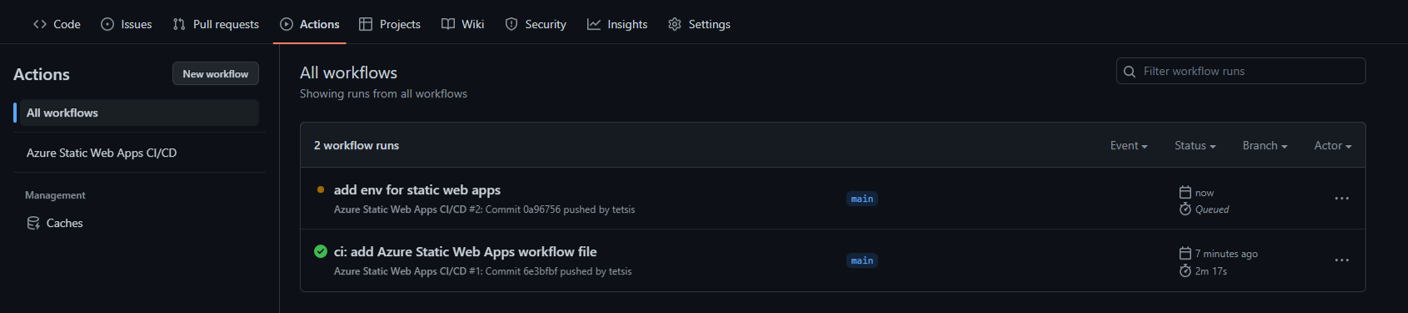
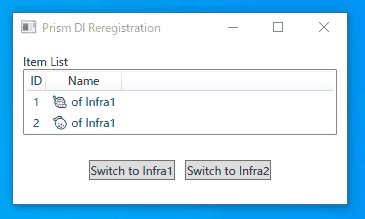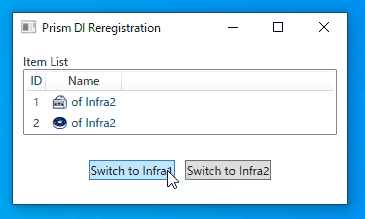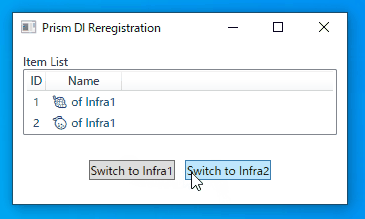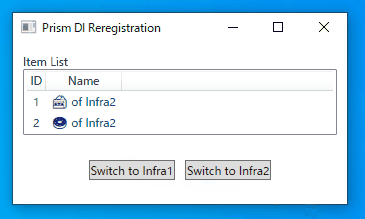
- name: Build And Deploy
id: builddeploy
uses: Azure/static-web-apps-deploy@v1
with:
...
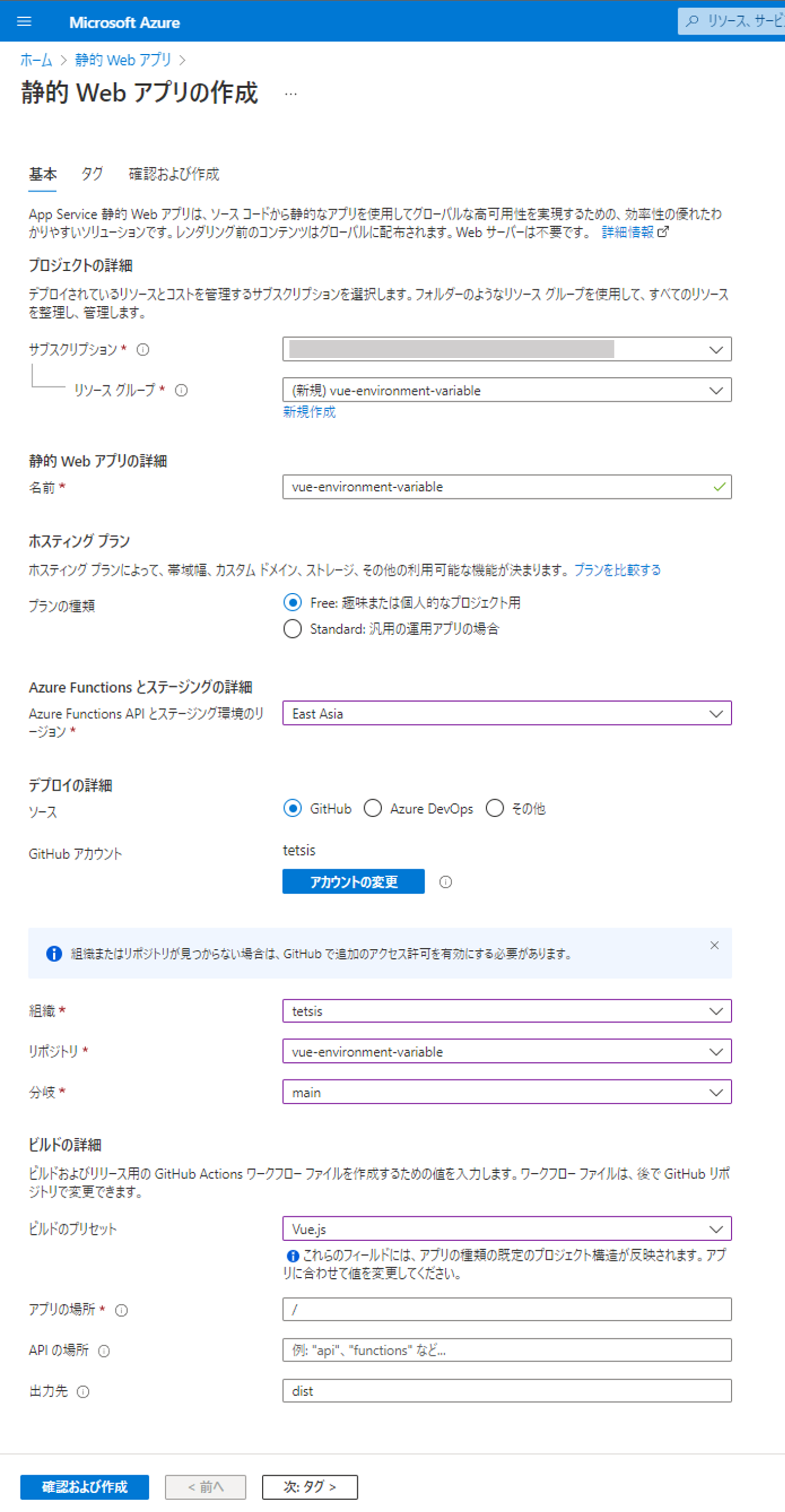
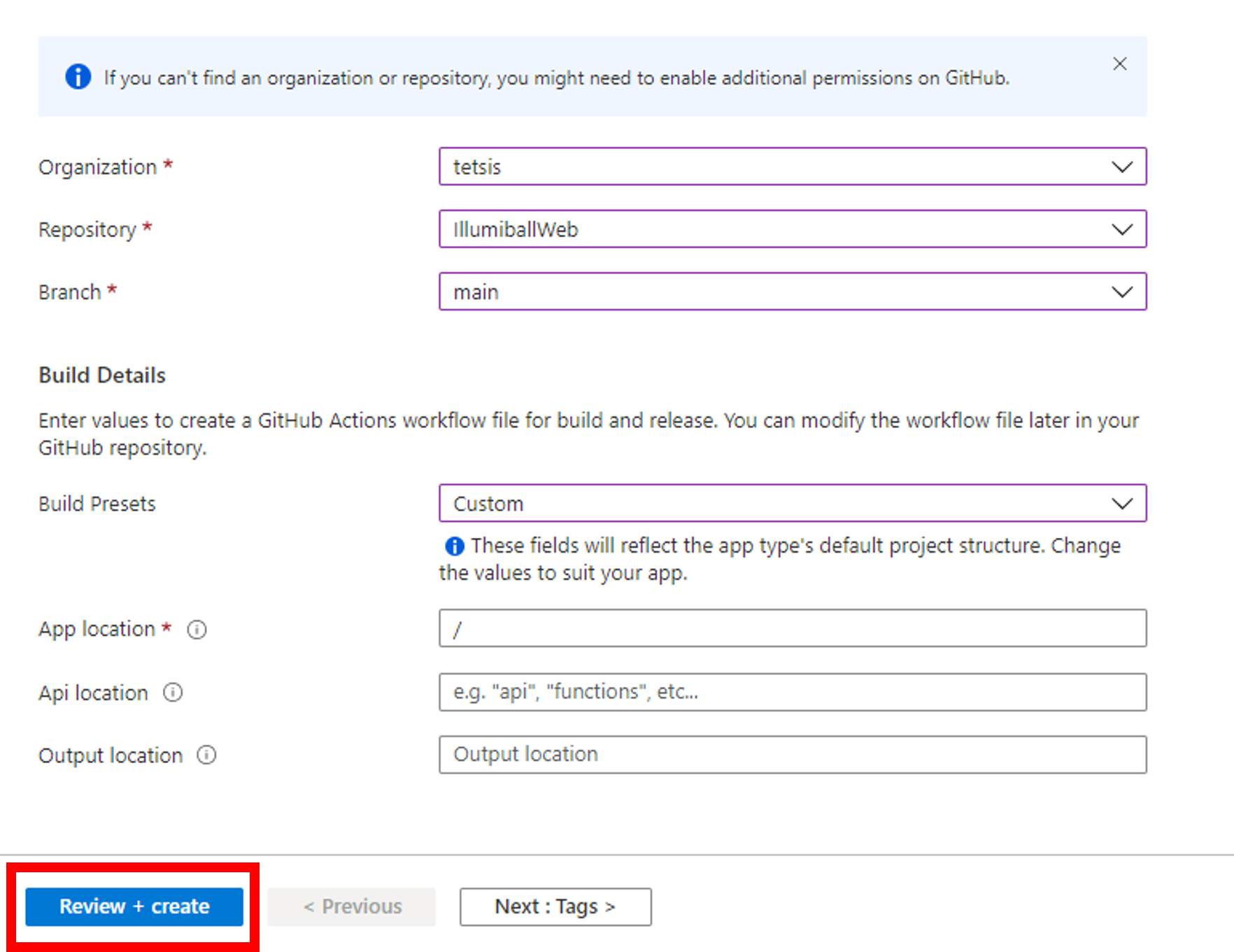
###### Repository/Build Configurations - These values can be configured to match your app requirements. ######
# For more information regarding Static Web App workflow configurations, please visit: https://aka.ms/swaworkflowconfig
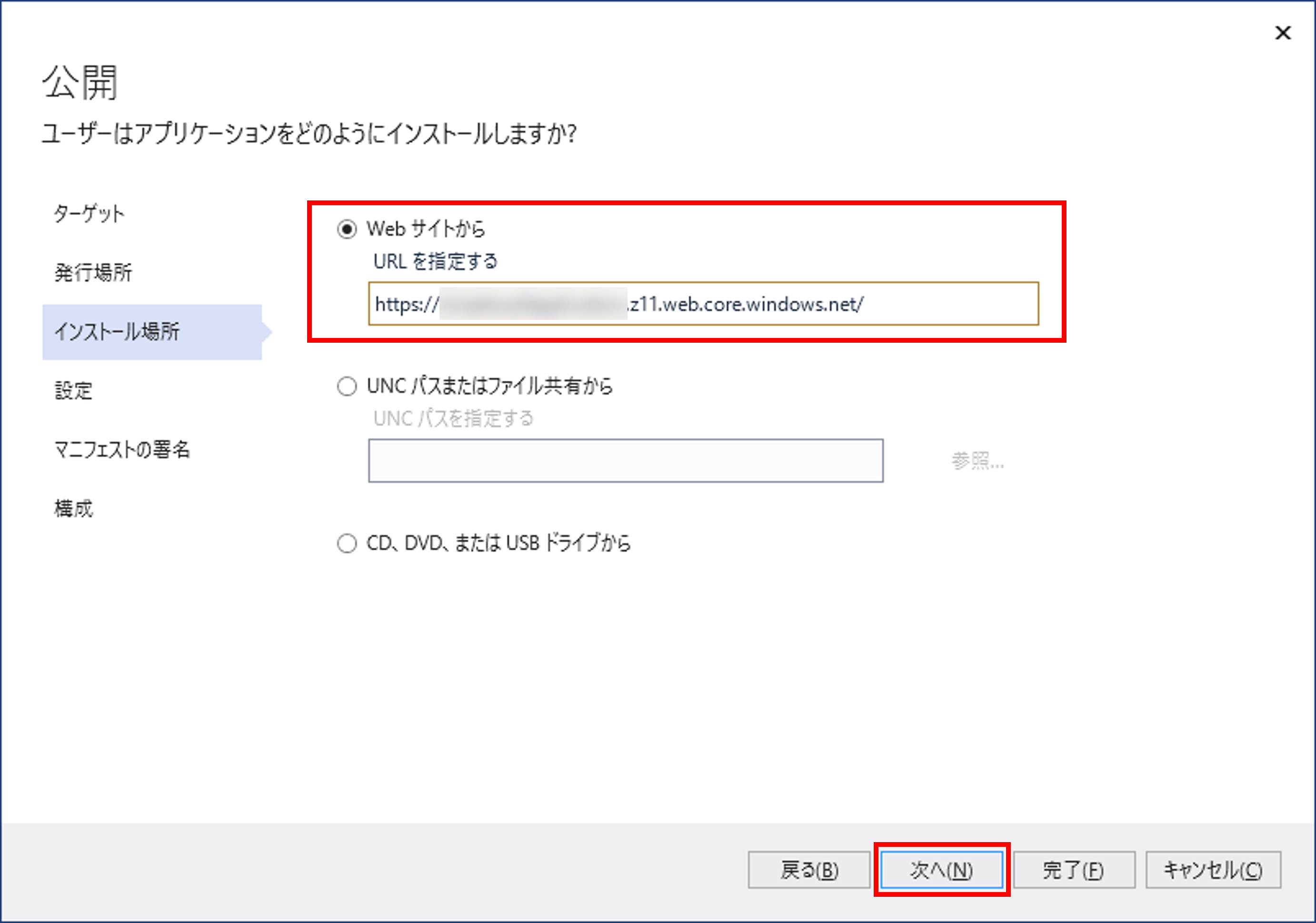
