Azureの文字起こしサービスを使ってみたので、Azureのポータル画面での操作とPythonコードをまとめておく。
今回使うAzureのサービスは文字起こしの中でも「バッチ文字起こし」というもので、Blob Storageにアップロードした音声ファイルを文字起こししてくれるものである。文字起こしの結果もBlob Storageに保存される。
処理の流れをまとめると以下のようになる。この記事は以下の順番で書いている。
- 準備
- STEP1: ローカルにある音声ファイルをBlob Storageにアップロード (Python SDK)
- STEP2: AzureのSpeech Servicesに文字起こし処理を依頼 (REST API)
- STEP3: 定期的に処理結果を確認 (REST API)
- STEP4: 処理が完了したら処理結果のURLを取得 (REST API)
- STEP5: 処理結果をBlob Storageからダウンロードし結果を表示 (Pyhon SDK)
準備
Azureポータル画面でリソースの作成と認証情報の取得を行う。
Blob Storage(コンテナー)を作成
まずはストレージアカウントというコンテナ―の上位概念を作成。作成ページへの行き方はいろいろあると思うけど、ポータルのホーム画面から左上の三本線アイコンから「ストレージアカウント」をクリックするのが簡単。
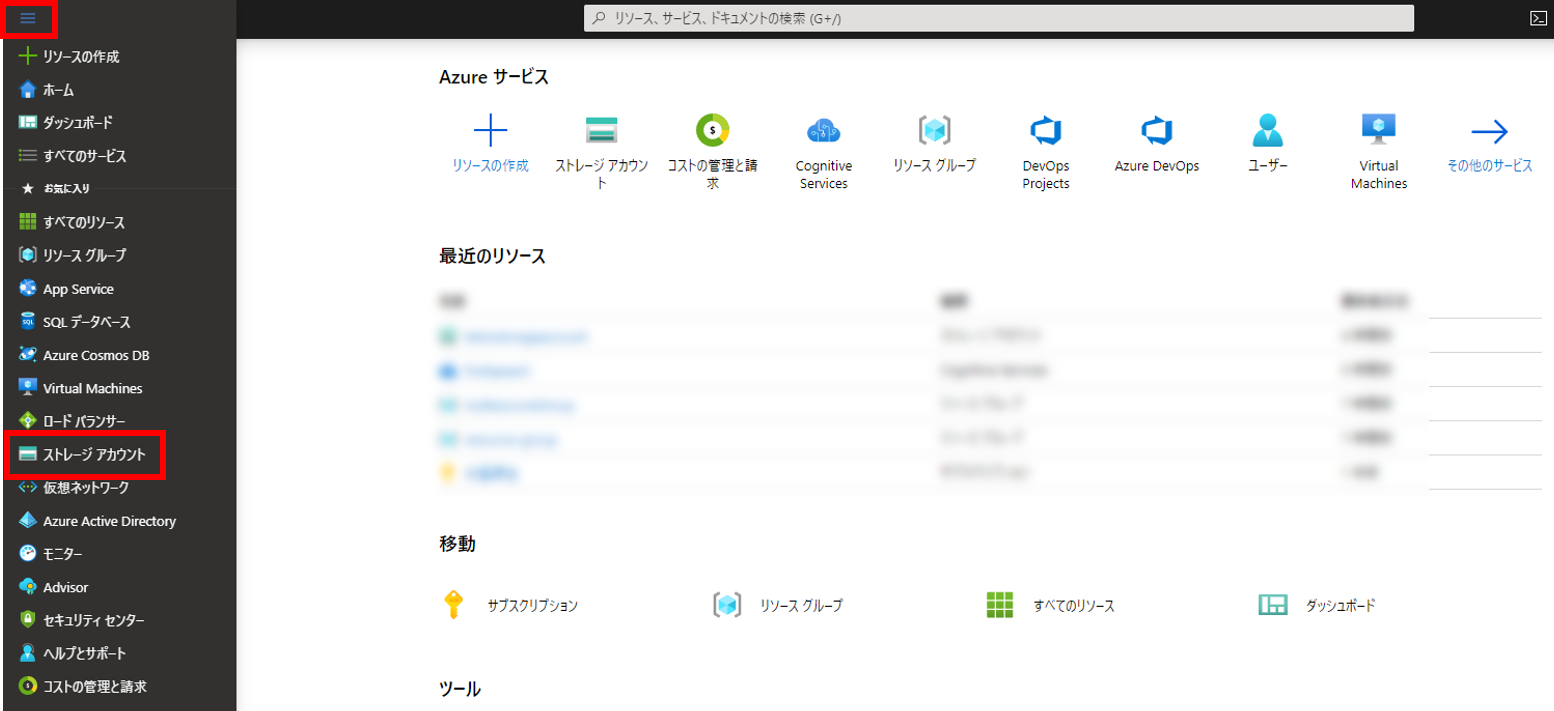
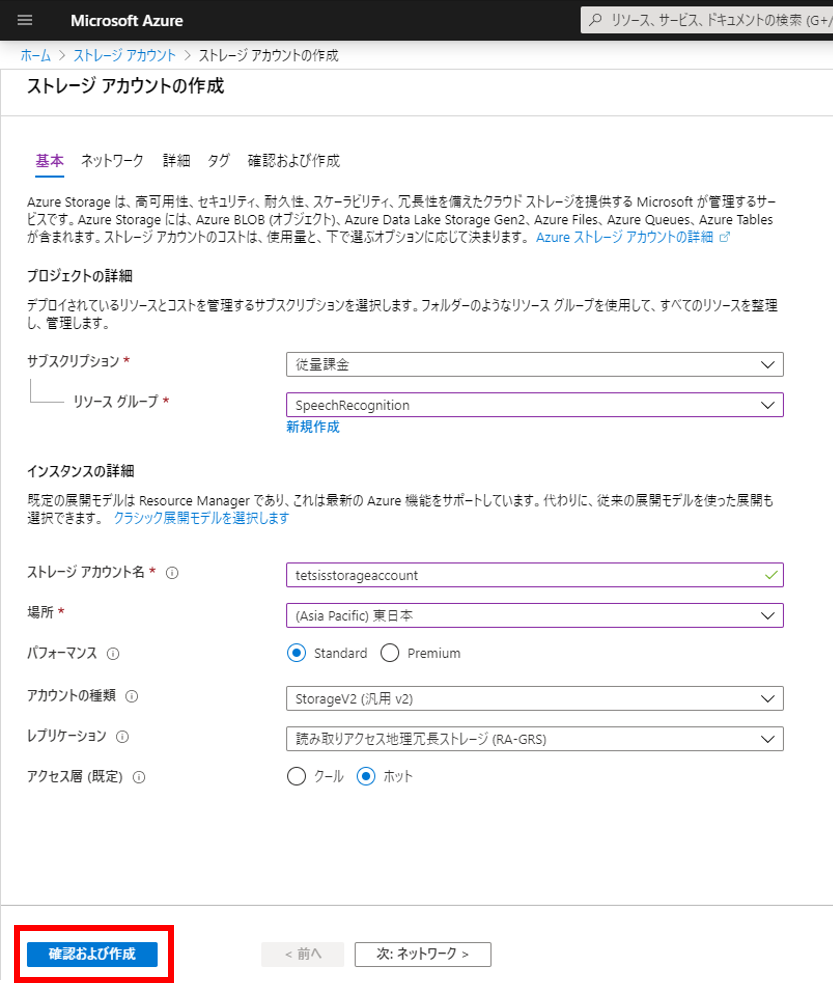
ストレージアカウント名はAzure内でユニークでなければならない。今回は「tetsisstorageaccount」にしてみた。リソースグループは事前に作っておいた「SpeechRecognition」、場所は「東日本」にした。その他はデフォルト。
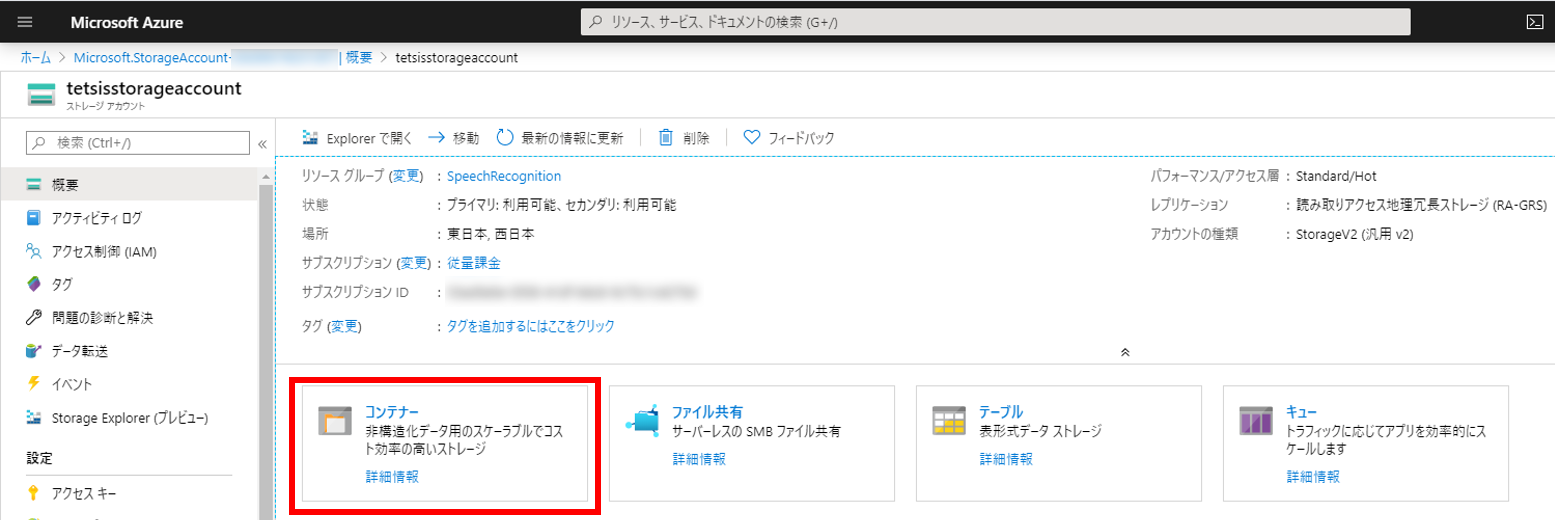
ストレージアカウントが作成できたらコンテナーを作成する。図の赤枠で囲った「コンテナー」をクリックする。
右側から「新しいコンテナー」モーダルが出てくる。今回は「speechcontainer」というコンテナー名にしてみた。

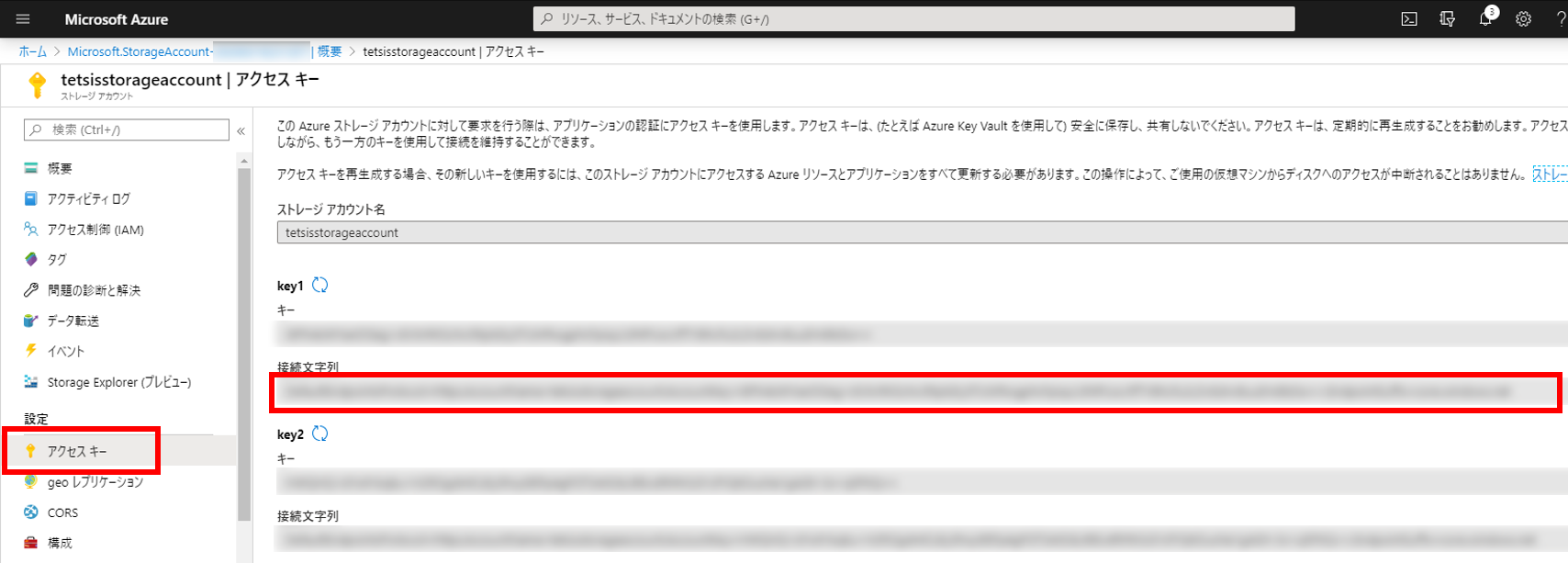
接続文字列を取得
ストレージアカウント画面の左メニューから「アクセスキー」をクリックすると下図のようなページが表示されるので、「接続文字列」をメモしておく。(このページはいつでも見にこれる。key1とkey2はどちらでもよい)
Speech Servicesを作成
音声認識サービスのリソースを作成する。作成ページに行くにはポータル画面の検索欄で「speech」と入力して表示される「Cognitive Services」をクリックするのが簡単。Cognitive ServicesはSpeech Servicesの上位概念。
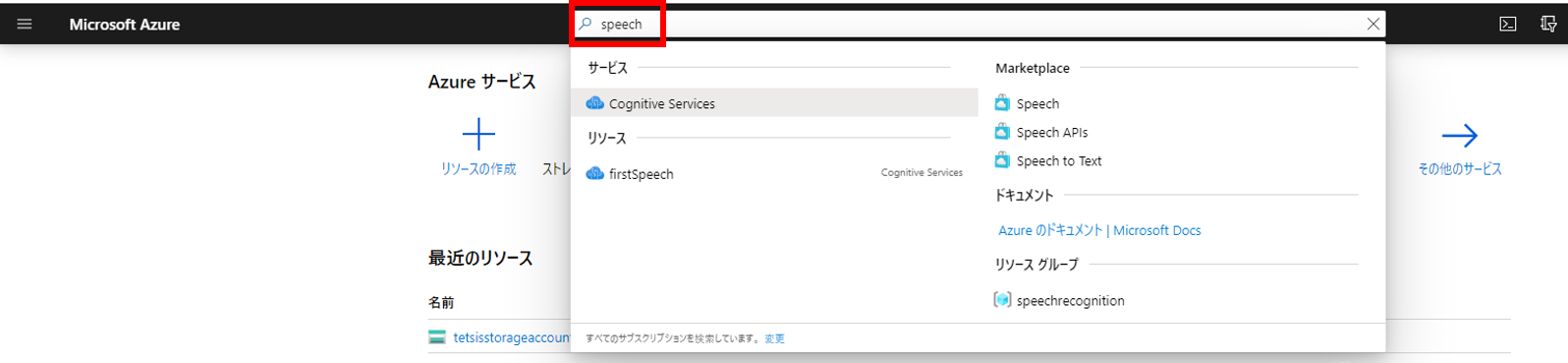
下図の「追加」をクリックする。
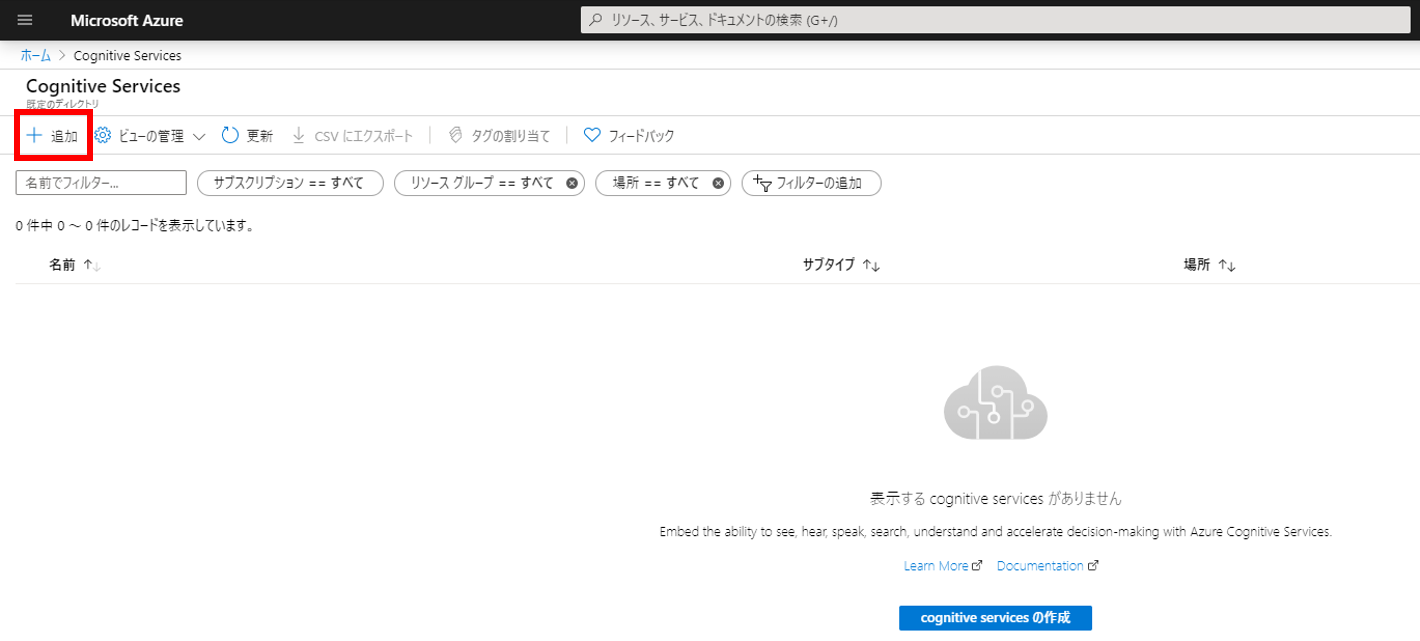
Marketplaceの検索欄で「speech」と入力して表示される「音声」をクリックする。
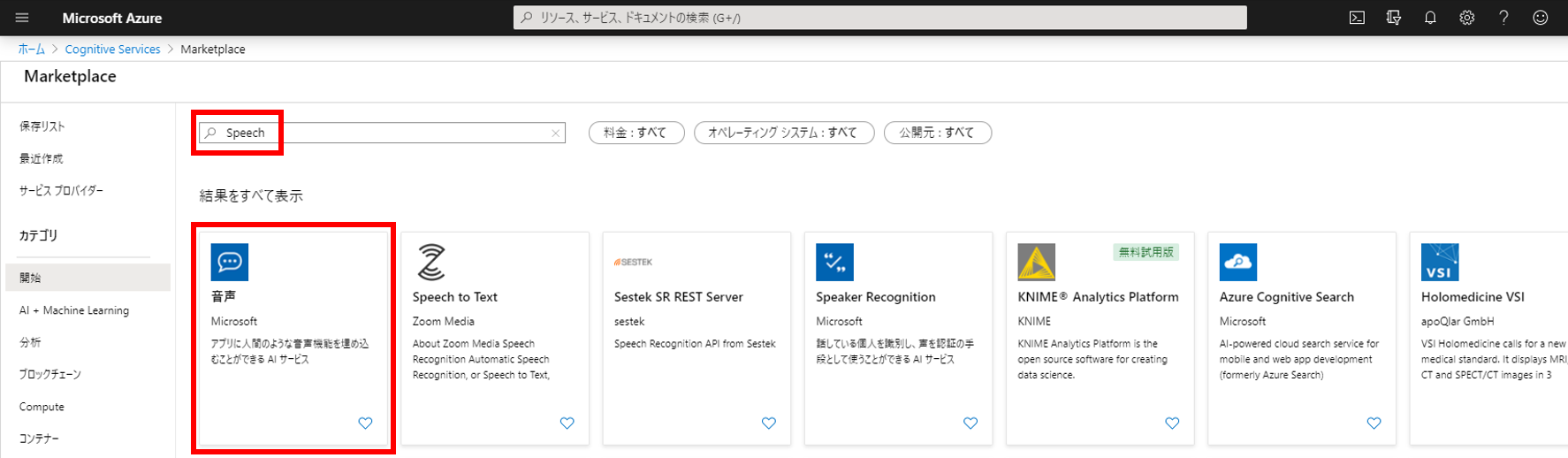
「作成」ボタンをクリックする。
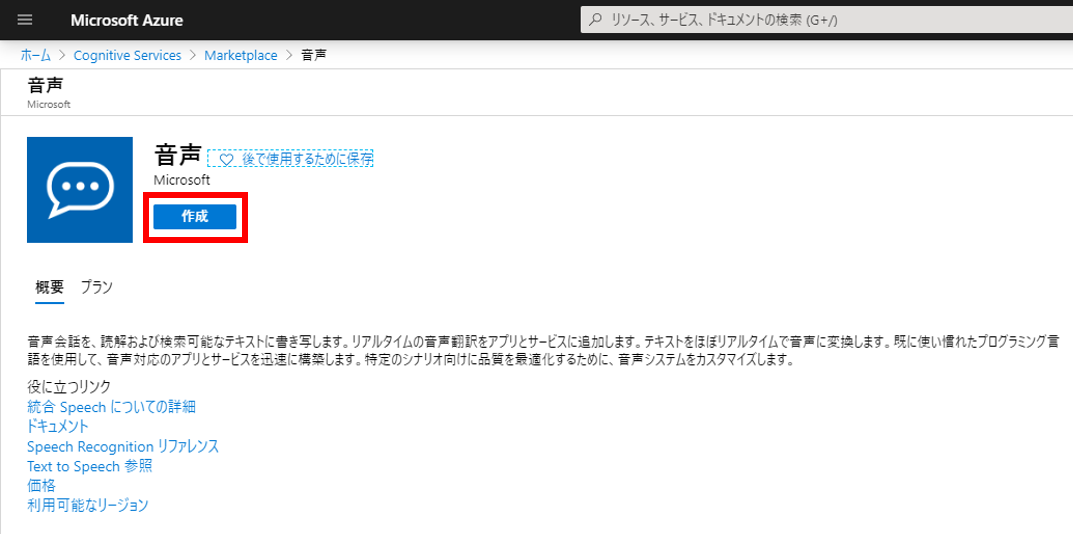
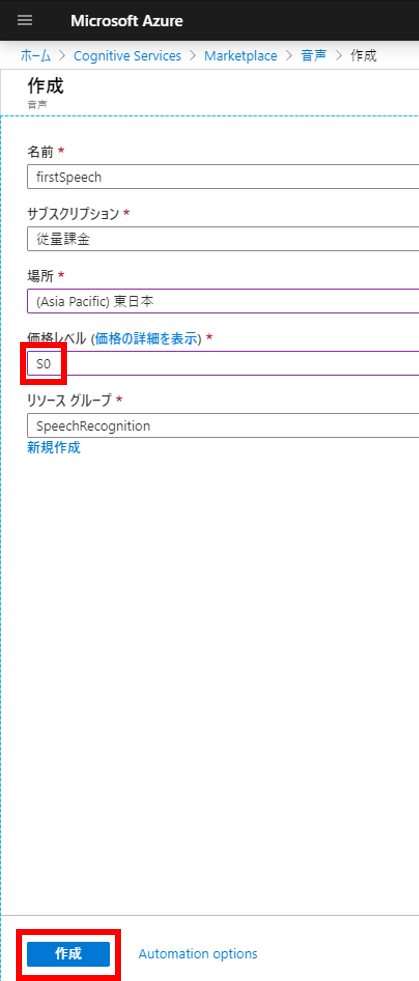
情報入力ページが表示される。名前は任意でよい。今回は「firstSpeech」にしてみた。場所は「東日本」。価格レベルは「SO」を選択する。今回利用するバッチ文字起こしはSOでないと利用できない。
サブスクリプションキーを取得
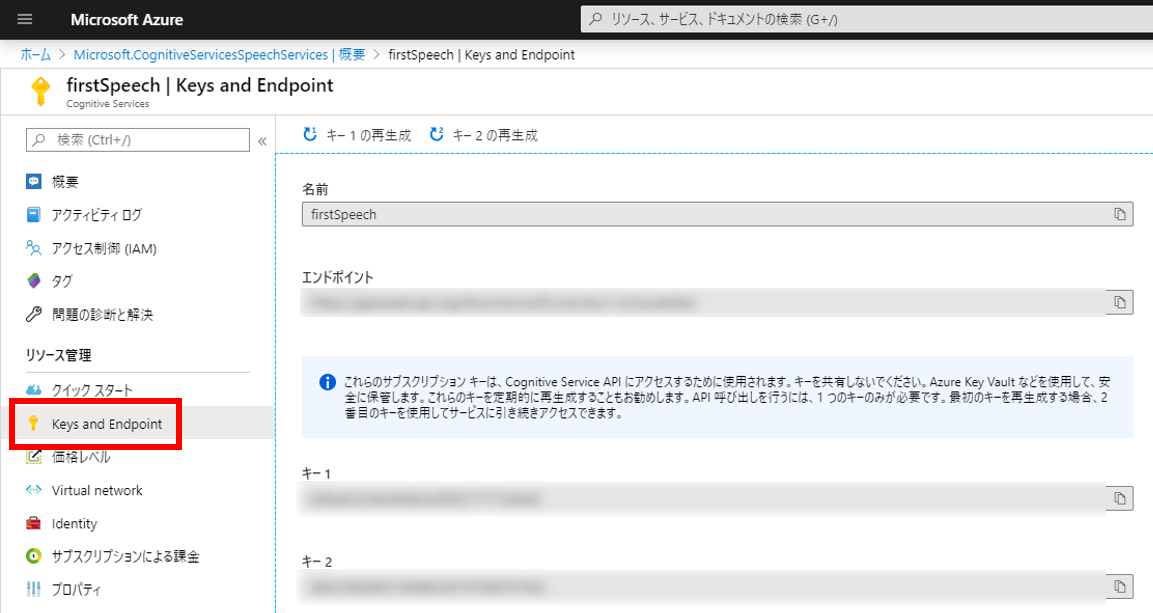
Cognitive Services画面の左メニューから「Keys and Endpoint」をクリックすると下図のようなページが表示されるので、サブスクリプションキーである「キー1」をメモしておく。 (このページはいつでも見にこれる。キー1とキー2はどちらでもよい)
Pythonコーディング
ブラウザ操作はこれで終わり。ようやくコーディングのお時間。今回は以下の環境で実行している。
– OS: Windows 10
– Python 3.8.1
– pip 20.0.2
以下のライブラリをインストールしておく。
pip install requests azure-storage-blob今回は一つのPythonファイルでコマンドラインから実行する簡単な方法でやってみる(ファイル名はazure_speech.py)。
まずファイルの先頭に以下のimport文を記載する。
# -*- coding: utf-8 -*-
import os
import uuid
import argparse
from datetime import datetime, timedelta
