ext_pair[0] + str(uuid.uuid4()) + root_ext_pair[1] # S3バケット内で唯一のオブジェクト名になるようにランダム文字列(UUID)を挿入しておく
upload_file_path = os.path.join(local_path, local_file_name)
# Upload the file
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(upload_file_path, bucket_name, object_name)
except ClientError as e:
print(e)
return None
print("\nUploading " + local_file_name +" to S3 as object:\n\t" + object_name)
return object_name
def download_file(bucket_name, object_name):
s3 = boto3.client('s3')
s3.download_file(bucket_name, object_name, object_name)
print("\nDownloading S3 object:\n\t" + object_name)
def start_transcription_job(bucket_name, object_name, language_code):
job_name = re.sub(r'[^a-zA-Z0-9._-]', '', object_name)[:199] # Transcribeのフォーマット制約に合わせる(最大200文字。利用可能文字は英大文字小文字、数字、ピリオド、アンダーバー、ハイフン)
media_file_url = 's3://' + bucket_name + '/' + object_name
client = boto3.client('transcribe')
response = client.start_transcription_job(
TranscriptionJobName=job_name,
LanguageCode=language_code,
Media={
'MediaFileUri': media_file_url
},
OutputBucketName=bucket_name
)
print("\nTranscription start")
return job_name
def get_transcription_status(job_name):
client = boto3.client("transcribe")
response = client.get_transcription_job(
TranscriptionJobName=job_name
)
status = response["TranscriptionJob"]["TranscriptionJobStatus"]
print("Transcription status:\t" + status)
return status
def get_transcription_file_url(job_name):
client = boto3.client("transcribe")
response = client.get_transcription_job(
TranscriptionJobName=job_name
)
file_url = response["TranscriptionJob"]["Transcript"]["TranscriptFileUri"]
print("\nFile URL:\n\t" + file_url)
return file_url
def get_transcript_from_file(file_name):
with open(file_name, "r", encoding="utf-8") as f:
df = json.load(f)
transcript = ""
for result in df["results"]["transcripts"]:
transcript += result["transcript"] + "\n"
print("\nTranscription result:\n" + transcript)
return transcript
if __name__ == "__main__":
bucket_name = os.getenv("S3_BUCKET_NAME")
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", type=argparse.FileType("r", encoding="UTF-8"), required=True)
parser.add_argument("-l", "--locale", help="e.g. \"en-US\" or \"ja-JP\"", required=True)
args = parser.parse_args()
file_name = args.file.name
locale = args.locale
# STEP1: ローカルにある音声ファイルをS3にアップロード
base_dir_pair = os.path.split(file_name)
local_path = base_dir_pair[0]
local_file_name = base_dir_pair[1]
object_name = upload_file(bucket_name, local_path, local_file_name)
# STEP2: Transcribeに文字起こし処理を依頼
job_name = start_transcription_job(bucket_name, object_name, locale)
# STEP3: 定期的に処理結果を確認
status = ""
while status not in ["COMPLETED", "FAILED"]: # 処理が完了したら状態が"COMPLETED"、失敗したら"FAILED"になるからそれまでループ
status = get_transcription_status(job_name) # 処理状態を取得
time.sleep(3)
# STEP4: 処理が完了したら処理結果のURLを取得
file_url = get_transcription_file_url(job_name)
# STEP5: 処理結果をS3からダウンロードし結果を表示 (Pyhon SDK)
result_object_name = file_url[file_url.find(bucket_name) + len(bucket_name) + 1:]
download_file(bucket_name, result_object_name) # ここでダウンロード
get_transcript_from_file(result_object_name)