app_location: "/" # App source code path
api_location: "" # Api source code path - optional
output_location: "dist" # Built app content directory - optional
###### End of Repository/Build Configurations ######
env: # Add environment variables here
VUE_APP_TEXT: "text from GitHub workflow environment variable"
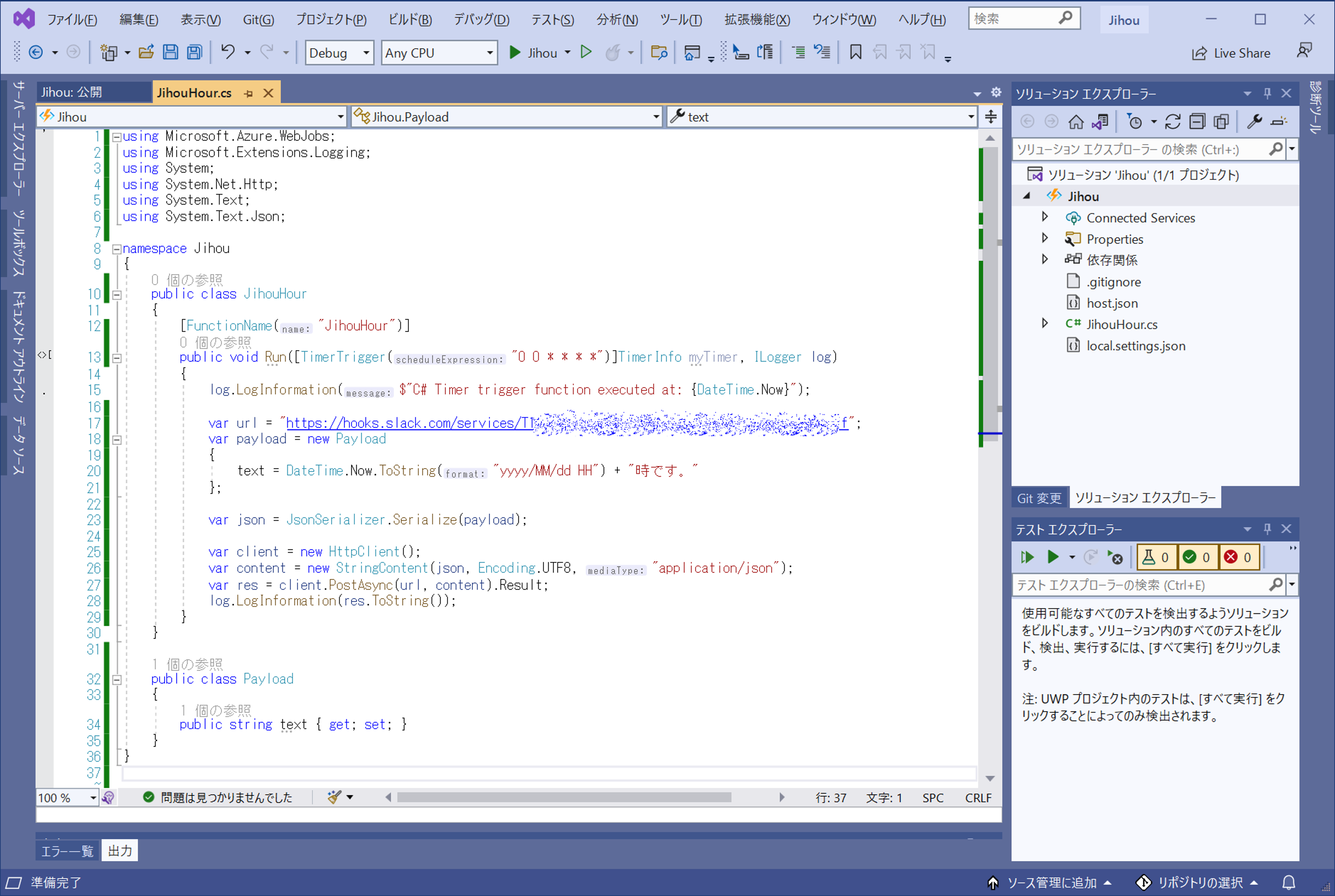
using Microsoft.Azure.WebJobs;
using Microsoft.Extensions.Logging;
using System;
using System.Net.Http;
using System.Text;
using System.Text.Json;
namespace Jihou
{
public class JihouHour
{
[FunctionName("JihouHour")]
public void Run([TimerTrigger("0 0 * * * *")]TimerInfo myTimer, ILogger log)