import requests
import json
import time
from azure.storage.blob import BlobServiceClient
from azure.storage.blob import ResourceTypes, AccountSasPermissions, ContainerSasPermissions
from azure.storage.blob import generate_account_sas, generate_container_sasSTEP1: ローカルにある音声ファイルをBlob Storageにアップロード (Python SDK)
関数コード
def upload_blob(connect_str, container_name, local_path, local_file_name):
root_ext_pair = os.path.splitext(local_file_name)
blob_name = root_ext_pair[0] + str(uuid.uuid4()) + root_ext_pair[1] # Blob Storage(コンテナー)内で唯一のBlob名になるようにランダム文字列(UUID)を挿入しておく
upload_file_path = os.path.join(local_path, local_file_name)
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
print("\nUploading to Azure Storage as blob:\n\t" + blob_name)
with open(upload_file_path, "rb") as data:
blob_client.upload_blob(data)
return blob_namemain関数コード
実行時に引数として①音声ファイルと②言語を指定するようにした。これでいろんな言語の音声ファイルで試しやすくなるはず。
if __name__ == "__main__":
connect_str = os.getenv("AZURE_STORAGE_CONNECTION_STRING")
container_name = os.getenv("AZURE_STORAGE_CONTAINER_NAME")
subscription_key = os.getenv("AZURE_SPEECH_SERVICE_SUBSCRIPTION_KEY")
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", type=argparse.FileType("r", encoding="UTF-8"), required=True)
parser.add_argument("-l", "--locale", help="e.g. \"en-US\" or \"ja-JP\"", required=True)
args = parser.parse_args()
file_name = args.file.name
locale = args.locale
# STEP1: ローカルにある音声ファイルをBlob Storageにアップロード (Python SDK)
base_dir_pair = os.path.split(file_name)
local_path = base_dir_pair[0]
local_file_name = base_dir_pair[1]
blob_name = upload_blob(connect_str, container_name, local_path, local_file_name) # ここでアップロード実行
最初に環境変数を設定してからPythonファイルを実行する。今回は環境変数の設定方法がWindows仕様。Mac、Linuxの場合は export コマンドを使えば同じことができる。
音声ファイルは攻殻機動隊の名言でテストしてみた。攻殻機動隊SAC5話のセリフでNetflixから視聴可能。Pythonファイル(azure_speech.py)と同じフォルダに音声ファイル(荒巻名セリフ.wav)を置いている。
> $env:AZURE_STORAGE_CONNECTION_STRING = "メモしておいた接続文字列"
> $env:AZURE_STORAGE_CONTAINER_NAME = "作成したコンテナー名"
> $env:AZURE_SPEECH_SERVICE_SUBSCRIPTION_KEY = "メモしておいたサブスクリプションキー"
> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフ43936629-807a-4d1a-b6d5-a5d0c67c50fe.wavAzureのポータル画面にて、元のファイル名にUUIDが追加されたファイル(上の実行結果の場合は 荒巻名セリフ43936629-807a-4d1a-b6d5-a5d0c67c50fe.wav )がコンテナーにアップロードされているのが確認できる。
STEP2: AzureのSpeech Servicesに文字起こし処理を依頼 (REST API)
API仕様はSwaggerに載っていて実装の時は結構参考になった。「Custom Speech transcriptions:」セクションが今回使うAPI。
関数コード
最初の2つの関数はアカウントSASとサービスSASという、APIを使う際の認証情報を取得する関数である。SAS自体はAzureが提供している関数を利用して生成している。公式のドキュメントページでSAS生成関数が紹介されている。
TranscriptionResultsContainerUrl には処理結果のファイルを格納してもらうコンテナ―を認証情報つきで記載する。今回は最初に作ったコンテナ―を流用した。なので、音声ファイルと同じコンテナ―に処理結果のファイルも格納される。
def get_sas_token(connect_str):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
sas_token = generate_account_sas(
blob_service_client.account_name,
account_key=blob_service_client.credential.account_key,
resource_types=ResourceTypes(object=True),
permission=AccountSasPermissions(read=True),
expiry=datetime.utcnow() + timedelta(hours=1)
)
return sas_token
def get_service_sas_token(connect_str, container_name):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
service_sas_token = generate_container_sas(
blob_service_client.account_name,
container_name,
account_key=blob_service_client.credential.account_key,
permission=ContainerSasPermissions(read=True, write=True),
expiry=datetime.utcnow() + timedelta(hours=1),
)
return service_sas_token
def start_transcription(connect_str, container_name, blob_name, subscription_key, locale):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
account_name = blob_service_client.account_name
container_url = "https://" + account_name + ".blob.core.windows.net/" + container_name
sas_token = get_sas_token(connect_str)
service_sas_token = get_service_sas_token(connect_str, container_name)
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions"
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
payload = {
"recordingsUrl": container_url + "/" + blob_name + "?" + sas_token,
"locale": locale,
"name": blob_name,
"properties": {
"TranscriptionResultsContainerUrl" : container_url + "?" + service_sas_token
}
}
r = requests.post(url, data=json.dumps(payload), headers=headers)
print("\nTranscription start")main関数コード
if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2: AzureのSpeech serviceに文字起こし処理を依頼 (REST API)
start_transcription(connect_str, container_name, blob_name, subscription_key, locale)実行
> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフcbbbe4e2-5507-4cae-8b54-a13003104be8.wav
Transcription start最後に「Transcription start」と表示される。
STEP3: 定期的に処理結果を確認 (REST API)
STEP2で開始した処理を特定できる情報は名前 name なんだけど、実行状態を取得するためのGETのAPIはIDで指定する仕様になっている。そのため最初にget_transcription_id関数で名前からIDを取得してから、IDを使って定期的に状態を取得している。これ、STEP2でPOSTした時のレスポンスにIDを含めてくれたらいんだけどなぁ、、と思う。名前だけだと毎回リスト取得するしかなくて無駄に情報取ってくることになって効率悪いんだよなぁ。
関数コード
def get_transcription_id(subscription_key, transcription_name):
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions"
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
r = requests.get(url, headers=headers)
response = json.loads(r.text)
for res in response:
if res["name"] == transcription_name:
id = res["id"]
print("\nTranscription ID:\n\t" + id)
return id
return None
def get_transcription_info_from_id(subscription_key, transcription_id):
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions/" + transcription_id
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
r = requests.get(url, headers=headers)
response = json.loads(r.text)
return response
def get_transcription_status(subscription_key, transcription_id):
response = get_transcription_info_from_id(subscription_key, transcription_id)
status = response["status"]
print("Transcription status:\t" + status)
return statusmain関数コード
if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3: 定期的に処理結果を確認 (REST API)
transcription_id = get_transcription_id(subscription_key, blob_name) # Transcription nameからIDを取得
status = ""
while status != "Succeeded": # 処理が完了したら状態が"Succeeded"になるからそれまでループ
status = get_transcription_status(subscription_key, transcription_id) # 処理状態を取得
time.sleep(3)実行
> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフb822c506-843c-4f1d-af81-35799e9209dc.wav
Transcription start
Transcription ID:
e5512338-1e66-44c0-bd5f-68b680d99ba6
Transcription status: NotStarted
Transcription status: NotStarted
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: SucceededTranscription status が NotStartedからRunningになり、最終的にSucceededになっている。
STEP4: 処理が完了したら処理結果のBlob URLを取得 (REST API)
関数コード
def get_transcription_result_url(subscription_key, transcription_id):