{
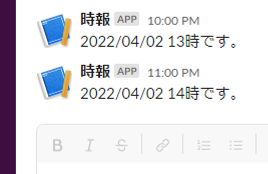
log.LogInformation($"C# Timer trigger function executed at: {DateTime.Now}");
var url = "https://hooks.slack.com/services/*******************************";
var payload = new Payload
{
text = DateTime.Now.ToString("yyyy/MM/dd HH") + "時です。"
};
var json = JsonSerializer.Serialize(payload);
var client = new HttpClient();
var content = new StringContent(json, Encoding.UTF8, "application/json");
var res = client.PostAsync(url, content).Result;
log.LogInformation(res.ToString());
}
}
public class Payload
{
public string text { get; set; }
}
}
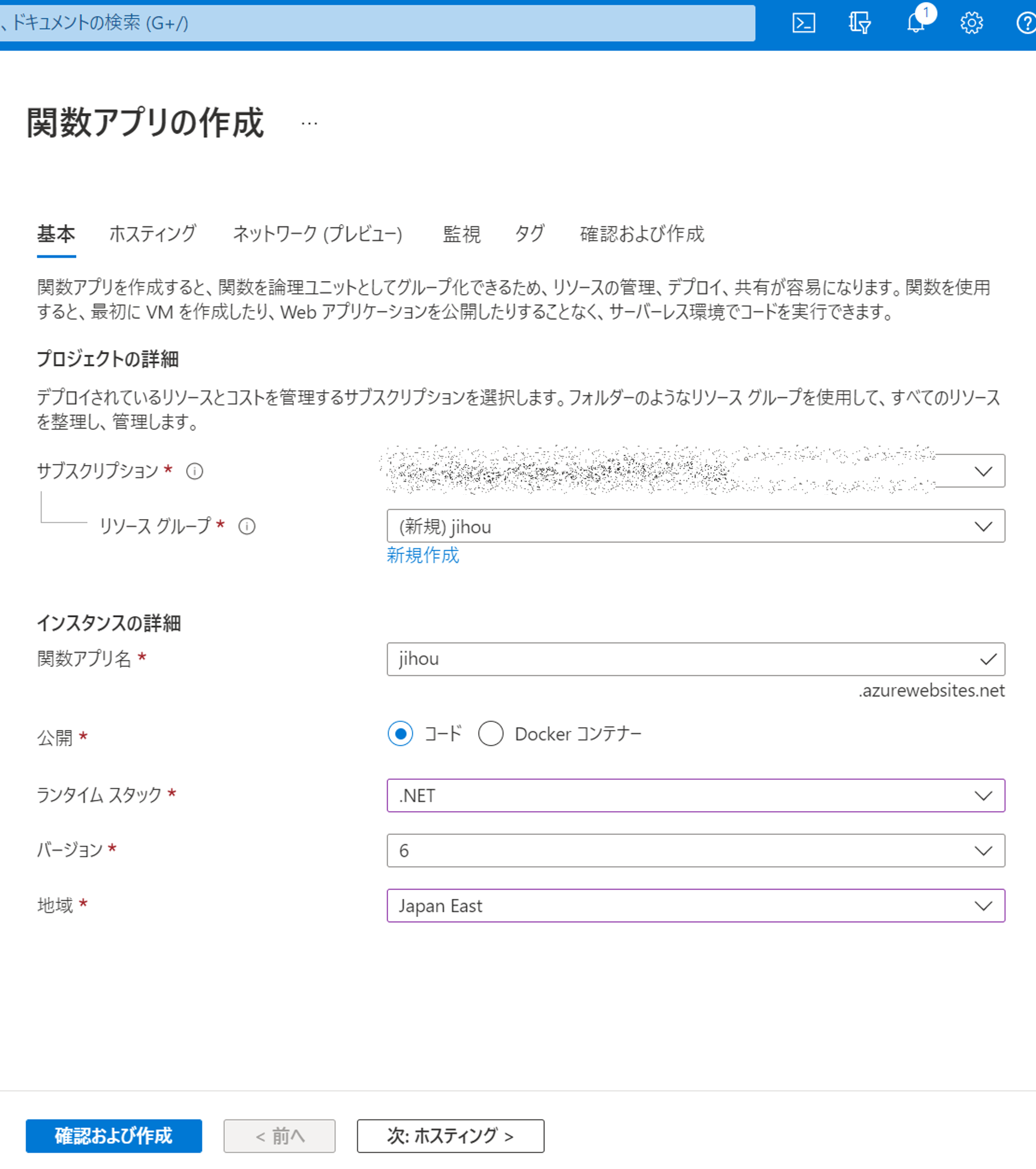