response = get_transcription_info_from_id(subscription_key, transcription_id)
if "resultsUrls" in response:
result_url = response["resultsUrls"]["channel_0"]
print("\nResult URL:\n\t" + result_url)
return result_url
return Nonemain関数コード
if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3のコード(ここでは省略)
# STEP4: 処理が完了したら処理結果のBlob URLを取得 (REST API)
result_url = get_transcription_result_url(subscription_key, transcription_id)実行
> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフ9b3f55c6-4c3f-4656-a48e-a4546907a31e.wav
Transcription start
Transcription ID:
e83a0767-d4ab-421b-8476-7cba3f5dde30
Transcription status: NotStarted
Transcription status: NotStarted
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Succeeded
Result URL:
https://tetsisstorageaccount.blob.core.windows.net/speechcontainer/e83a0767-d4ab-421b-8476-7cba3f5dde30_transcription_channel_0.json処理結果のURLが表示される。
STEP5: 処理結果をBlob Storageからダウンロードし結果を表示 (Pyhon SDK)
関数コード
ダウンロードのコードもアップロードと同様に公式ページに載っている方法を参考にした。
結果のjsonファイルのデータフォーマットについては公式ページや Swaggerページを参考にした。テキスト化した結果は Lexical, ITN, MaskedITN, Display の4種類があるみたいだけど、今回は句読点とかつけてくれる Display を表示することにした。
def download_blob(connect_str, container_name, blob_name):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
print("\nUploading to Azure Storage as blob:\n\t" + blob_name)
with open(blob_name, "wb") as download_file:
download_file.write(blob_client.download_blob().readall())
def get_transcript_from_file(file_name):
with open(file_name, "r", encoding="utf-8") as f:
df = json.load(f)
transcript = ""
for audio_file_result in df["AudioFileResults"]:
for combined_result in audio_file_result["CombinedResults"]:
transcript += combined_result["Display"] + "\n"
print("\nTranscription result:\n" + transcript)
return transcriptmain関数コード
if __name__ == "__main__":
# STEP1のコード(ここでは省略)
# STEP2のコード(ここでは省略)
# STEP3のコード(ここでは省略)
# STEP4のコード(ここでは省略)
# STEP5: 処理結果をBlob Storageからダウンロードし結果を表示 (Pyhon SDK)
blob_name = result_url[result_url.rfind("/") + 1:]
download_blob(connect_str, container_name, blob_name) # ここでダウンロード
get_transcript_from_file(blob_name) # ダウンロードしたファイルから音声をテキスト化した文字列を取得実行
> python .\azure_speech.py -f .\荒巻名セリフ.wav -l ja-JP
Uploading to Azure Storage as blob:
荒巻名セリフc2d034b7-3803-431d-bcf0-368310cd678b.wav
Transcription start
Transcription ID:
9388030b-cc98-428d-ae0c-3c5cff02ed3c
Transcription status: NotStarted
Transcription status: NotStarted
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Running
Transcription status: Succeeded
Result URL:
https://tetsisstorageaccount.blob.core.windows.net/speechcontainer/9388030b-cc98-428d-ae0c-3c5cff02ed3c_transcription_channel_0.json
Uploading to Azure Storage as blob:
9388030b-cc98-428d-ae0c-3c5cff02ed3c_transcription_channel_0.json
Transcription result:
よかろう我々の間にはチームプレーなどという都合の良い言い訳は存在せん。あるとすれば、、スタンドプレーから生じるチームワークだけだ。どのセリフをテキスト変換させてたのか完璧に分かる。
全コード
最後に今回のコードの全体を載せておく。
# -*- coding: utf-8 -*-
import os
import uuid
import argparse
from datetime import datetime, timedelta
import requests
import json
import time
from azure.storage.blob import BlobServiceClient
from azure.storage.blob import generate_account_sas, generate_container_sas, ResourceTypes, AccountSasPermissions, ContainerSasPermissions
def upload_blob(connect_str, container_name, local_path, local_file_name):
root_ext_pair = os.path.splitext(local_file_name)
blob_name = root_ext_pair[0] + str(uuid.uuid4()) + root_ext_pair[1] # Blob Storage(コンテナー)内で唯一のBlob名になるようにランダム文字列(UUID)を挿入しておく
upload_file_path = os.path.join(local_path, local_file_name)
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
print("\nUploading to Azure Storage as blob:\n\t" + blob_name)
with open(upload_file_path, "rb") as data:
blob_client.upload_blob(data)
return blob_name
def download_blob(connect_str, container_name, blob_name):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
print("\nUploading to Azure Storage as blob:\n\t" + blob_name)
with open(blob_name, "wb") as download_file:
download_file.write(blob_client.download_blob().readall())
def get_sas_token(connect_str):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
sas_token = generate_account_sas(
blob_service_client.account_name,
account_key=blob_service_client.credential.account_key,
resource_types=ResourceTypes(object=True),
permission=AccountSasPermissions(read=True),
expiry=datetime.utcnow() + timedelta(hours=1)
)
return sas_token