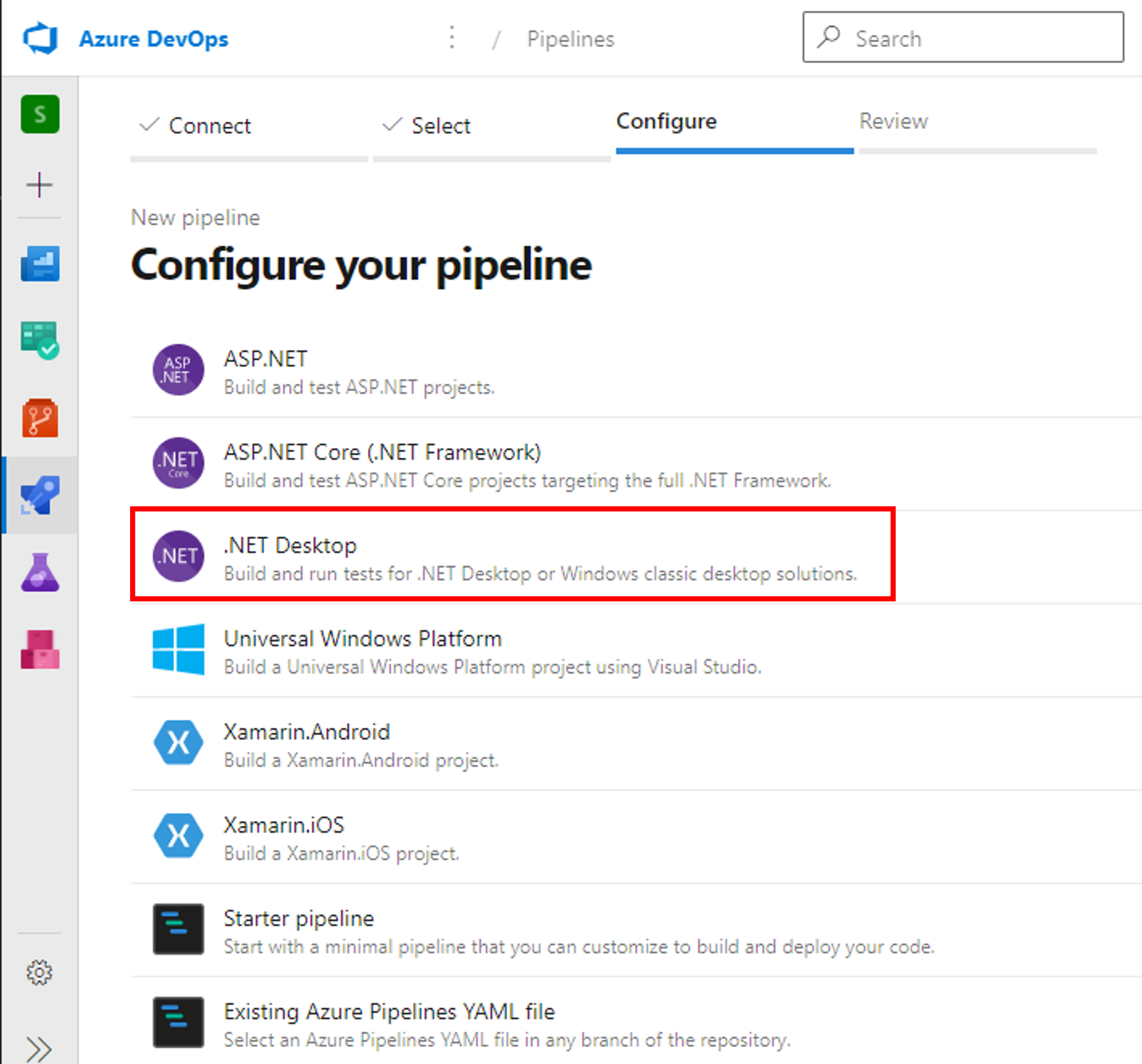
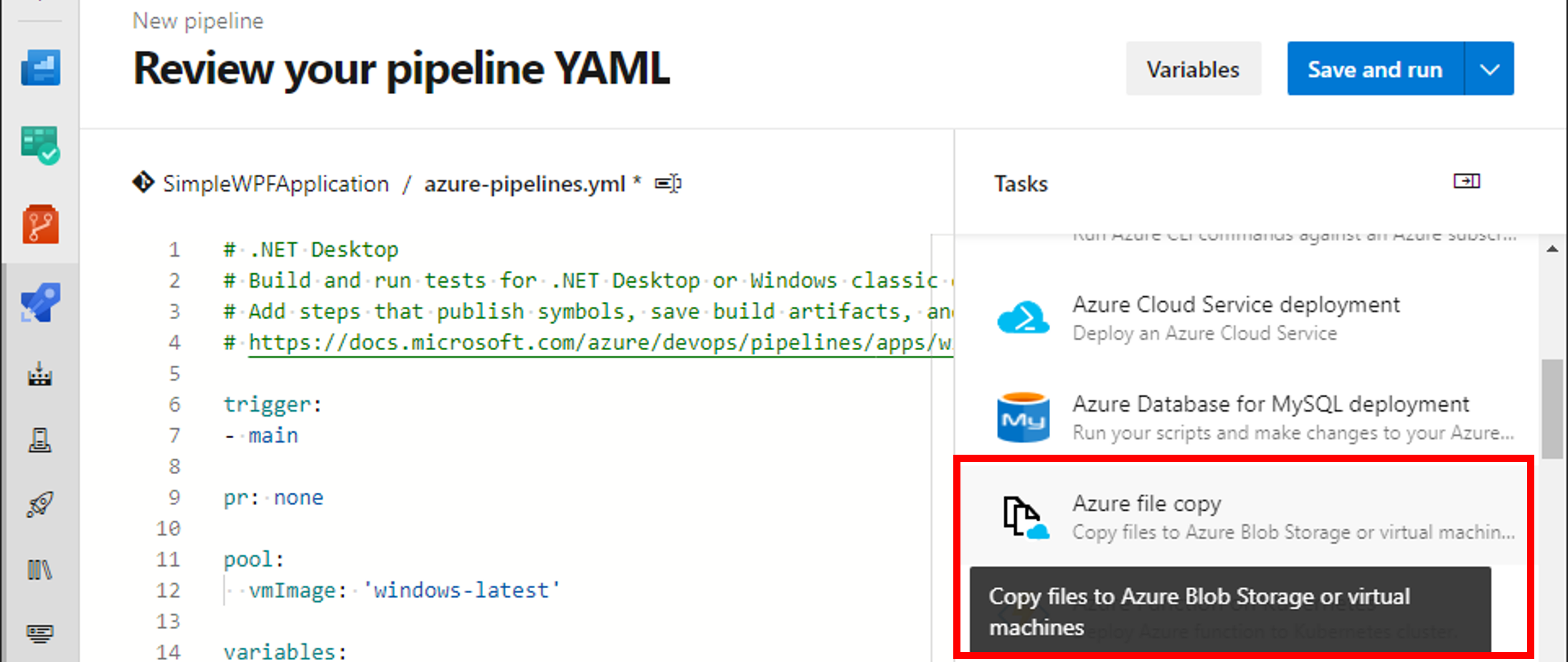
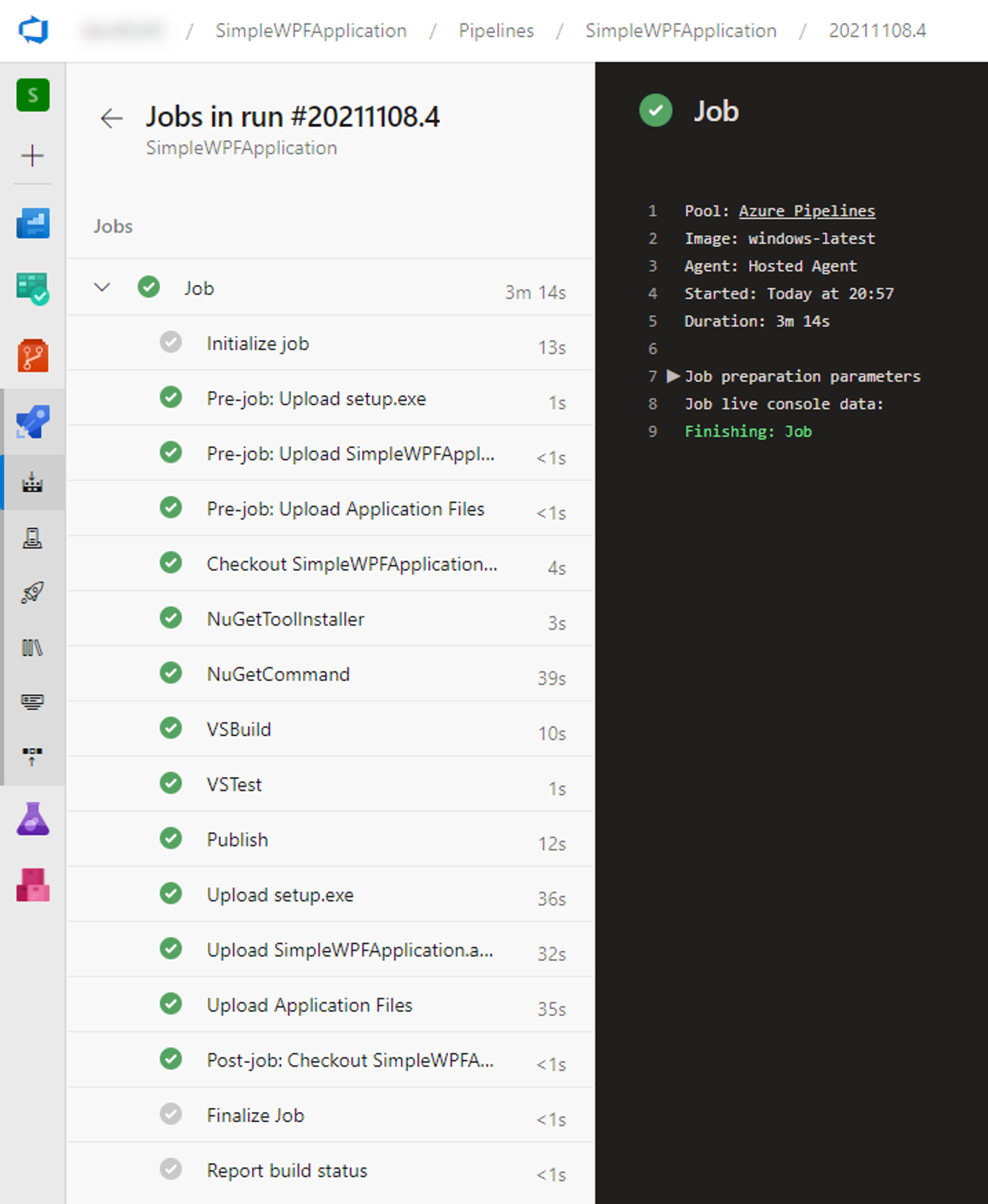
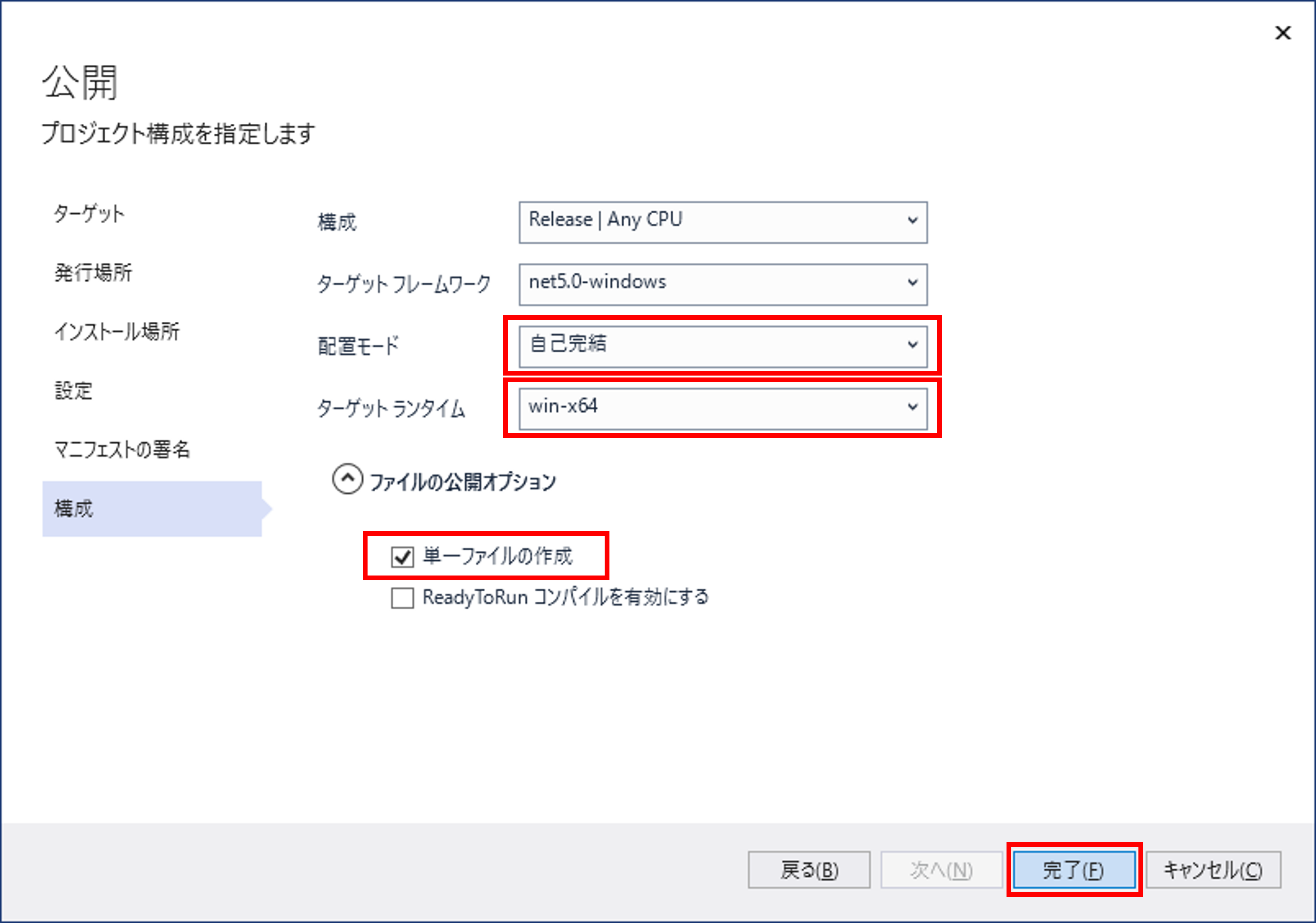
##[error]C:\Program Files\dotnet\sdk\5.0.402\Sdks\Microsoft.NET.Sdk\targets\Microsoft.PackageDependencyResolution.targets(241,5): Error NETSDK1047: Assets file 'D:\a\1\s\SimpleWPFApplication\obj\project.assets.json' doesn't have a target for 'net5.0-windows/win-x64'. Ensure that restore has run and that you have included 'net5.0-windows' in the TargetFrameworks for your project. You may also need to include 'win-x64' in your project's RuntimeIdentifiers.
このエラーを避けるため、エラーメッセージで勧められている通りランタイムを指定しておきます。
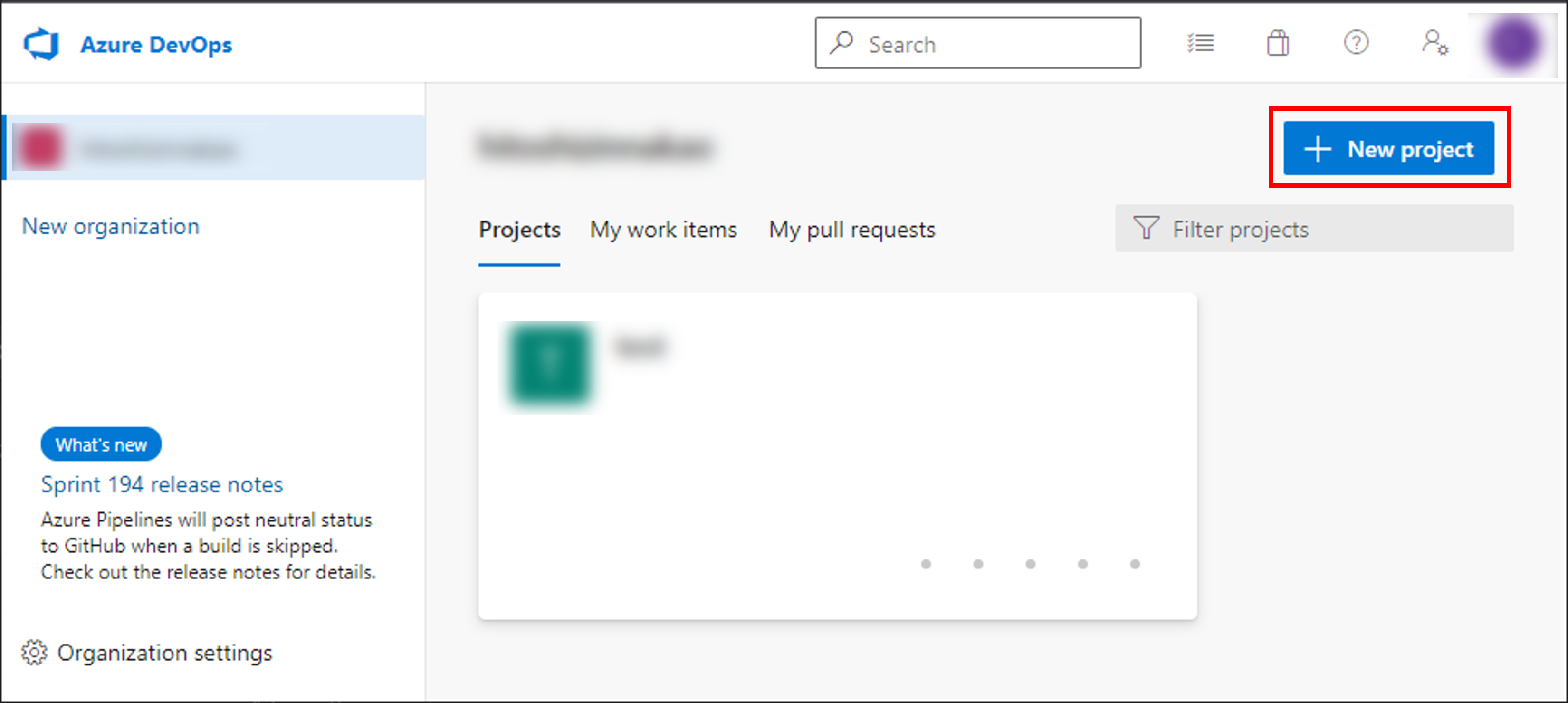
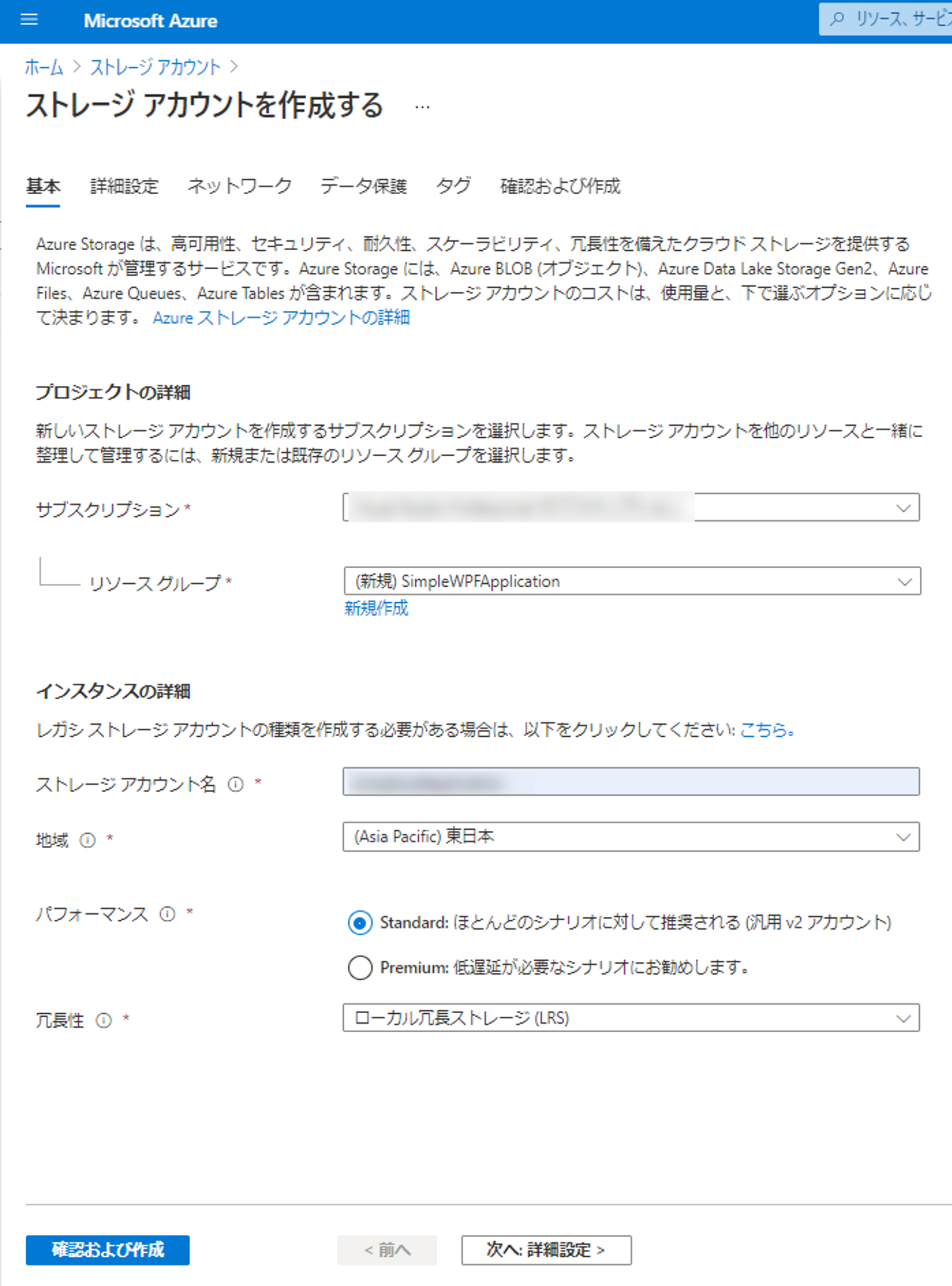
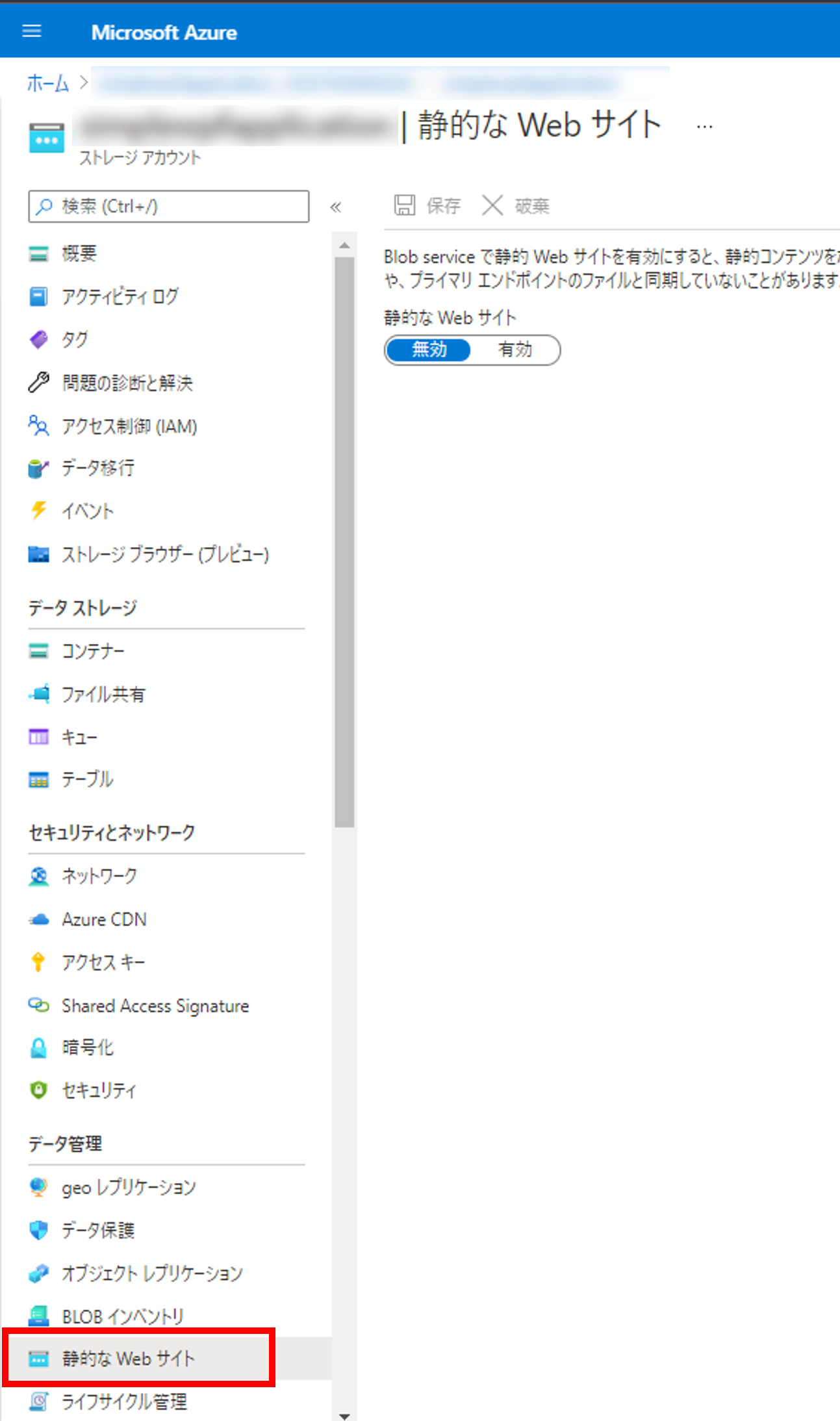
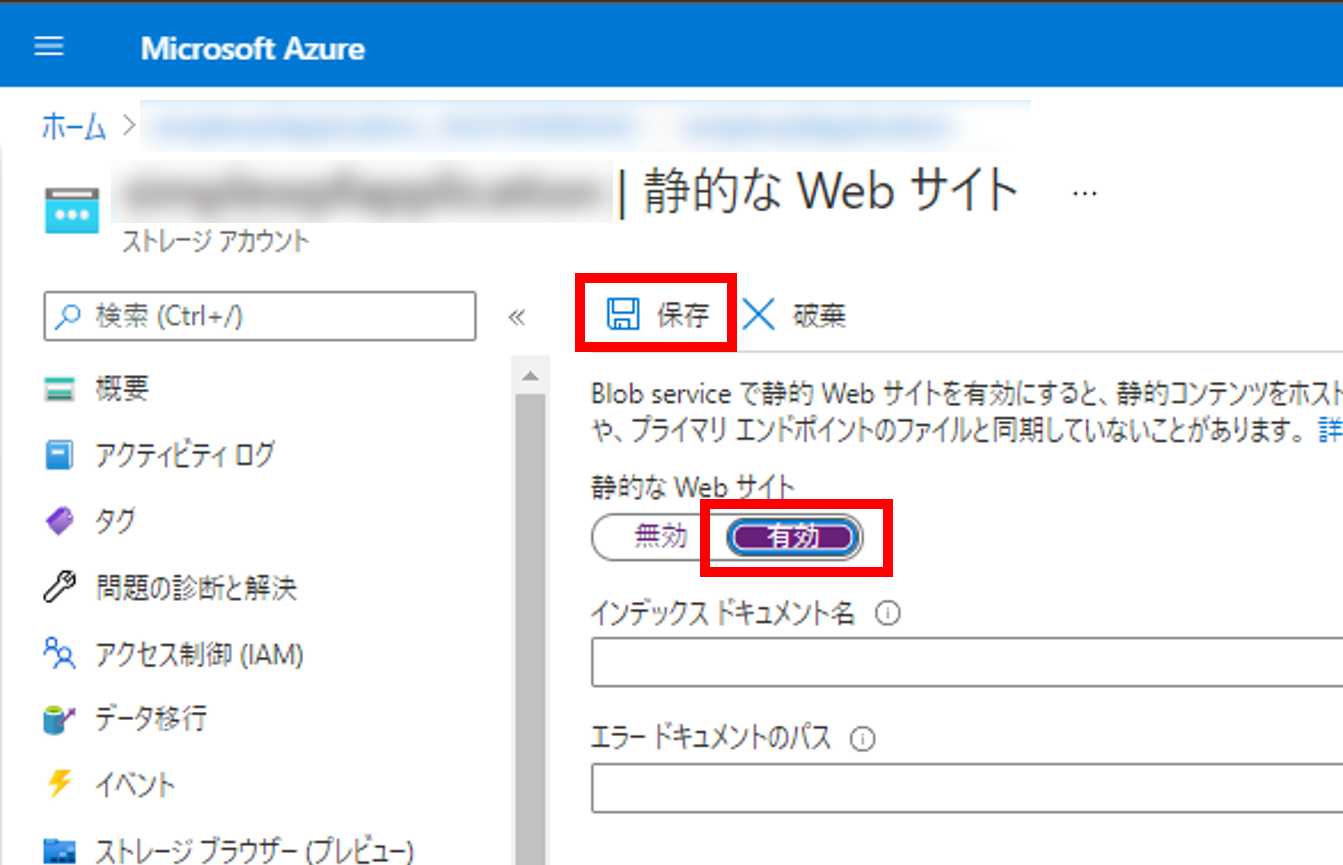
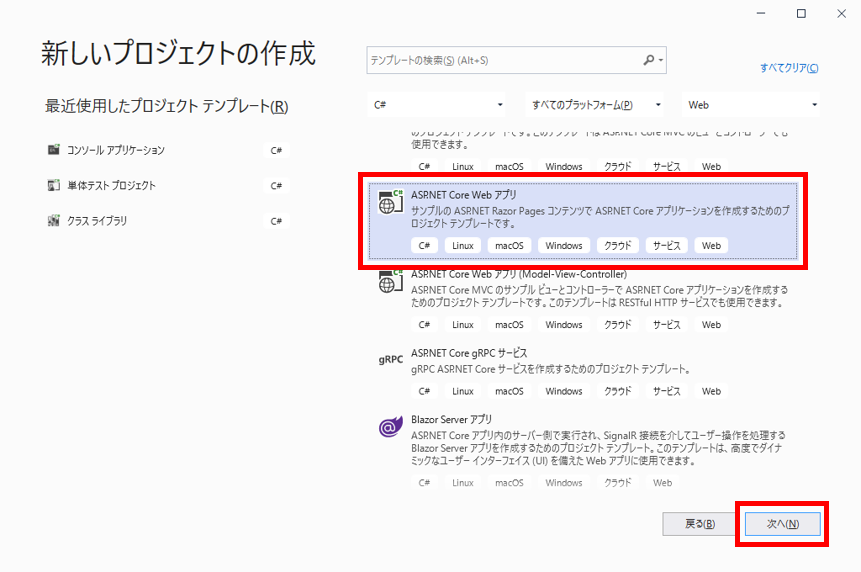
2. Azure DevOpsでプロジェクトを作成する