def get_service_sas_token(connect_str, container_name):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
service_sas_token = generate_container_sas(
blob_service_client.account_name,
container_name,
account_key=blob_service_client.credential.account_key,
permission=ContainerSasPermissions(read=True, write=True),
expiry=datetime.utcnow() + timedelta(hours=1),
)
return service_sas_token
def start_transcription(connect_str, container_name, blob_name, subscription_key, locale):
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
account_name = blob_service_client.account_name
container_url = "https://" + account_name + ".blob.core.windows.net/" + container_name
sas_token = get_sas_token(connect_str)
service_sas_token = get_service_sas_token(connect_str, container_name)
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions"
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
payload = {
"recordingsUrl": container_url + "/" + blob_name + "?" + sas_token,
"locale": locale,
"name": blob_name,
"properties": {
"TranscriptionResultsContainerUrl" : container_url + "?" + service_sas_token
}
}
r = requests.post(url, data=json.dumps(payload), headers=headers)
print("\nTranscription start")
def get_transcription_id(subscription_key, transcription_name):
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions"
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
r = requests.get(url, headers=headers)
response = json.loads(r.text)
for res in response:
if res["name"] == transcription_name:
id = res["id"]
print("\nTranscription ID:\n\t" + id)
return id
return None
def get_transcription_info_from_id(subscription_key, transcription_id):
url = "https://japaneast.cris.ai/api/speechtotext/v2.0/transcriptions/" + transcription_id
headers = {
"content-type": "application/json",
"accept": "application/json",
"Ocp-Apim-Subscription-Key": subscription_key,
}
r = requests.get(url, headers=headers)
response = json.loads(r.text)
return response
def get_transcription_status(subscription_key, transcription_id):
response = get_transcription_info_from_id(subscription_key, transcription_id)
status = response["status"]
print("Transcription status:\t" + status)
return status