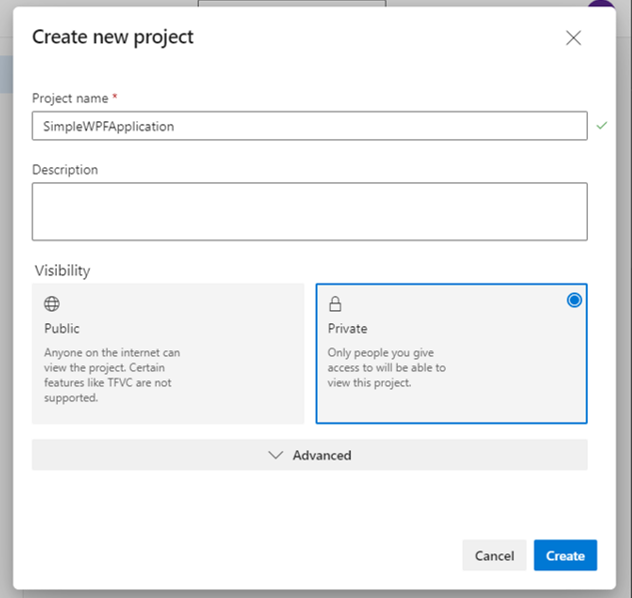
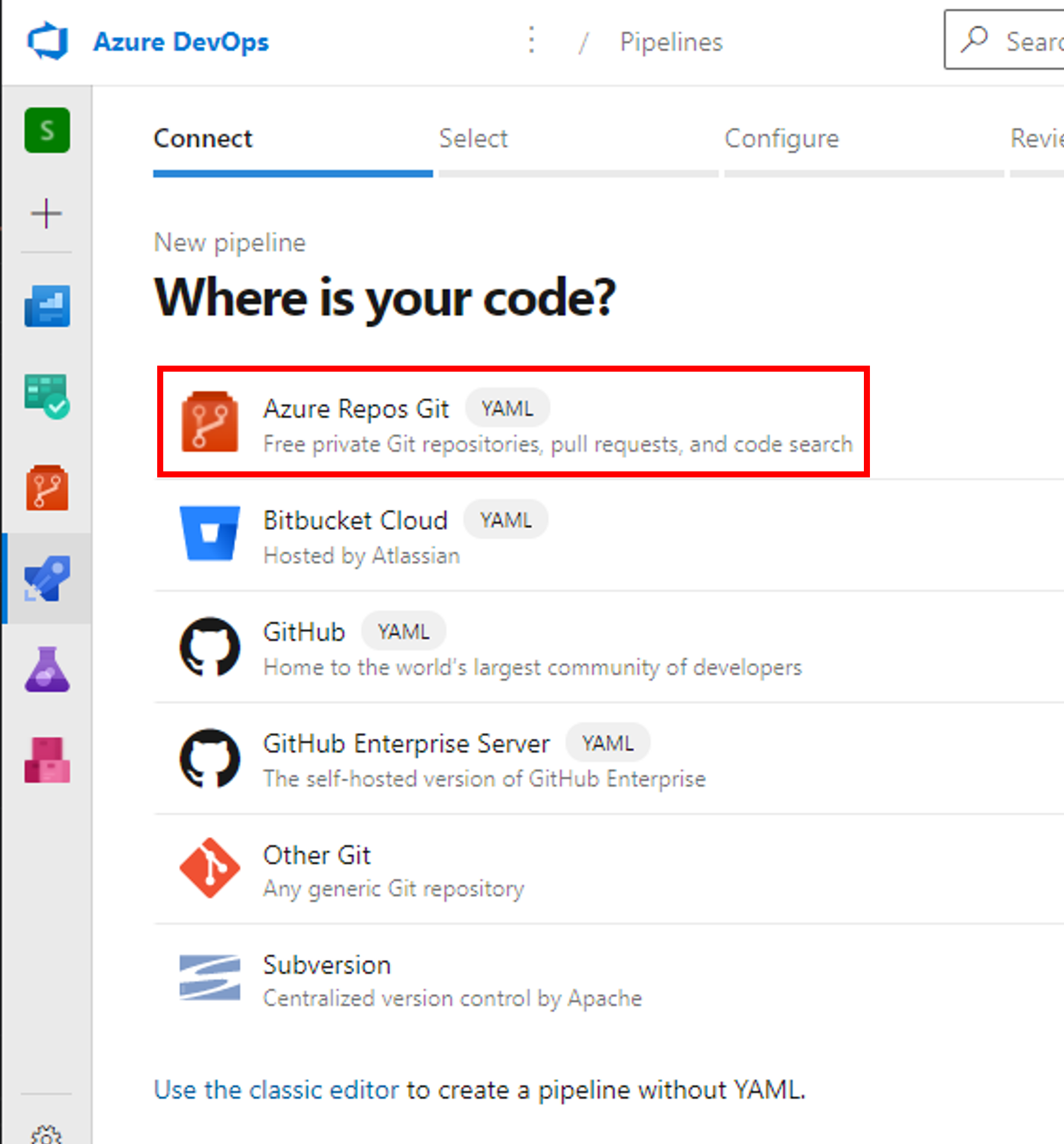
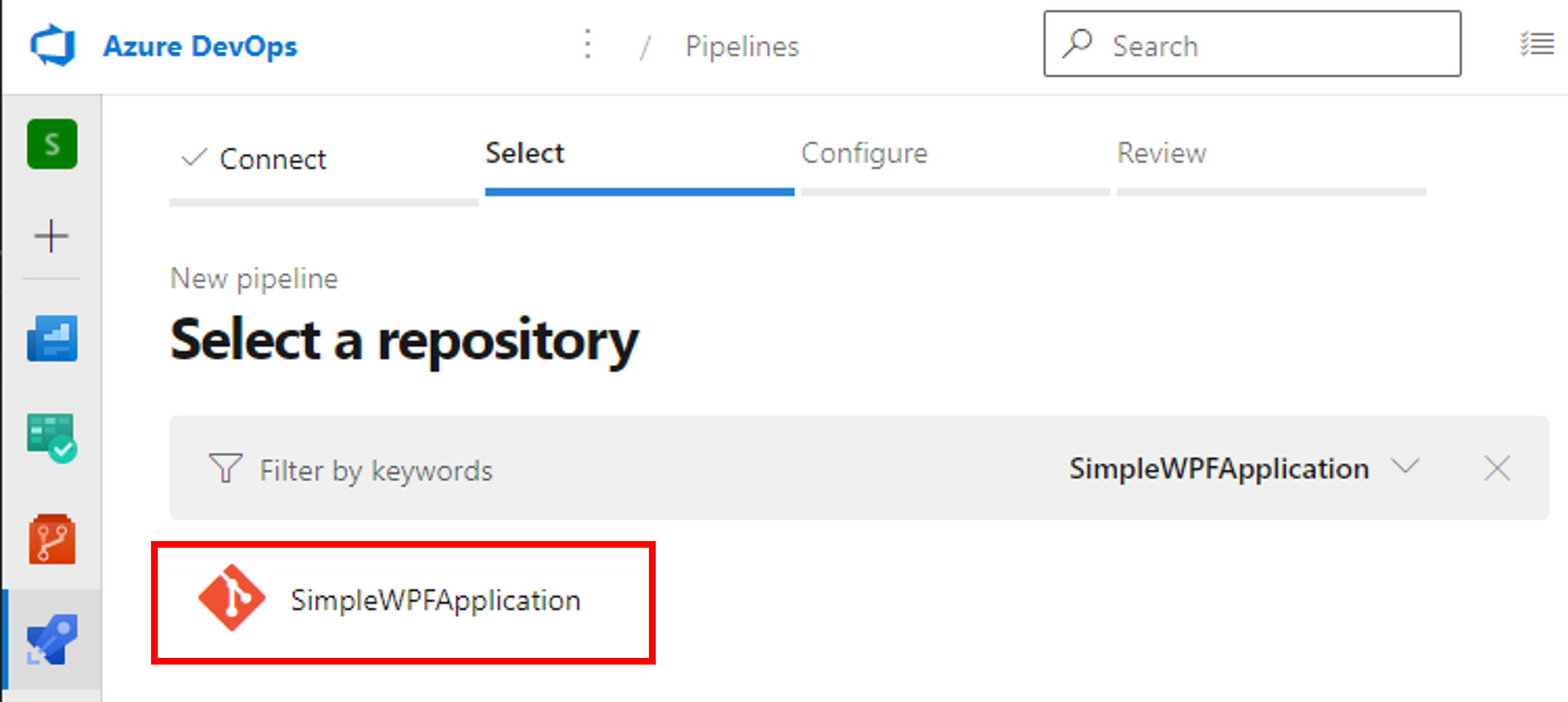
Azure DevOpsの自分の組織(Organization)のページを開き、 [+ New project] から新しいプロジェクトを作成します。 今回は [SimpleWPFApplication] という名前で作成しました。
public class MainWindowViewModel : BindableBase
{
...
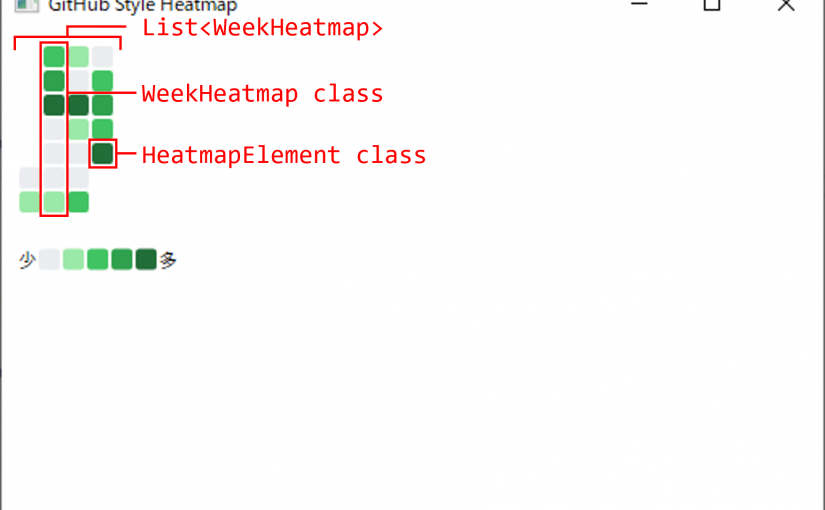
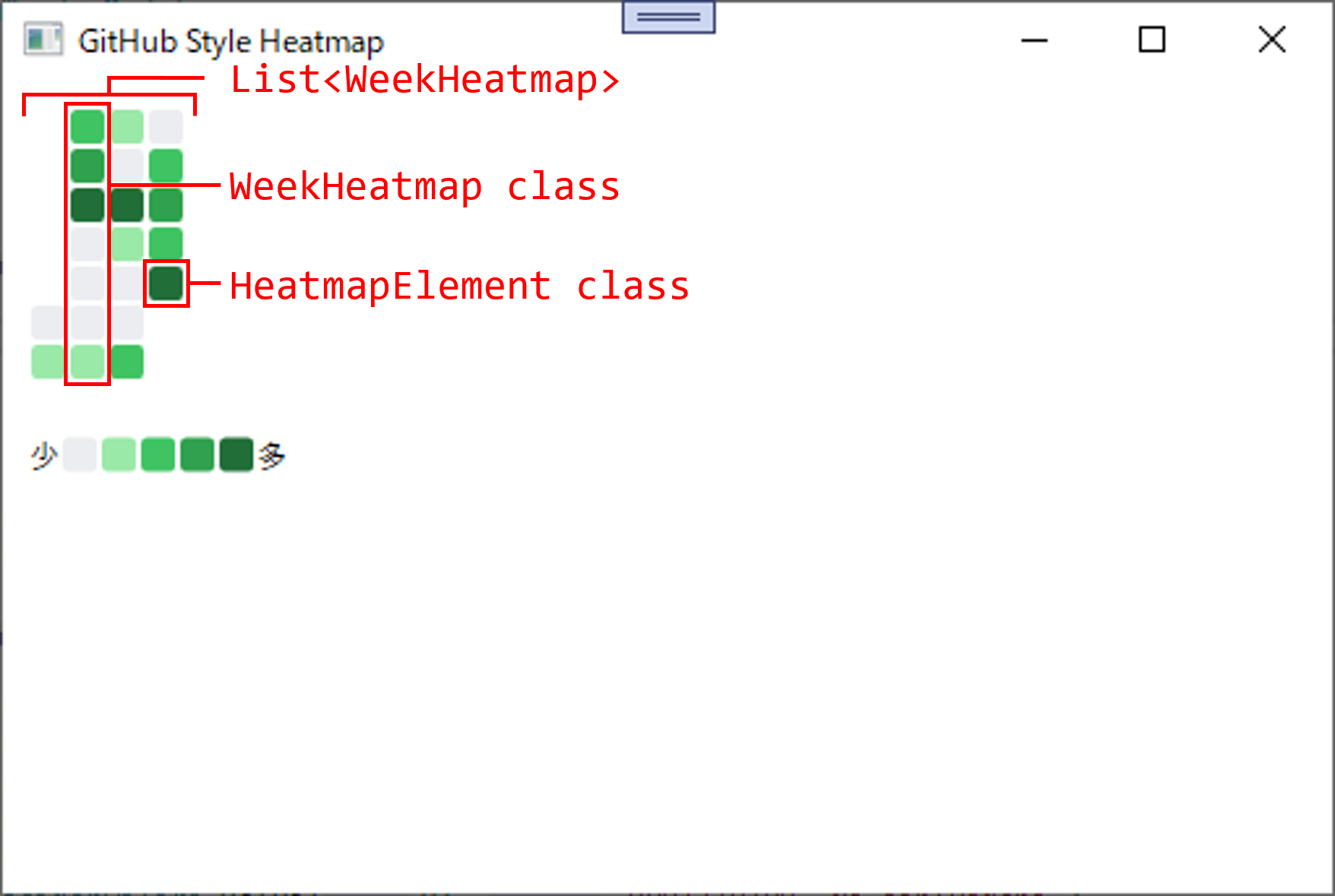
public List<WeekHeatmap> WeekHeatmaps { get; }
...