def get_transcription_result_url(subscription_key, transcription_id):
response = get_transcription_info_from_id(subscription_key, transcription_id)
if "resultsUrls" in response:
result_url = response["resultsUrls"]["channel_0"]
print("\nResult URL:\n\t" + result_url)
return result_url
return None
def get_transcript_from_file(file_name):
with open(file_name, "r", encoding="utf-8") as f:
df = json.load(f)
transcript = ""
for audio_file_result in df["AudioFileResults"]:
for combined_result in audio_file_result["CombinedResults"]:
transcript += combined_result["Display"] + "\n"
print("\nTranscription result:\n" + transcript)
return transcript
if __name__ == "__main__":
connect_str = os.getenv("AZURE_STORAGE_CONNECTION_STRING")
container_name = os.getenv("AZURE_STORAGE_CONTAINER_NAME")
subscription_key = os.getenv("AZURE_SPEECH_SERVICE_SUBSCRIPTION_KEY")
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", type=argparse.FileType("r", encoding="UTF-8"), required=True)
parser.add_argument("-l", "--locale", help="e.g. \"en-US\" or \"ja-JP\"", required=True)
args = parser.parse_args()
file_name = args.file.name
locale = args.locale
# STEP1: ローカルにある音声ファイルをBlob Storageにアップロード (Python SDK)
base_dir_pair = os.path.split(file_name)
local_path = base_dir_pair[0]
local_file_name = base_dir_pair[1]
blob_name = upload_blob(connect_str, container_name, local_path, local_file_name) # ここでアップロード
# STEP2: AzureのSpeech serviceに文字起こし処理を依頼 (REST API)
start_transcription(connect_str, container_name, blob_name, subscription_key, locale)
# STEP3: 定期的に処理結果を確認 (REST API)
transcription_id = get_transcription_id(subscription_key, blob_name) # Transcription nameからIDを取得
status = ""
while status != "Succeeded": # 処理が完了したら状態が"Succeeded"になるからそれまでループ
status = get_transcription_status(subscription_key, transcription_id) # 処理状態を取得
time.sleep(3)
# STEP4: 処理が完了したら処理結果のBlob URLを取得 (REST API)
result_url = get_transcription_result_url(subscription_key, transcription_id)
# STEP5: 処理結果をBlob Storageからダウンロードし結果を表示 (Pyhon SDK)
blob_name = result_url[result_url.rfind("/") + 1:]
download_blob(connect_str, container_name, blob_name) # ここでダウンロード
get_transcript_from_file(blob_name) # ダウンロードしたファイルから音声をテキスト化した文字列を取得