}
リストの型として使っているWeekHeatmapクラスと関連クラスは以下の通りです。
public class WeekHeatmap
{
public WeekHeatmap(List<HeatmapElement> heatmapElements)
{
if (heatmapElements.Count > 7) throw new ArgumentOutOfRangeException(nameof(heatmapElements), "ヒートマップの数が7を超えています。");
HeatmapElements = heatmapElements;
}
public List<HeatmapElement> HeatmapElements { get; }
}
public class HeatmapElement
{
public HeatmapElement(string color, string comment)
{
Color = color;
Comment = comment;
}
public string Color { get; }
public string Comment { get; }
}
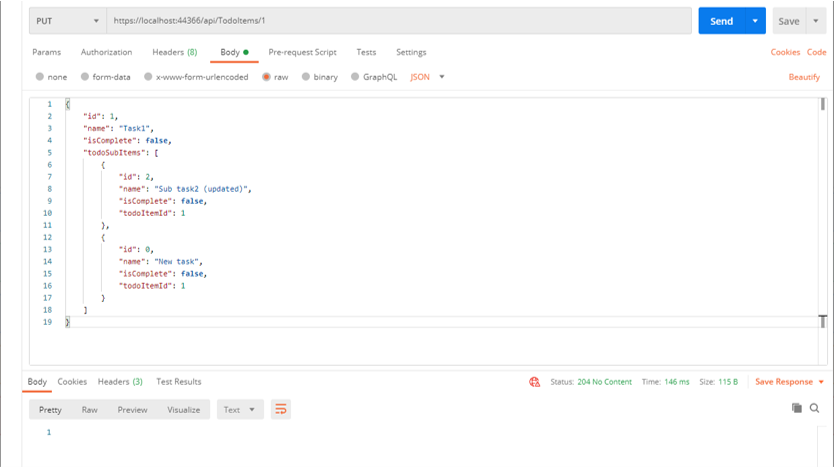
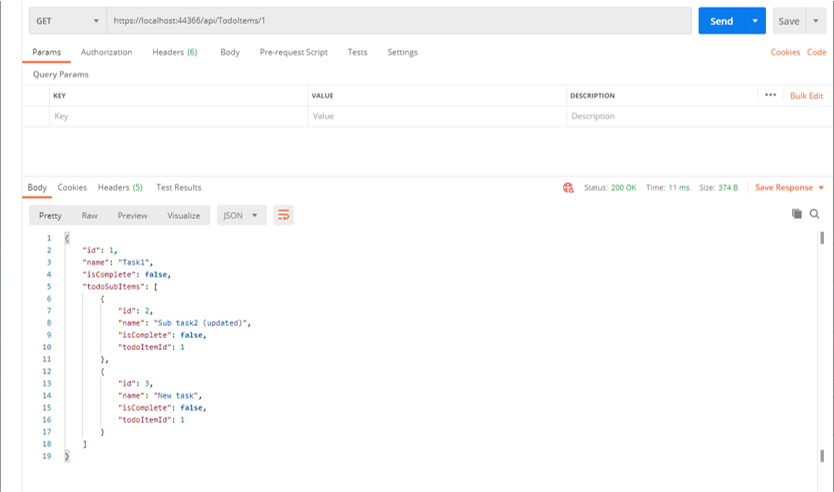
namespace TodoSubApi.Models
{
public class TodoItem
{
public long Id { get; set; }
public string Name { get; set; }
public bool IsComplete { get; set; }
public List<TodoSubItem> TodoSubItems { get; set; }
}
}
namespace TodoSubApi.Models
{
public class TodoSubItem
{
public long Id { get; set; }
public string Name { get; set; }
public bool IsComplete { get; set; }
public long TodoItemId { get; set; }
}
}
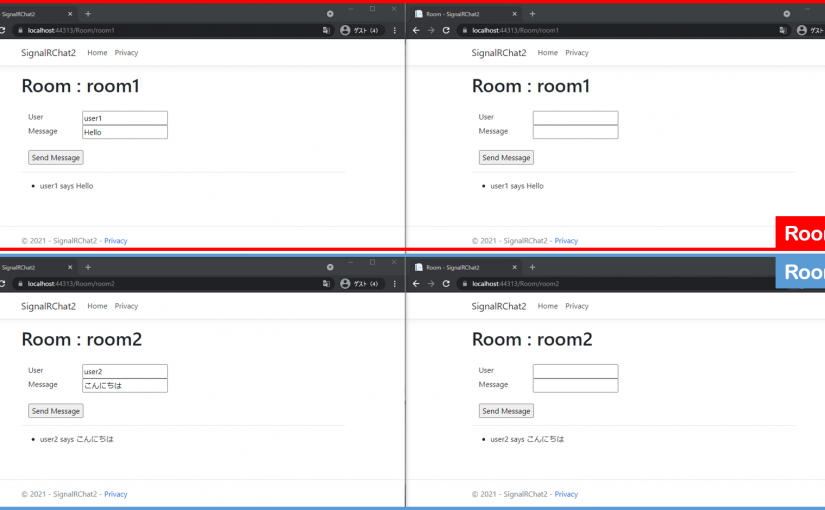
using Microsoft.AspNetCore.Mvc.RazorPages;
namespace SignalRGroupChat.Pages
{
public class RoomModel : PageModel
{
public string RoomName;
public void OnGet(string roomName)
{
RoomName = roomName;
}
}
}
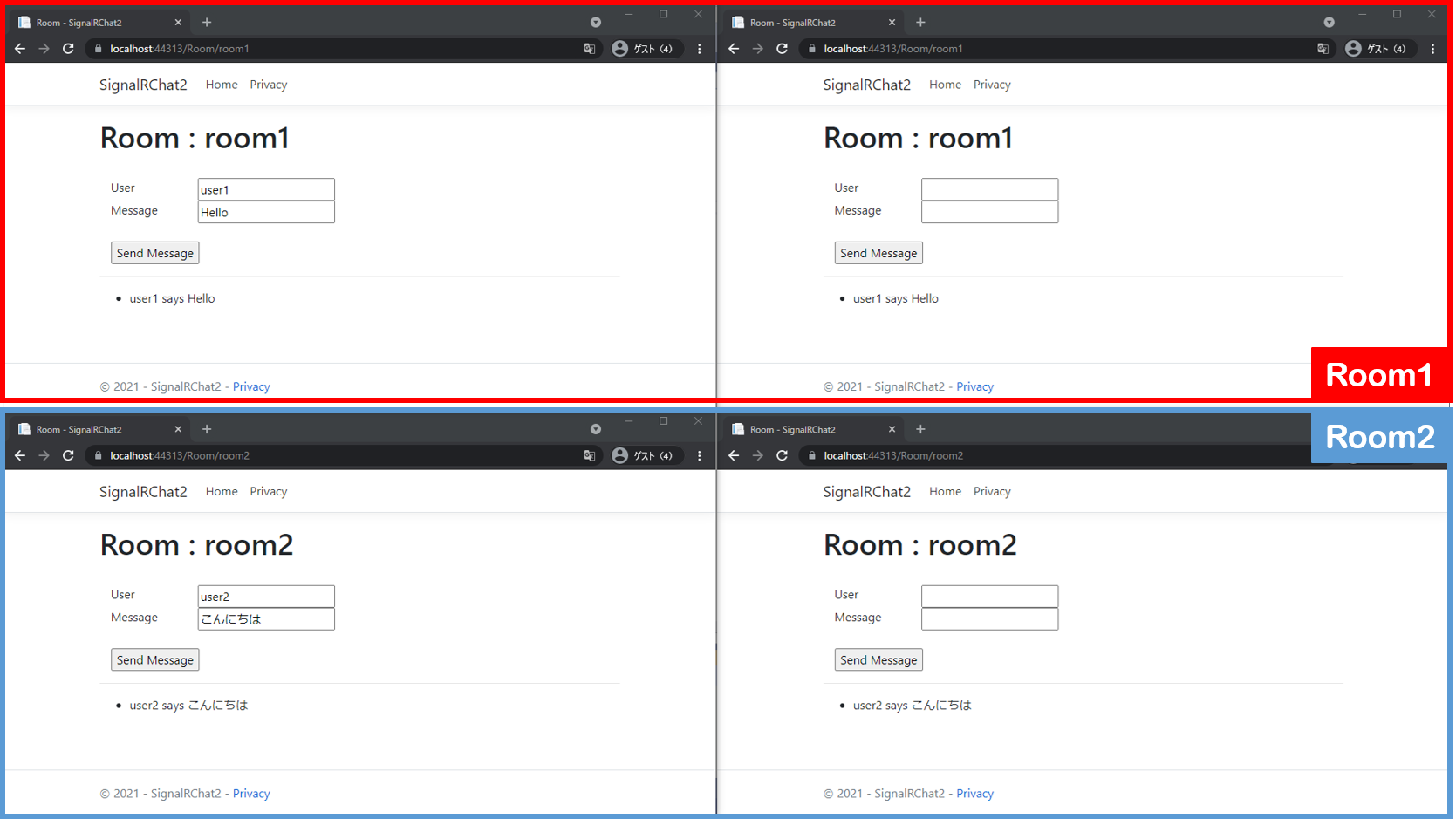
ちょっと説明
ここにはURLの末尾をルーム名として設定する処理を書いています。
wwwroot\js\chat.js を作成し、以下のように編集する
"use strict";
var connection = new signalR.HubConnectionBuilder().withUrl("/chatHub").build();
document.getElementById("sendButton").disabled = true;
connection.on("ReceiveMessage", function (user, message) {
var li = document.createElement("li");
document.getElementById("messagesList").appendChild(li);
li.textContent = `${user} says ${message}`;
});
connection.start().then(function () {
document.getElementById("sendButton").disabled = false;
var roomName = document.getElementById("roomName").value;
connection.invoke("AddToGroup", roomName).catch(function (err) {
return console.error(err.toString());
});
}).catch(function (err) {
return console.error(err.toString());
});
document.getElementById("sendButton").addEventListener("click", function (event) {
var roomName = document.getElementById("roomName").value;
var user = document.getElementById("userInput").value;
var message = document.getElementById("messageInput").value;
connection.invoke("SendMessageToGroup", roomName, user, message).catch(function (err) {
return console.error(err.toString());
});
event.preventDefault();
});
using AutoMapper;
using System;
namespace AutoMapperTest
{
class Program
{
static void Main(string[] args)
{
var config = new MapperConfiguration(cfg => cfg.CreateMap<Item, ItemDto>());
var mapper = config.CreateMapper();
var item = new Item(1, "商品1", 100);
ItemDto itemDto = mapper.Map<ItemDto>(item);
Console.WriteLine("Item:");
Console.WriteLine($"Id: {item.Id}, Name: {item.Name}, Price: {item.Price}");
Console.WriteLine("ItemDto:");
Console.WriteLine($"Id: {itemDto.Id}, Name: {itemDto.Name}, Price: {itemDto.Price}");
}
}
class Item
{
public Item(int id, string name, int price)
{
Id = id;
Name = name;
Price = price;
}
public int Id { get; }
public string Name { get; private set; }
public int Price { get; private set; }
}
class ItemDto
{
public ItemDto(Item item) : this(item.Id, item.Name, item.Price)
{
}
public ItemDto(int id, string name, int price)
{
Id = id;
Name = name;
Price = price;
}
public int Id { get; }
public string Name { get; }
public int Price { get; }
}
}
②setアクセサーを設定する
using AutoMapper;
using System;
namespace AutoMapperTest
{
class Program
{
static void Main(string[] args)
{
var config = new MapperConfiguration(cfg => cfg.CreateMap<Item, ItemDto>());
var mapper = config.CreateMapper();
var item = new Item(1, "商品1", 100);
ItemDto itemDto = mapper.Map<ItemDto>(item);
Console.WriteLine("Item:");
Console.WriteLine($"Id: {item.Id}, Name: {item.Name}, Price: {item.Price}");
Console.WriteLine("ItemDto:");
Console.WriteLine($"Id: {itemDto.Id}, Name: {itemDto.Name}, Price: {itemDto.Price}");
}
}
class Item
{
public Item(int id, string name, int price)
{
Id = id;
Name = name;
Price = price;
}
public int Id { get; }
public string Name { get; private set; }
public int Price { get; private set; }
}
class ItemDto
{
public int Id { get; set; }
public string Name { get; set; }
public int Price { get; set; }
}
}
③initアクセサーを使う
using AutoMapper;
using System;
namespace AutoMapperTest
{
class Program
{
static void Main(string[] args)
{
var config = new MapperConfiguration(cfg => cfg.CreateMap<Item, ItemDto>());
var mapper = config.CreateMapper();
var item = new Item(1, "商品1", 100);
ItemDto itemDto = mapper.Map<ItemDto>(item);
Console.WriteLine("Item:");
Console.WriteLine($"Id: {item.Id}, Name: {item.Name}, Price: {item.Price}");
Console.WriteLine("ItemDto:");
Console.WriteLine($"Id: {itemDto.Id}, Name: {itemDto.Name}, Price: {itemDto.Price}");
}
}
class Item
{
public Item(int id, string name, int price)
{
Id = id;
Name = name;
Price = price;
}
public int Id { get; }
public string Name { get; private set; }
public int Price { get; private set; }
}
class ItemDto
{
public int Id { get; init; }
public string Name { get; init; }
public int Price { get; init; }
}
}